Over the past two years, I've watched the enterprise AI conversation evolve in distinct, accelerating waves. First, everyone wanted access to large language models — executives were racing to demo ChatGPT integrations in board meetings, and engineering teams were experimenting with prompt engineering like it was the new SQL. Then came the builder wave: we started constructing agents, wiring models to tools, databases, and APIs, watching them reason through multi-step tasks in ways that felt genuinely new.
Now we're asking a more important question — one that doesn't show up in benchmarks or product demos, but that will determine which organizations actually succeed with AI at scale:
How do we control what these systems are actually allowed to do?
That shift — from intelligence to governance — is where guardrails stop being a technical detail and start being a strategic asset. And they don't all look the same. In fact, they've evolved across three distinct architectural stages, each with fundamentally different risk profiles, failure modes, and design requirements.
Understanding where your organization sits on this maturity curve isn't just an academic exercise. It's the difference between deploying AI confidently and deploying AI recklessly — and hoping nothing breaks.
Why Guardrails Became Strategic
There's a tendency in engineering culture to treat guardrails as a constraint — something bolted on after the real work is done, a compliance checkbox dressed up as architecture. That framing made sense when AI was primarily a content generation tool. If the model says something it shouldn't, filter it out. Problem solved.
But that mental model breaks down the moment AI systems start doing things. Sending emails. Querying databases. Updating records. Triggering workflows. Calling external APIs. At that point, a guardrail isn't just a content policy — it's an authorization layer. And authorization layers, if you've worked in enterprise software for any length of time, are the foundation everything else is built on.
The organizations that treat guardrails as strategic — that build them into their architecture from the beginning rather than retrofitting them after an incident — are going to have a structural advantage in the AI era. Not because they'll be safer (though they will be), but because they'll be able to move faster. Trust infrastructure enables deployment at scale. The absence of it creates a ceiling.
Here's how that evolution looks across three stages.
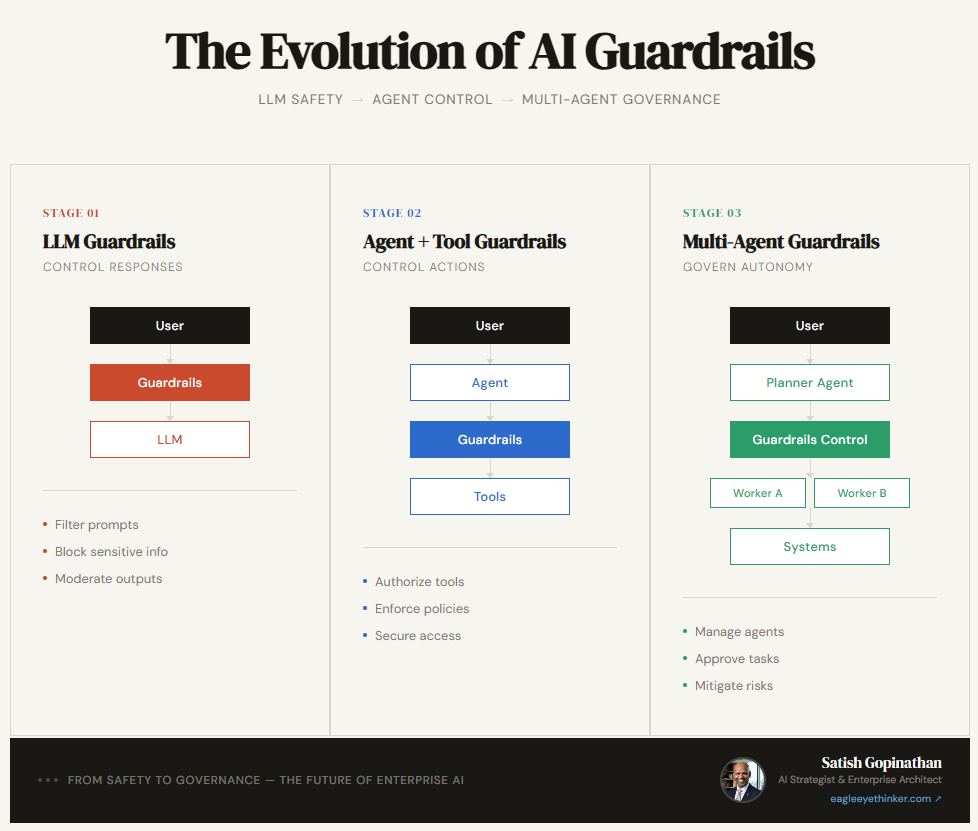
Stage 1 — LLM Guardrails: Control What AI Says
Most organizations begin here, and for good reason. When you're first integrating an LLM into a product or workflow, the primary risk is at the conversation layer: the model generates content you don't want, can't defend, or that violates regulatory requirements.
The pattern is conceptually simple:
User → Guardrails → LLM → Response
In practice, this means:
- Input filtering: Detecting and blocking sensitive topics, jailbreak attempts, prompt injection, or content outside defined scope before they reach the model.
- Output moderation: Scanning responses for harmful content, PII, hallucinated facts, or brand-unsafe language before they reach the user.
- Topic restrictions: Preventing the model from engaging with subjects outside its defined purpose — keeping a customer service bot from opining on politics, for example.
This layer protects brand reputation. It keeps you on the right side of compliance. It's the foundation of responsible deployment, and skipping it is genuinely reckless. But it's important to understand what it doesn't do.
Stage 1 guardrails govern a conversation. They say nothing about what the AI is doing. They operate entirely at the language layer — catching what the model says, not what it executes. If your AI is only generating text responses for human review, Stage 1 may be sufficient. But most enterprise AI journeys don't stop there.
This is communication safety. Not execution governance. The difference matters enormously.
Common failure mode at Stage 1: Organizations assume that because they have content filtering in place, they have "AI guardrails." When they add tool use or agentic capability, they carry that assumption forward into a context where it no longer holds — and the risk exposure they think they've managed is actually wide open.
Stage 2 — Agent Guardrails: Control What AI Does
When AI becomes an agent — when it can take actions in the world rather than just generate text — the risk profile changes entirely. This isn't an incremental shift. It's a categorical one.
Consider what an agent can do that an LLM conversation cannot:
- Call external APIs (payment processing, CRM updates, order management)
- Send emails or Slack messages on behalf of users
- Read and write to databases containing sensitive customer data
- Trigger automation workflows with downstream consequences
- Query internal systems across organizational boundaries
Each of these actions has real-world consequences that persist beyond the conversation. A poorly governed agent doesn't just say the wrong thing — it does the wrong thing. And undoing it may be difficult, expensive, or in some cases, impossible.
The architecture evolves to reflect this new reality:
User → Agent (LLM decides tool) → Guardrails Policy → Tool Execution → External System
Notice what's different. The guardrail is no longer at the front door, filtering what goes in and comes out. It's sitting between the agent's decision and the tool's execution — evaluating every action before it happens.
This is where enterprise architecture concepts that have governed software systems for decades suddenly become essential to AI governance:
Role-based authorization. Not every user should be able to invoke every tool. An agent helping a sales rep shouldn't have the same access to customer financial records as an agent supporting a finance analyst. Your AI authorization model needs to map to your organizational access model — and that mapping needs to be enforced at runtime, not assumed.
Policy enforcement at the tool layer. Each tool call needs a policy decision: Is this user authorized to invoke this tool? Does this request fall within defined parameters? Does the data being accessed or modified comply with applicable policies? These decisions need to be made consistently, at scale, and in real time.
Audit trails and explainability. When an agent takes an action — especially a consequential one — you need to know what it did, why it decided to do it, and what guardrail evaluation it passed or failed. This isn't optional for regulated industries. It's increasingly a baseline expectation.
Constraint boundaries. Beyond authorization, agents need hard limits: rate limits on how often certain actions can be taken, value thresholds on financial transactions, geographic or organizational scope restrictions on data access. These constraints often live outside the model itself — they need to be enforced by the guardrail layer regardless of what the LLM decides.
This is the stage where most organizations currently find themselves — or aspire to be. The technical sophistication required increases significantly, but the payoff is proportional: an agent governed by robust Stage 2 guardrails is one you can actually trust to handle real workflows with meaningful stakes.
Common failure mode at Stage 2: Building agent-specific guardrails that don't compose. Each team builds their own policy enforcement for their own tools, and the result is inconsistent governance across the organization — different rules for different agents, gaps at integration points, and no unified view of what your AI systems are actually authorized to do.
Stage 3 — Multi-Agent Guardrails: Govern Autonomy at Scale
The next wave is already here, and the organizations that are ahead of the curve are already grappling with its governance implications.
Multi-agent systems — where specialized agents collaborate, delegate, and orchestrate one another to accomplish complex tasks — represent a qualitative leap in AI capability. A planner agent breaks down a complex business objective and routes subtasks to specialized worker agents: one for data retrieval, one for analysis, one for communication, one for system updates. Those worker agents may themselves call other tools, spawn sub-agents, or trigger workflows that span organizational boundaries.
The architecture looks something like this:
User → Planner Agent → Guardrails Control Plane → Worker Agents → Enterprise Systems
↑ ↓
Policy Store & Audit Log Tool Execution Layer
Governing this kind of system requires something that Stage 1 and Stage 2 guardrails were never designed to provide: a shared governance plane that spans the entire agent ecosystem.
Here's what makes multi-agent governance uniquely challenging:
Agent-to-agent trust. When a planner agent instructs a worker agent to take an action, what authorization does that instruction carry? Does the worker inherit the planner's permissions? The originating user's permissions? Its own defined permissions? These questions don't have obvious answers, and the wrong defaults create serious vulnerabilities. A malicious or misconfigured planner could instruct workers to take actions far outside the scope of what any individual user is authorized to request.
Cross-workflow policy consistency. In a multi-agent system, a single user request may fan out into dozens of downstream actions across multiple agents and systems. Ensuring that a policy applied at the planner level propagates correctly to every downstream execution is non-trivial — especially when agents are built by different teams, deployed on different timelines, and integrated with different external systems.
Dynamic routing and emergent behavior. Multi-agent systems are often designed to be adaptive — the planner decides which worker to invoke based on context. This dynamism is a feature, but it creates governance surface area that static rule sets can't fully anticipate. Your governance layer needs to be able to evaluate policy against dynamic execution graphs, not just predefined workflows.
Risk-aware execution decisions. Not every action has the same consequence profile. A well-designed multi-agent governance layer doesn't just enforce binary permit/deny decisions — it evaluates risk contextually. Low-risk actions can proceed autonomously. Higher-risk actions may require human confirmation. Critical actions may require explicit approval from designated authorities. This kind of tiered execution model requires a control plane sophisticated enough to assess risk in real time.
At this level, guardrails are no longer filters. They are infrastructure. They are the operating system on top of which your AI organization runs.
The Maturity Gap — and Why It Matters Now
Most enterprises are somewhere between Stage 1 and Stage 2. A handful are approaching Stage 3. The gap between where organizations think they are on this maturity curve and where they actually are is significant — and increasingly consequential.
Here's what I observe in practice: organizations often self-assess at Stage 2 because they have some tool-level policy enforcement. But when you look closely, that enforcement is inconsistent, siloed to specific teams or use cases, and not auditable in any systematic way. They're operating with Stage 1 governance assumptions in an increasingly Stage 2 and Stage 3 world.
The risks compound as capability increases. An ungoverned LLM can embarrass you. An ungoverned agent can breach compliance, expose data, or trigger financial consequences. An ungoverned multi-agent system operating at scale can do all of that simultaneously, across organizational boundaries, before any human has time to notice.
But the opportunity compounds too. Organizations that build robust governance infrastructure early don't just protect themselves from downside risk — they unlock upside. When your teams trust that the AI systems they're deploying are properly governed, they can move faster. They can authorize higher-stakes workflows. They can deploy at greater scale. The trust infrastructure becomes a competitive advantage — not because it's a moat, but because it's a foundation.
Practical Guidance: Where to Start
If you're trying to assess and advance your organization's position on this maturity curve, here's how I'd frame the work at each stage:
Moving from Stage 1 to Stage 2 requires a fundamental reframe: stop thinking of guardrails as a content layer and start thinking of them as an authorization layer. Map your organizational access model. Define what tools exist, which roles can invoke them, and under what conditions. Build policy enforcement that's consistent across all agents — not owned by individual teams, but governed centrally.
Moving from Stage 2 to Stage 3 requires investment in a shared control plane. This is the layer that every agent in your ecosystem routes through before taking consequential action. It needs to be fast enough not to meaningfully degrade agent performance, flexible enough to accommodate dynamic routing, and auditable enough to satisfy both internal and external stakeholders.
In both cases, the technical architecture needs to be matched by organizational clarity: who owns AI governance? Who defines and updates policy? Who reviews audit logs? Who is accountable when something goes wrong? Guardrails without governance ownership are just infrastructure waiting to be circumvented.
The Question That Doesn't Go Away
The question I keep coming back to, regardless of which stage I'm discussing, is this: as we hand more autonomy to AI systems, who is responsible for the decisions they make?
This isn't a rhetorical question. It has a practical answer, and that answer lives in architecture. Guardrails are how organizations operationalize accountability — not in policy documents that nobody reads, but in systems that enforce policy at execution time, log what happened, and make it possible to understand and explain every action the AI took.
The organizations that figure this out early will not just be safer. They'll be faster, more trusted, and better positioned to capture the genuine value that enterprise AI offers — because they'll have built the foundation required to deploy it at scale without flying blind.
The governance conversation is the capability conversation. They're not in tension. They're the same conversation.
GitHub Repo: ai-guardrails-three-examples