
TL;DR —
Explore how training data subsets (9M, 90M tokens) influence the cross-entropy loss in Transformers, examining overfitting and the convergence behavior on test sets.
Table of Links
3 Model and 3.1 Associative memories
6 Empirical Results and 6.1 Empirical evaluation of the radius
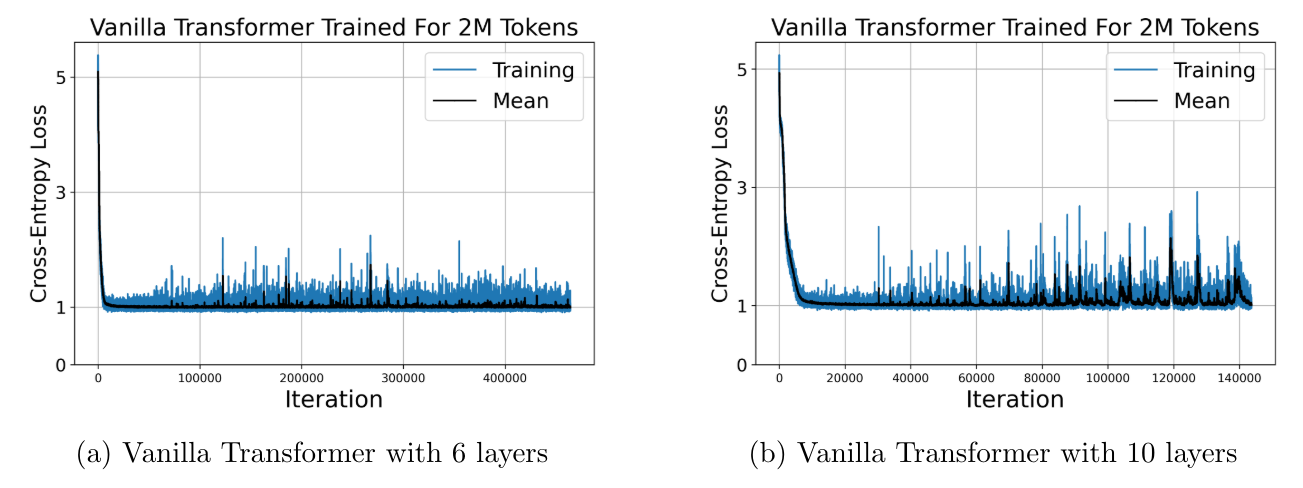
6.3 Training Vanilla Transformers
7 Conclusion and Acknowledgments
Appendix B. Some Properties of the Energy Functions
Appendix C. Deferred Proofs from Section 5
Appendix D. Transformer Details: Using GPT-2 as an Example
6.2 Training GPT-2


Authors:
(1) Xueyan Niu, Theory Laboratory, Central Research Institute, 2012 Laboratories, Huawei Technologies Co., Ltd.;
(2) Bo Bai baibo (8@huawei.com);
(3) Lei Deng (deng.lei2@huawei.com);
(4) Wei Han (harvey.hanwei@huawei.com).
This paper is
[story continues]
Written by
@reinforcement
Leading research and publication in advancing reinforcement machine learning, shaping intelligent systems & automation.
Topics and
tags
tags
transformer-models|associative-memory|hopfield-networks|model-generalization|attention-mechanism|cross-entropy-loss|model-scaling|neural-network-performance
This story on HackerNoon has a decentralized backup on Sia.
Transaction ID: g4KlmFPJkILdMVtKThfH6r9yMsyc5bygyikQzTeTdsQ