Table of Links
2 Approach
2.2 Multimodal Instruction Finetuning
2.3 Curriculum Learning with Parameter Efficient Finetuning
4 Results
4.1 Evaluation of SpeechVerse models
4.2 Generalization Across Instructions
4.3 Strategies for Improving Performance
6 Conclusion, Limitations, Ethics Statement, and References
A Appendix
A.1 Audio Encoder Pre-training
2.1 Architecture
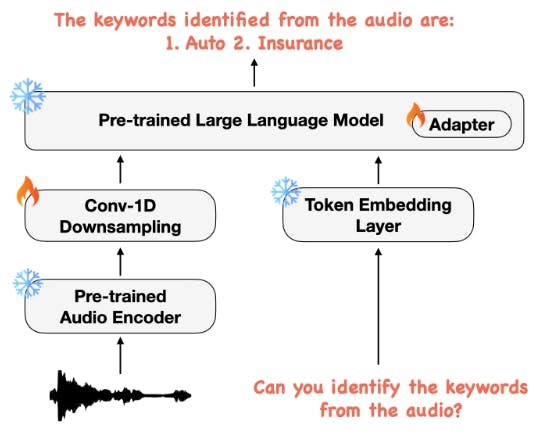
As shown in Figure 2, our multimodal model architecture consists of three main components: (1) a pre-trained audio encoder to encode an audio signal into a feature sequence, (2) a 1-D convolution module that operates over the audio feature sequence to abbreviate the sequence length, and (3) a pre-trained LLM to use these audio features and textual instructions to perform the required task. Details of each of these sub-systems are described below.

2.2 Multimodal Instruction Finetuning

2.3 Curriculum Learning with Parameter Efficient Finetuning

In the first stage, we only train the convolution downsampling module and the intermediate layer weights without introducing the LoRA adapters. Further, only the samples from the automatic speech recognition (ASR) task are used in this stage. Since the encoded speech feature vectors can be very different from the token embeddings of the text input, this stage can help align them more easily in a common embedding space by only learning the parameters for the convolution downsampling module in the confined task space of ASR. This enables a pre-trained text-based LLM to attend to the content of the audio sequence and generate the speech transcription.
In the second stage, we now introduce the LoRA adapters for training the model. In this stage, the intermediate layer weights, the downsampling module as well as the LoRA adapters are unfrozen. Since the LoRA adapters are training from scratch, we first allow the adapter weights to warmup by training only on the ASR task, so as to get aligned to the common embedding space learned by the convolution downsampling module in the first stage. Finally, we introduce additional tasks on top of the ASR task and continue training while keeping the pre-trained audio encoder and LLM weights frozen. Since the warmup using only the ASR task enables the model to understand the contents of
the audio, our curriculum learning approach leads to faster convergence on a variety of speech-based tasks that rely on the spoken contents of the audio.
Authors:
(1) Nilaksh Das, AWS AI Labs, Amazon and Equal Contributions;
(2) Saket Dingliwal, AWS AI Labs, Amazon(skdin@amazon.com);
(3) Srikanth Ronanki, AWS AI Labs, Amazon;
(4) Rohit Paturi, AWS AI Labs, Amazon;
(5) Zhaocheng Huang, AWS AI Labs, Amazon;
(6) Prashant Mathur, AWS AI Labs, Amazon;
(7) Jie Yuan, AWS AI Labs, Amazon;
(8) Dhanush Bekal, AWS AI Labs, Amazon;
(9) Xing Niu, AWS AI Labs, Amazon;
(10) Sai Muralidhar Jayanthi, AWS AI Labs, Amazon;
(11) Xilai Li, AWS AI Labs, Amazon;
(12) Karel Mundnich, AWS AI Labs, Amazon;
(13) Monica Sunkara, AWS AI Labs, Amazon;
(14) Daniel Garcia-Romero, AWS AI Labs, Amazon;
(15) Kyu J. Han, AWS AI Labs, Amazon;
(16) Katrin Kirchhoff, AWS AI Labs, Amazon.
This paper is
[story continues]
tags