If your AI startup fails, it is rarely because your model was weak. It is because your data backbone was fragile. You can build brilliant models and hire top engineers. But when messy real data, compliance rules, scaling pressure, and production drift hit you will see data failure first.
I have studied dozens of AI failures and what always breaks first is the pipeline, the cleaning, the versioning, the legal contracts, the monitoring. In this article, I lay out how data infrastructure separates winners from the corpses in AI startup land. I will use real numbers, real vendor examples, and links you can verify.
Why data infrastructure matters more than model tweaks
You have probably seen statistics like 95 percent of AI pilots fail to deliver measurable ROI. That is not fluff, that is real pain. The root causes are often data problems, not algorithmic issues.
In enterprise surveys 42 percent of companies reported that over half of their AI projects were delayed, underperformed or failed because data was not ready.
In generative AI rollouts, a recent
So when you read “AI failure rates” those big numbers almost always trace back to broken data. That is why infrastructure must be your first product.
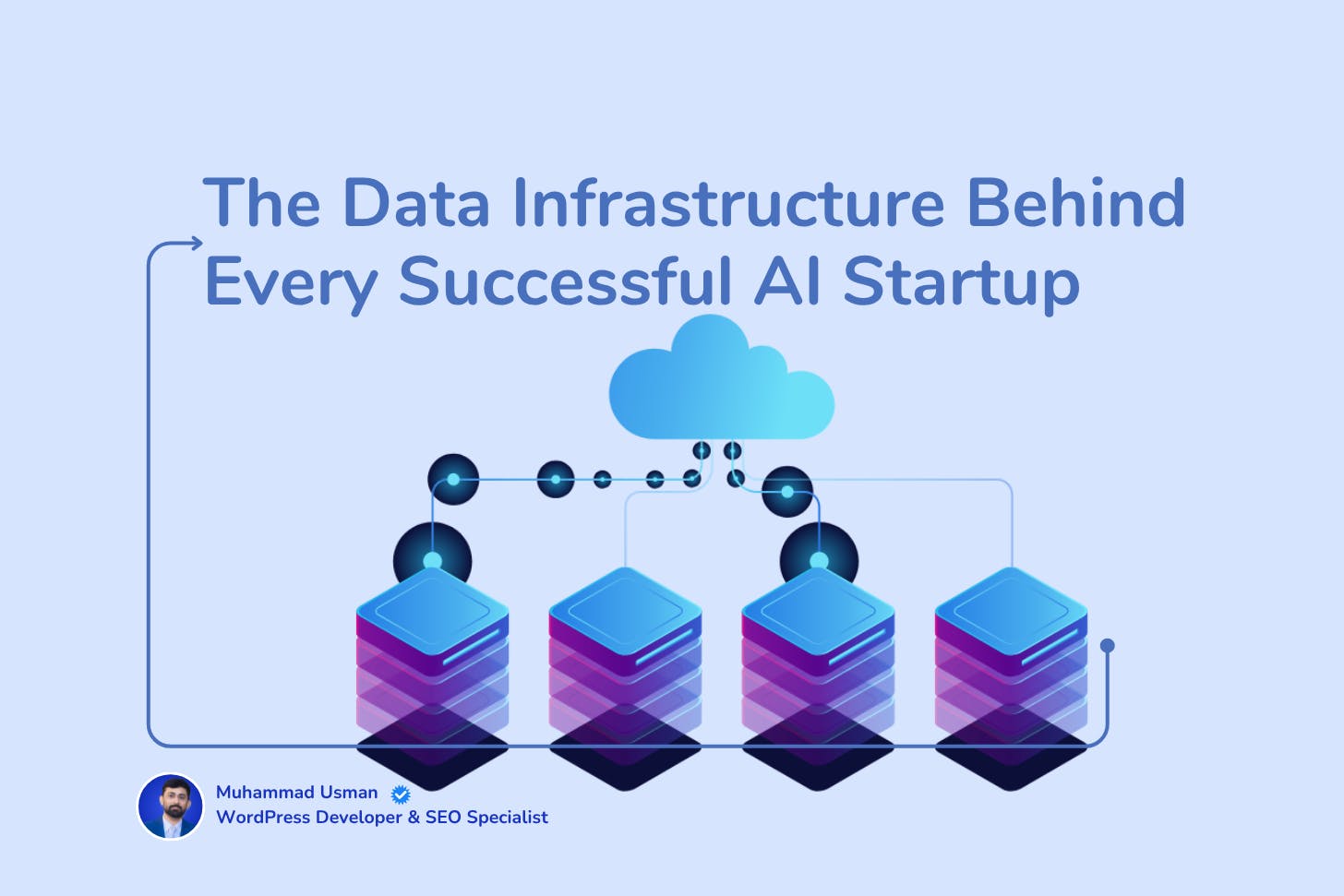
The architecture your AI startup must build
If you want to survive, you must get these layers right. Below, I describe them in the plainest terms I know.
Ingestion / Collection
You must harvest data from websites, partner APIs, internal logs, public sources. That requires scrapers, proxy networks, IP rotation, browser emulation, retry logic, error handling. Bright Data runs a network of 150 million+ residential proxies and advertises 99.99 percent uptime and 99.95 percent success rate for web extraction. (
Bright Data also offers a Web Unlocker API that handles CAPTCHAs, anti-bot measures, and headless browsing so you don’t have to reinvent that wheel. (Bright Data blog “AI-Ready Vector Datasets”)
Storage and Catalogs
Once your raw data arrives, you need to preserve it. Store a versioned immutable copy. Maintain a catalog with metadata, schemas, lineage, timestamps. You must always know which dataset version fed which model. Without that traceability, you will lose control.
Cleaning, normalization, transformation
Raw data is rarely usable. You need pipelines that drop outliers, unify formats, correct encoding, fill missing values, remove duplicates. Automation is critical. Manual scripts fail when scale grows.
Annotation and Labeling
Even cleaned data often needs labels. You need human-in-the-loop processes, validation, synthetic augmentation, few-shot corrections. That gives supervised signals and helps models learn beyond noise.
Feature stores & embeddings
You often turn content into features or embeddings. You need a store that version these features, map them to data instances, provide fast retrieval for training and inference.
Especially for RAG (retrieval augmented generation) workflows. Bright Data describes using embeddings with vector DBs like Pinecone in their vector dataset guide. (Bright Data blog “AI-Ready Vector Datasets”)
Also, their blog on vector databases explains how vector stores are central to modern AI. (Bright Data blog “
Training orchestration & model versioning
You must run scheduled fine-tuning, track models, support rollback, tie data version to model version, run experiments. If you lose version alignment, you'll get unexplainable behavior.
Serving / Inference optimization
Inference cost is your Achilles heel. You must use caching, batching, fallback logic, model blending (smaller models for common cases, bigger ones for hard queries). Serve only what you can afford.
Monitoring, drift detection, governance
You must monitor input distribution drift, concept drift, anomalies, performance degradation, fairness metrics. Your system must alert you when something drifts off. You need dashboards, logs, auditing.
Legal, compliance, licensing layer
Your data pipelines must obey law and contracts. You need user consent, license checks, privacy policies, data governance. If a data contract is broken or privacy law violated, your company dies.
Real proof and numbers
Below are concrete figures and vendor evidence you can cite.
- Bright Data’s homepage advertises 5+ billion records regularly refreshed across 120+ domains available via their Data Feeds API. (
Bright Data homepage ) - They state they host 150 million+ proxy IPs from 195 countries to support large-scale scraping. (
Bright Data homepage ) - Bright Data’s Dataset Marketplace offers the G2 dataset which includes structured product and review data, refreshed monthly, in JSON/CSV/Parquet formats. (Bright Data G2 Dataset page)
- Bright Data’s docs mention Deep Lookup, a service that lets you request granular dataset collections by query. (Bright Data FAQ Deep Lookup)
- Their “How to Scrape Financial Data” article shows that the Bright Data Financial Data Scraper API can extract structured financial fields like earnings estimates, historical prices, growth metrics automatically, with built-in proxy logic. (Bright Data blog “How to Scrape Financial Data”)
- Bright Data’s blog “How to Build an Agentic RAG” describes how they combine real-time web retrieval with vector databases and agents for live AI systems. (Bright Data blog “Build an Agentic RAG”)
These are not vague claims. These are features and numbers you can click through and verify.
How startups fail their data layers
Below are the patterns I see over and over again.
- They build scrapers ad hoc without monitoring. Then websites change and scraping fails regularly.
- They do cleaning logic manually, and it breaks on edge cases.
- They do not version data and lose track of which data caused which model behavior.
- They do not track inference cost or fallback logic. When traffic scales, cost spirals.
- They omit drift detection until too late, the model decays silently.
- They neglect compliance and licensing until they get legal pressure.
- They try to build every part from scratch instead of leveraging existing platforms.
These are fatal in AI startups. Not sexy, just real death.
Strategic play: how to use Bright Data in your stack
You should not merely mention Bright Data, you should use it strategically. Here is how.
Start by using prebuilt datasets to get early traction. For example, the G2 dataset gives you structured product and review data you can plug into early models.
Next use Bright Data’s Web Unlocker and proxy infrastructure to build custom ingestion pipelines without reinventing scraping logic.
In advanced stages, embed Bright Data’s Deep Lookup to let non-technical users query structured datasets without writing code.
Use their published pipeline guide on building AI-Ready Vector Datasets (Bright Data + Google Gemini + Pinecone) to form your embedding workflows.
As you scale, you can keep your own cleaning, versioning, monitoring layers in your control but rely on their infrastructure for heavy lifting.
In this way, your startup is not building the entire stack, but owning the differentiating glue and vision.
[story continues]
tags