



This is a Plain English Papers summary of a research paper called Kimi K2.5: Visual Agentic Intelligence. If you like these kinds of analysis, join AIModels.fyi or follow us on Twitter.
The single agent bottleneck
Most AI research follows a straightforward logic: to solve harder problems, make the model bigger. Train on more data. Run longer chains of thought. But there's something inefficient about this approach that mirrors a familiar human problem. A single expert tasked with everything—customer service, accounting, debugging—eventually hits a wall. No amount of additional training overcomes the fundamental constraint: one mind can only focus on one thing at a time.
This is where Kimi K2.5 begins. The researchers recognized that when complex tasks arrive, a single agent must serialize everything. Need to gather information, analyze visuals, and reason through logic? The agent does these sequentially, creating latency. Worse, forcing one model to master vision, reasoning, and coding spreads its capacity across competing demands. There's a structural inefficiency no amount of scaling can fix.
The insight is simpler than the solution: what if the AI system learned to split the work itself?
Vision and language as intertwined skills
Before introducing the paper's headline innovation, Kimi K2.5 establishes something foundational about how it thinks. Traditional approaches treat vision and language as separate modules that get connected at inference time, like assembling LEGO blocks from different sets. The architecture here is different.
Consider how humans learn. A child sees a dog and hears "dog" simultaneously, the modalities reinforcing each other. Kimi K2.5 applies this principle: vision and language pathways train together during pre-training, improving each other rather than simply coexisting. This joint optimization means the text decoder becomes better at understanding visual context, while the vision encoder learns to recognize what matters for language reasoning.
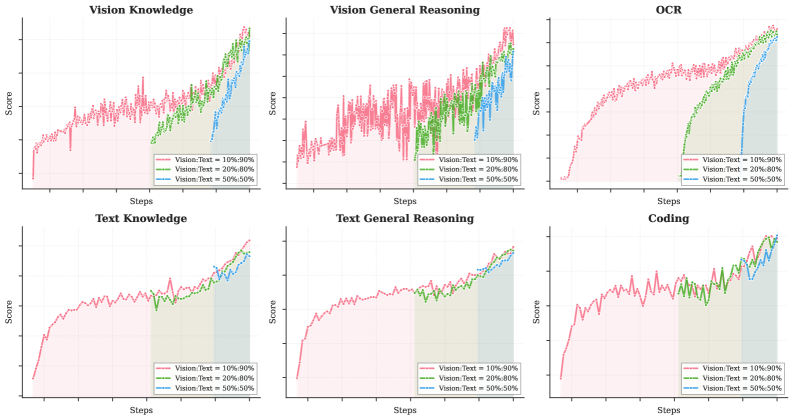
The paper tests different ratios of vision-to-text data during training. Surprisingly, the answer isn't "more vision data is always better." Figure 9 shows that early fusion with lower vision ratios tends to yield better results than aggressive vision-heavy training. The insight is subtle but important: balance during training produces better multimodal reasoning than maximizing one modality's data volume.
Learning curves comparing vision-to-text ratios (10:90, 20:80, 50:50) under fixed vision-text token budget across vision and language tasks. Early fusion with lower vision ratios tend to yield better results.
This foundation matters because what comes next depends on it. You cannot orchestrate agents that haven't learned to see and reason together. The vision improvements enable the architectural innovation ahead.
Reinforcement learning as a skill acquisition mechanism
The paper introduces "zero-vision SFT," a term that sounds technical but conceptually reveals something important about how visual understanding develops. The model starts with minimal vision capability, then learns vision through trial and error via reinforcement learning, receiving rewards for correct visual answers.
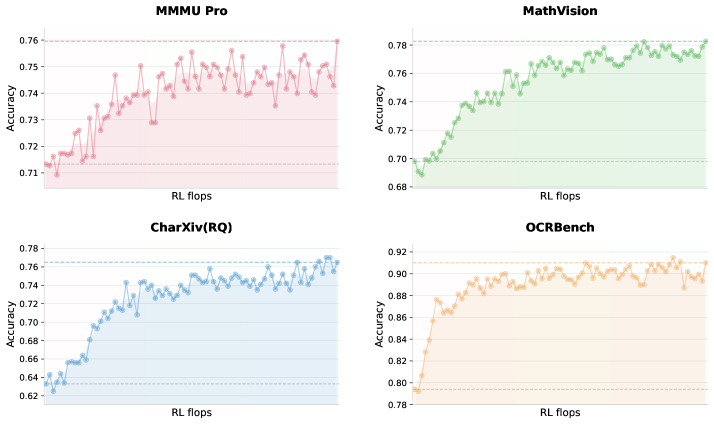
This is different from assuming vision understanding flows from data alone. Instead, vision becomes a learnable skill. Figure 2 shows the payoff: by scaling vision RL compute, performance continues improving. There's no plateau. More thinking time on visual problems yields better results, the same principle that works for language reasoning. Vision isn't a fixed module; it's a capability that grows through practice.
Vision RL training curves on vision benchmarks starting from minimal zero-vision SFT. By scaling vision RL FLOPs, the performance continues to improve, demonstrating that zero-vision activation paired with long-running RL is sufficient.
This observation sets up what follows. If individual agents can improve through RL in their specialties, then a swarm of specialized agents each running RL should be more efficient than a single generalist running RL on everything.
Agent swarm: orchestrated parallelism
The core innovation lives here. Imagine a tech lead managing a team facing a complex system outage. Instead of debugging everything sequentially, the lead decomposes the problem: "You check the database, you audit the API logs, you review recent deployments." These tasks run in parallel, and the lead synthesizes results. Agent Swarm follows this structure.
Rather than a static set of agent types, Kimi K2.5 includes a trainable orchestrator that dynamically creates specialized sub-agents and decomposes tasks contextually. The tension is real: how do you train the orchestrator to make good decomposition decisions? The answer uses reinforcement learning on orchestration itself. The system learns which decompositions work best through trial and error.
Figure 3 visualizes the architecture. There's a trainable orchestrator creating specialized frozen sub-agents dynamically. The orchestrator learns what decompositions maximize task success through RL. This is the "self-directed parallel agent orchestration" from the abstract made concrete.
An agent swarm has a trainable orchestrator that dynamically creates specialized frozen subagents and decomposes complex tasks into parallelizable subtasks for efficient distributed execution.
The orchestrator isn't a rule engine. It's a neural module trained end-to-end through RL to maximize overall task success. It learns that sometimes visual analysis and web search work in parallel, sometimes reasoning must wait for information gathering to complete. It learns context.
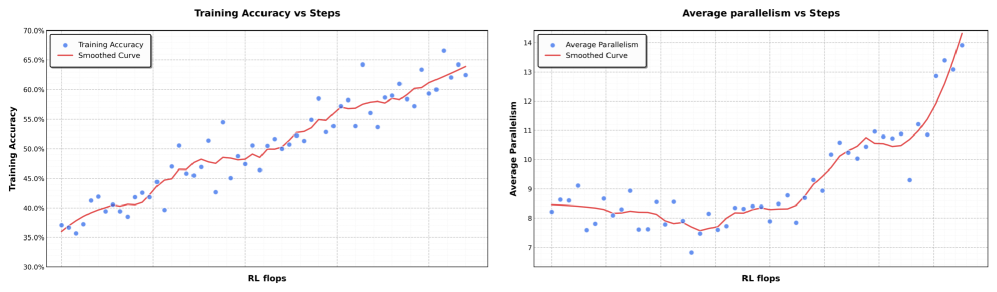
Figure 4 shows something elegant: as training progresses, the system learns to use more parallelism while maintaining accuracy. This isn't a tradeoff where you gain speed by sacrificing correctness. The optimal solution is the parallel solution. The system discovers that parallelism and accuracy align.
In the parallel-agent reinforcement learning environment, training accuracy increases smoothly as training progresses. At the same time, the level of parallelism during training also gradually increases.
Figure 6 shows the heterogeneity that emerges. The word cloud visualizes the different types of sub-agents the orchestrator instantiates during testing. This isn't a hand-coded taxonomy. The system has learned to create contextually appropriate specialists across diverse task types. The diversity demonstrates genuine flexibility.
The word cloud visualizes heterogeneous K2.5-based sub-agents dynamically instantiated by the Orchestrator across tests.
Practical coordination challenges
A naive parallel system can introduce overhead that outweighs parallelism benefits. Coordinating agents costs. The solution is that the orchestrator learns to create dependencies only when necessary and exploit parallelism when possible. This is why Figure 4 matters so much: the system doesn't blindly parallelize. It learns when parallelism is worthwhile.
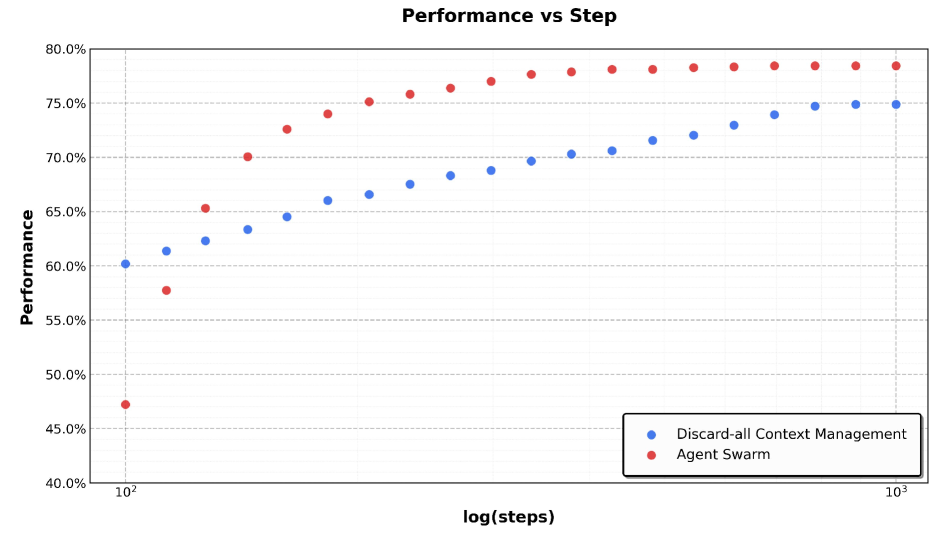
A concrete example illustrates this. In web browsing tasks (the BrowseComp benchmark), context management becomes a problem. A single agent handling 24 hours of continuous interaction creates massive context windows. Figure 7 shows that Agent Swarm's parallel decomposition handles this better than naive context management approaches. By decomposing across multiple specialized agents, the system avoids drowning in accumulated context while maintaining task performance.
Comparison of Kimi K2.5 performance under Agent Swarm and Discard-all context management in BrowseComp.
The results: where theory meets practice
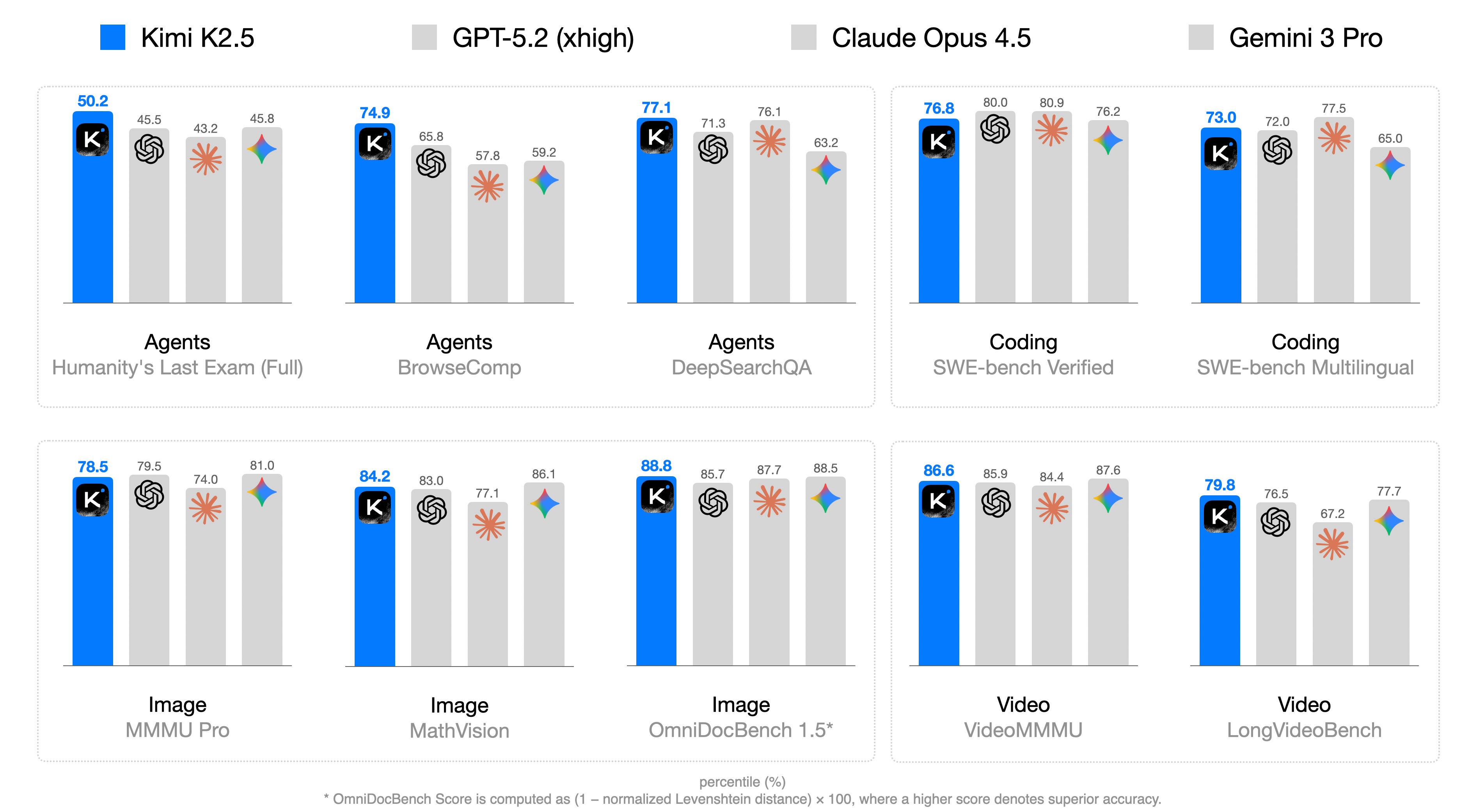
The intuition and architecture have been established. Now comes validation. Figure 1 shows the comprehensive results: Kimi K2.5 achieves state-of-the-art on coding, vision, reasoning, and agentic tasks. This isn't a narrow win in one domain but a pattern suggesting the approach is a general principle.
Kimi K2.5 main results across multiple benchmarks and tasks.
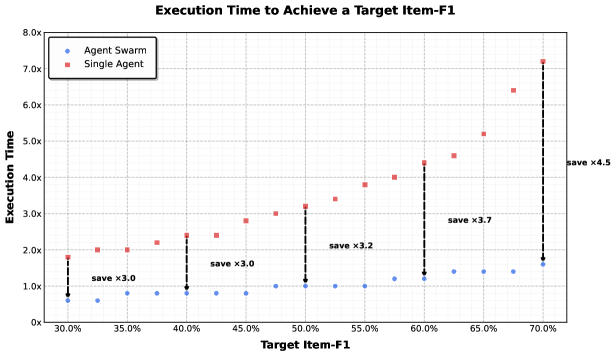
The speed advantage is substantial. Figure 8 shows Agent Swarm is 3 to 4.5 times faster than single-agent baselines as task difficulty increases. Crucially, this advantage grows with problem complexity. Harder problems benefit more from decomposition. This makes intuitive sense: complex problems have more opportunities for parallelization.
Agent Swarm achieves 3 to 4.5 times faster execution time compared to single-agent baselines as target Item-F1 increases from 30% to 70% in WideSearch testing.
These aren't just benchmark victories. They confirm what the architecture promised: specialization through learned decomposition yields both speed and accuracy. For skeptics wondering whether parallel agents would create coordination chaos, the data provides the answer.
Scaling to new possibilities
What does this architecture mean beyond benchmark scores? Agent Swarm sidesteps a false choice researchers have operated under: either make one model bigger and smarter, or use multiple weak agents with complex hand-coded coordination. The paper shows a third way: use RL to train the system how to decompose problems. This could become standard for complex reasoning and planning tasks, the way transformers became standard for sequence modeling.
Related work on configurable multi-agent systems and evaluating deep multimodal reasoning explores complementary directions. But the innovation here of learned orchestration, where the system discovers decomposition strategies through RL, represents a distinct approach to scaling agentic reasoning.
Figure 11 is instructive. Kimi K2.5 analyzes a complete 24-hour playthrough of Black Myth: Wukong across 32 videos at 1080p resolution using parallel visual agents. This isn't a benchmark result. It's demonstrating something practical: the system can now handle tasks of a scale and complexity that would be infeasible for a single agent. Sequential analysis of 24 hours of video would be orders of magnitude slower.
Qualitative example of Kimi K2.5 analyzing a complete playthrough of Black Myth: Wukong (24 hours of continuous gameplay across 32 videos at 1080p) using parallel visual agents.
Why this matters going forward
The paper opens with a structural limitation: single agents hit scaling walls in both speed and reasoning capacity. It resolves that tension by introducing a learned orchestration mechanism where decomposition strategy itself becomes trainable. The key insight, that systems can learn when and how to parallelize, feels almost obvious in retrospect. But the execution matters. Using RL to train the orchestrator end-to-end is the novelty that makes it work.
The results aren't just faster benchmarks. They suggest a path forward for building agentic AI systems that can handle real-world complexity. The work is released as open-source, inviting others to build on the foundation. This openness, combined with the generality of the approach across coding, vision, reasoning, and agentic tasks, positions Agent Swarm as a potential standard architecture for the next generation of AI systems.
The tension that opened this piece has been resolved not by making one agent smarter, but by letting systems learn when to think together.