Table of Links
-
Our Proposed DiverGen
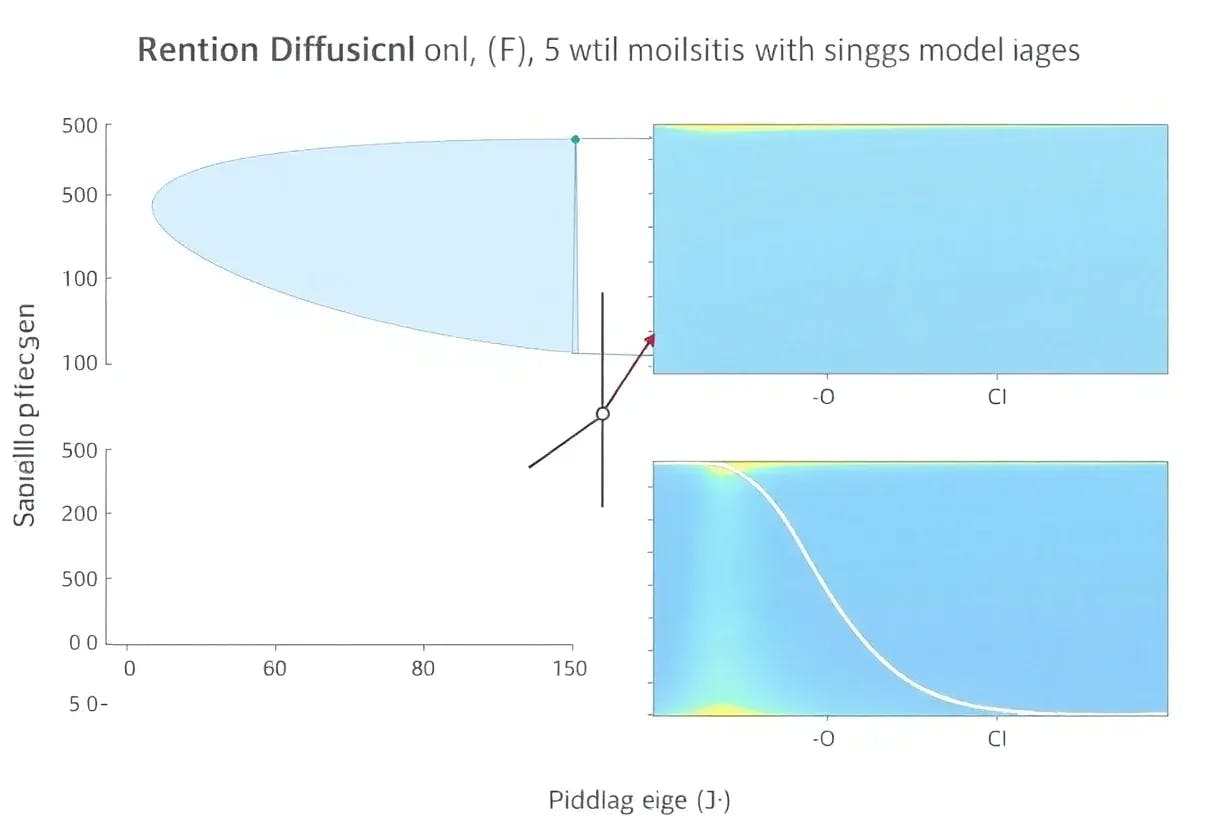
3.1. Analysis of Data Distribution
-
Experiments
Appendix
4.3. Ablation Studies
We analyze the effects of the proposed strategies in DiverGen through a series of ablation studies using the Swin-L [16] backbone.
Effect of category diversity. We select 50, 250, and 566 extra categories from ImagNet-1K [23], and generate 0.5k images for each category, which are added to the baseline. The baseline only uses 1,203 categories of LIVS [8] to generate data. We show the results in Table 5. Generally, increasing the number of extra categories initially improves then declines model performance, peaking at 250 extra categories. The trend suggests that using extra categories to enhance category diversity can improve the model’s generalization capabilities, but too many extra categories may mislead the model, leading to a decrease in performance.

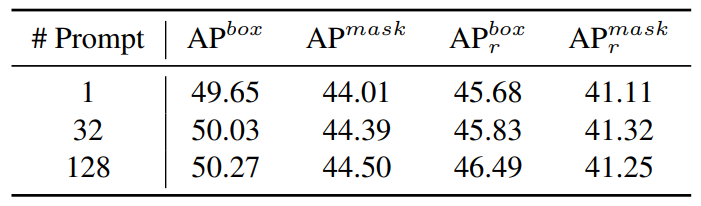
Effect of prompt diversity. We select a subset of categories and use ChatGPT to generate 32 and 128 prompts for each category, with each prompt being used to generate 8 and 2 images, respectively, ensuring that the image count for each category is 0.25k. The baseline uses only one prompt per category to generate 0.25k images. The regenerated images will replace the corresponding categories in the baseline to ensure that the final data scale is consistent. The results are presented in Table 6. With the increase in prompt diversity, there is a continuous improvement in model performance, indicating that prompt diversity is indeed beneficial for enhancing model performance.
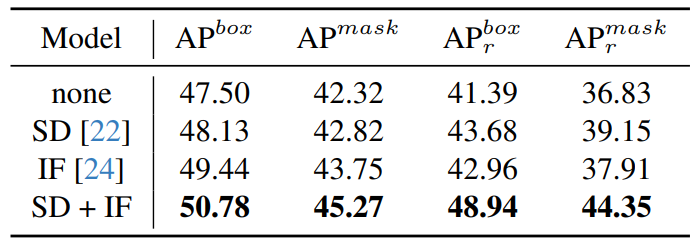
Effect of generative model diversity. We choose two commonly used generative models, Stable Diffusion [22] (SD) and DeepFloyd-IF [24] (IF). We generate 1k images per category for each generative model, totaling 1,200k. When using a mixed dataset (SD + IF), we take 600k from SD and 600k from IF per category, respectively, to ensure the total dataset scale is consistent. The baseline does not use any generative data (none). As shown in Table 7, using data generated by either SD or IF alone can improve performance, further mixing the generative data of both leads to significant performance gains. This demonstrates that increasing model diversity is beneficial for improving model performance.
Effect of annotation strategy. X-Paste [34] uses four models (U2Net [20], SelfReformer [31], UFO [25] and CLIPseg [17]) to generate masks and selects the one with the highest CLIP score. We compare our proposed annotation strategy (SAM-bg) to that proposed by X-Paste (max CLIP). In Table 8, SAM-bg outperforms max CLIP strategy across all metrics, indicating that our proposed strategy can produce better annotations, improving model performance. As shown in Figure 5, SAM-bg unlocks the potential capability of SAM, obtaining precise and refined masks.
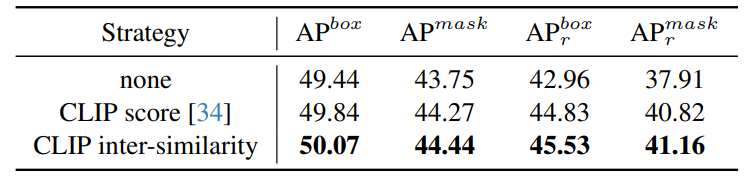
Effect of CLIP inter-similarity. We compare our proposed CLIP inter-similarity to CLIP score [34]. The results are shown in Table 9. The performance of data filtered by CLIP inter-similarity is higher than that of CLIP score, demonstrating that CLIP inter-similarity can filter low-quality images more effectively


5. Conclusions
In this paper, we explain the role of generative data augmentation from the perspective of data distribution discrepancies and find that generative data can expand the data distribution that the model can learn, mitigating overfitting the training set. Furthermore, we find that data diversity of generative data is crucial for improving model performance. Therefore, we design an efficient data diversity enhancement strategy, Generative Data Diversity Enhancement. We design various diversity enhancement strategies to increase data diversity from the aspects of category diversity, prompt diversity, and generative model diversity. Finally, we optimize the data generative pipeline by designing the annotation strategy SAM-background to obtain higher quality annotations and introducing the metric CLIP inter-similarity to filter data, which further improves the quality of the generative dataset. Through these designed strategies, our proposed method significantly outperforms the existing strong models. We hope DiverGen can provide new insights and inspirations for future research on the effectiveness and efficiency of generative data augmentation.
Acknowledgments
This work was in part supported by National Key R&D Program of China (No. 2022ZD0118700).
References
[1] David Arthur and Sergei Vassilvitskii. K-means++ the advantages of careful seeding. In Proc. Annual ACM-SIAM Symposium on Discrete algorithms, pages 1027–1035, 2007. 11
[2] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-toend object detection with transformers. In Proc. Eur. Conf. Comp. Vis. Springer, 2020. 1, 2
[3] Kai Chen, Enze Xie, Zhe Chen, Lanqing Hong, Zhenguo Li, and Dit-Yan Yeung. Integrating geometric control into text-to-image diffusion models for high-quality detection data generation via text prompt. arXiv: Comp. Res. Repository, 2023. 3
[4] Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexander Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 1290–1299, 2022. 1, 2
[5] Christiane Fellbaum. Wordnet. In Theory and applications of ontology: computer applications, pages 231–243. Springer, 2010. 4, 11
[6] Chun-Mei Feng, Kai Yu, Yong Liu, Salman Khan, and Wangmeng Zuo. Diverse data augmentation with diffusions for effective test-time prompt tuning. In Proc. IEEE Int. Conf. Comp. Vis., pages 2704–2714, 2023. 3
[7] Golnaz Ghiasi, Yin Cui, Aravind Srinivas, Rui Qian, TsungYi Lin, Ekin D. Cubuk, Quoc V. Le, and Barret Zoph. Simple copy-paste is a strong data augmentation method for instance segmentation. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 2918–2928, 2021. 7
[8] Agrim Gupta, Piotr Dollar, and Ross Girshick. Lvis: A dataset for large vocabulary instance segmentation. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 5356–5364, 2019. 1, 2, 3, 4, 5, 6, 7, 11
[9] Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross Gir- ´ shick. Mask r-cnn. In Proc. IEEE Int. Conf. Comp. Vis., pages 2961–2969, 2017. 1, 2
[10] KJ Joseph, Salman Khan, Fahad Shahbaz Khan, and Vineeth N Balasubramanian. Towards open world object detection. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 5830–5840, 2021. 3
[11] James M Joyce. Kullback-leibler divergence. In International Encyclopedia of Statistical Science, pages 720–722. Springer, 2011. 4
[12] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander Berg, Wan-Yen Lo, et al. Segment anything. In Proc. IEEE Int. Conf. Comp. Vis., pages 4015–4026, 2023. 1, 2, 5, 11
[13] Daiqing Li, Huan Ling, Seung Wook Kim, Karsten Kreis, Sanja Fidler, and Antonio Torralba. Bigdatasetgan: Synthesizing imagenet with pixel-wise annotations. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 21330–21340, 2022. 3
[14] Ziyi Li, Qinye Zhou, Xiaoyun Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Open-vocabulary object segmentation with diffusion models. In Proc. IEEE Int. Conf. Comp. Vis., pages 7667–7676, 2023. 3
[15] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollar, and C Lawrence ´ Zitnick. Microsoft coco: Common objects in context. In Proc. Eur. Conf. Comp. Vis., pages 740–755. Springer, 2014. 6
[16] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proc. IEEE Int. Conf. Comp. Vis., pages 10012–10022, 2021. 6, 7
[17] Timo Luddecke and Alexander Ecker. Image segmentation ¨ using text and image prompts. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 7086–7096, 2022. 8
[18] Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv: Comp. Res. Repository, 2018. 3, 11
[19] Maxime Oquab, Timothee Darcet, Th ´ eo Moutakanni, Huy Vo, ´ Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. Trans. Mach. Learn. Research, 2023. 12
[20] Xuebin Qin, Zichen Zhang, Chenyang Huang, Masood Dehghan, Osmar R Zaiane, and Martin Jagersand. U2-net: Going deeper with nested u-structure for salient object detection. Pattern Recognition, 106:107404, 2020. 8
[21] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In Proc. Int. Conf. Mach. Learn., pages 8748–8763. PMLR, 2021. 2, 3, 5, 11, 12
[22] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bjorn Ommer. High-resolution image synthesis with latent diffusion models. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 10684–10695, 2022. 1, 2, 3, 5, 8, 11
[23] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vision, 115: 211–252, 2015. 2, 4, 5, 7, 11
[24] Alex Shonenkov, Misha Konstantinov, Daria Bakshandaeva, Christoph Schuhmann, Ksenia Ivanova, and Nadiia Klokova. Deepfloyd-if, 2023. 1, 2, 3, 5, 6, 8, 11
[25] Yukun Su, Jingliang Deng, Ruizhou Sun, Guosheng Lin, Hanjing Su, and Qingyao Wu. A unified transformer framework for group-based segmentation: Co-segmentation, co-saliency detection and video salient object detection. IEEE Trans. Multimedia, 2023. 8
[26] Jingru Tan, Gang Zhang, Hanming Deng, Changbao Wang, Lewei Lu, Quanquan Li, and Jifeng Dai. 1st place solution of LVIS challenge 2020: A good box is not a guarantee of a good mask. arXiv: Comp. Res. Repository, 2020. 7
[27] Weijia Wu, Yuzhong Zhao, Hao Chen, Yuchao Gu, Rui Zhao, Yefei He, Hong Zhou, Mike Zheng Shou, and Chunhua Shen. DatasetDM: Synthesizing data with perception annotations using diffusion models. Proc. Advances in Neural Inf. Process. Syst., 2023. 1, 3
[28] Weijia Wu, Yuzhong Zhao, Mike Zheng Shou, Hong Zhou, and Chunhua Shen. Diffumask: Synthesizing images with pixel-level annotations for semantic segmentation using diffusion models. Proc. IEEE Int. Conf. Comp. Vis., 2023. 1, 3
[29] Jiahao Xie, Wei Li, Xiangtai Li, Ziwei Liu, Yew Soon Ong, and Chen Change Loy. Mosaicfusion: Diffusion models as data augmenters for large vocabulary instance segmentation. arXiv: Comp. Res. Repository, 2023. 3
[30] Lihe Yang, Xiaogang Xu, Bingyi Kang, Yinghuan Shi, and Hengshuang Zhao. FreeMask: Synthetic images with dense annotations make stronger segmentation models. Proc. Advances in Neural Inf. Process. Syst., 2023. 3
[31] Yi Ke Yun and Weisi Lin. Selfreformer: Self-refined network with transformer for salient object detection. arXiv: Comp. Res. Repository, 2022. 8
[32] Renrui Zhang, Xiangfei Hu, Bohao Li, Siyuan Huang, Hanqiu Deng, Yu Qiao, Peng Gao, and Hongsheng Li. Prompt, generate, then cache: Cascade of foundation models makes strong few-shot learners. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 15211–15222, 2023. 3
[33] Yuxuan Zhang, Huan Ling, Jun Gao, Kangxue Yin, JeanFrancois Lafleche, Adela Barriuso, Antonio Torralba, and Sanja Fidler. Datasetgan: Efficient labeled data factory with minimal human effort. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 10145–10155, 2021. 3
[34] Hanqing Zhao, Dianmo Sheng, Jianmin Bao, Dongdong Chen, Dong Chen, Fang Wen, Lu Yuan, Ce Liu, Wenbo Zhou, Qi Chu, Weiming Zhang, and Nenghai Yu. X-paste: Revisiting scalable copy-paste for instance segmentation using CLIP and stablediffusion. Proc. Int. Conf. Mach. Learn., 2023. 1, 2, 3, 4, 5, 6, 7, 8, 12, 13
[35] Xingyi Zhou, Vladlen Koltun, and Philipp Krahenbuhl. Probabilistic two-stage detection. arXiv: Comp. Res. Repository, 2021. 6, 7
[36] Xingyi Zhou, Rohit Girdhar, Armand Joulin, Philipp Krahenbuhl, and Ishan Misra. Detecting twenty-thousand ¨ classes using image-level supervision. In Proc. Eur. Conf. Comp. Vis., pages 350–368. Springer, 2022. 7
Authors:
(1) Chengxiang Fan, with equal contribution from Zhejiang University, China;
(2) Muzhi Zhu, with equal contribution from Zhejiang University, China;
(3) Hao Chen, Zhejiang University, China (haochen.cad@zju.edu.cn);
(4) Yang Liu, Zhejiang University, China;
(5) Weijia Wu, Zhejiang University, China;
(6) Huaqi Zhang, vivo Mobile Communication Co..
(7) Chunhua Shen, Zhejiang University, China (chunhuashen@zju.edu.cn).
This paper is
[story continues]
tags