Table of Links
-
2.2 An anedotal model from industry
-
A Model for Commercial Operations Based on a Single Transaction
-
Modelling of a Binary Classification Problem
6 Related Work
As we stated earlier, most of the work on LLM is based on their performance under specific benchmarks [Chang et al., 2023, Zhao et al., 2023], disregarding the financial aspects relevant to a business operation.
Our work aligns with the broader discourse on the return on investment in AI technologies. Recently, two articles took a similar path as ours, but with different approaches.
Gupta [2024], a conceptual approach to the RoI disccusion, propose a structured framework called the AI Maturity Continuum, which delineates the uniqueness of the RoI curve in AI projects. This continuum is segmented into three phases: problem understanding and data preparation, model improvement, and maximizing system capabilities. The first phase emphasizes understanding the problem, defining success metrics, and preparing the dataset, which parallels the initial steps in our decision-theoretic model where we define the problem and consider the costs and benefits of using different LLMs. The second phase focuses on the transition from a basic model to an optimized model, reflecting our approach of evaluating LLMs based on their performance and associated costs. Finally, the third phase involves pushing the AI system’s capabilities to their limits, similar to our sensitivity analysis and fine-tuning of cost variables to maximize RoI. Gupta [2024] underscores the importance of a phased approach to AI development and highlights the significant effort required in the initial stages to ensure a successful implementation. Their approach, however, is purely conceptual, while ours is based on decision-theoretic model.
Shekhar et al. [2024] discuss strategies for optimizing the costs associated with LLM usage. Their research identifies, like ours, key cost variables, such as network costs, embedding costs, and the periodic fine-tuning of models, which are crucial for accurate cost assessment and optimization. They emphasize the importance of considering both fixed and variable costs in the economic evaluation of LLMs. This work complements our study by providing a detailed breakdown of cost components. Additionally, they highlight the impact of reinforcement learning strategies and the necessity of periodically refining models, aligning with our recommendation to integrate more cost variables, including the need for periodic fine-tuning, in future work. Their approach to cost optimization, although, does not takes into account the gains and losses, or different impact of the probabilities of success.
7 Future work
Future research should explore more business scenarios to expand the applicability of the proposed models. Each industry or business model has unique operational variables and challenges that can affect the adoption and success of LLM. By exploring diverse contexts, such as retail, finance, healthcare, and logistics, the framework can be refined to accommodate the specific needs of different sectors. This exploration will enhance the robustness of this decision-theoretic approach, ensuring that it is adaptable and relevant across a wide range of business applications.
A comprehensive evaluation of LLMs should consider a broader spectrum of cost variables. Some of these aspects are discussed in subsubsection 2.3.1. This includes not only the initial fixed costs associated with implementation and usage, but also other AI related tasks, such as periodic fine-tuning and maintenance expenses, and additional variable costs, such as network costs. Future work should focus on developing models that incorporate these ongoing costs to provide a more accurate and realistic assessment of the total cost of ownership.
With respect to the models themselves, it is necessary to analyze the impact of the input size on the probability of success with respect to different prompt strategies. This would mean modeling P, and its variations, a function of P, with impact on sensitivity analysis. This would allow for including prompt technical evaluation in our model, since a zero shot prompt in a single turn would be a much smaller transaction than multi-turn mixed strategy with many agents [Sahoo et al., 2024, Li et al., 2024].
A dynamic evaluation of project revenues and costs over time is essential for making informed investment decisions. Future work should focus on developing models that calculate the present value of future cash flows, taking into account the value of money over time. This involves projecting revenue and cost streams throughout the lifecycle of the project and discounting them to their present value. By incorporating techniques such as net present value (NPV) and internal rate of return (IRR), the models can provide a more accurate picture of the long-term financial viability and profitability of LLM investments [Park, 2013].
8 Conclusion
This study underscores the importance of considering specific business parameters, such as Gain, Losses, and Probability of success, in evaluating the earnings and RoI for LLM.
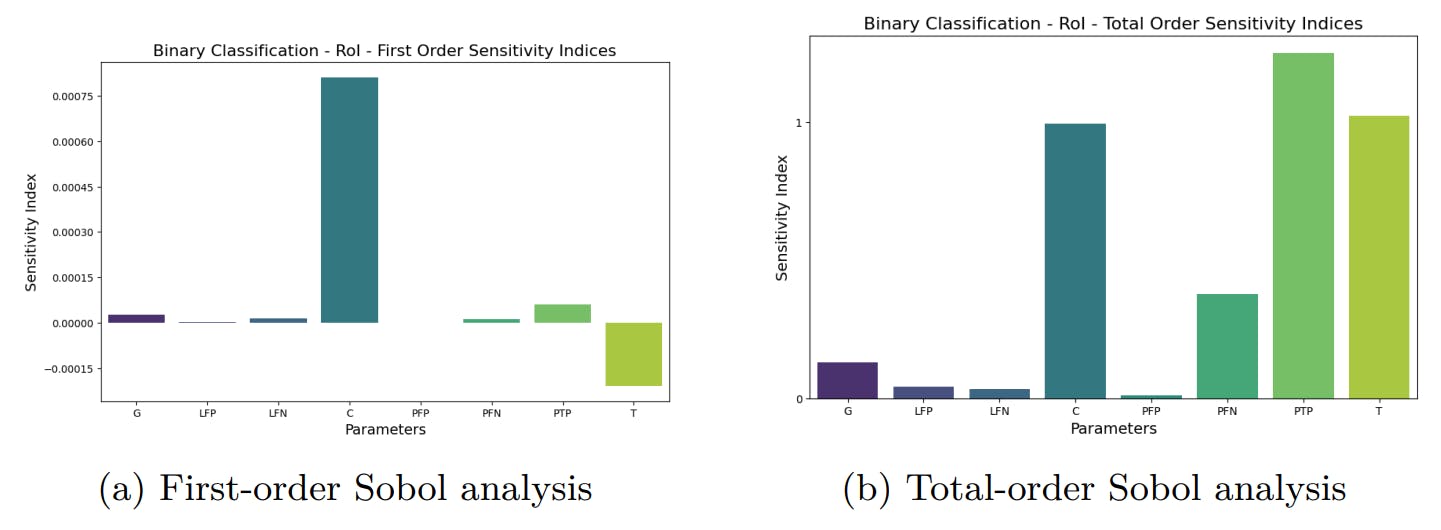
This analysis shows that it is important to optimize P and T for the same business operation, when choosing an LLM, always taking into account C, although it is fairly small, since all these values have a strong impact on both earnings and RoI.
Our findings emphasize that for businesses aiming to optimize their technology investments, particularly in the deployment of advanced language models, it is crucial to consider not only the direct costs, but also the broader economic implications of model performance and success rates. We show, for example, that for some business tasks with small transactions and large gains, prompt compression can bring negative financial results. This approach provides a more nuanced framework that can guide strategic decisions, ensuring that investments are aligned with expected financial returns.
This paper contributes to the ongoing discourse on computational finance by refining the methods used to assess technology investments, particularly in the field of artificial intelligence.
Future research should consider expanding these analyses to include more complex models and a broader range of operational contexts to further validate and enhance the robustness of our conclusions.
References
Christopher M. Bishop. Pattern Recognition and Machine Learning (Information Science and Statistics). Springer-Verlag, Berlin, Heidelberg, 2006. ISBN 0387310738.
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie. A survey on evaluation of large language models, 2023.
Grabriel Frahm. Rational Choice and Strategic Conflict: The Subjectivistic Approach to Game Decision and Theory. De Gruiter, Berlin, 2019.
Anuj Gupta. Ai maturity continuum: A three step framework to understand return on investment (roi) in ai. SSRN Electronic Journal, 2024. ISSN 1556- 5068. doi: 10.2139/ssrn.4754694. URL http://dx.doi.org/10.2139/ssrn. 4754694.
Jon Herman and Will Usher. SALib: An open-source python library for sensitivity analysis. The Journal of Open Source Software, 2(9), 1 2017. doi: 10.21105/ joss.00097. URL https://doi.org/10.21105/joss.00097.
Takuya Iwanaga, William Usher, and Jonathan Herman. Toward SALib 2.0: Advancing the accessibility and interpretability of global sensitivity analyses. Socio-Environmental Systems Modelling, 4:18155, 5 2022. doi: 10.18174/sesmo. 18155. URL https://sesmo.org/article/view/18155.
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. LLMLingua: Compressing prompts for accelerated inference of large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13358–13376. Association for Computational Linguistics, December 2023a. doi: 10.18653/v1/2023.emnlp-main.825. URL https://aclanthology.org/2023.emnlp-main.825.
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. LongLLMLingua: Accelerating and enhancing llms in long context scenarios via prompt compression. ArXiv preprint, abs/2310.06839, 2023b. URL https://arxiv.org/abs/2310.06839.
Ravi Kishore Kodali, Yatendra Prasad Upreti, and Lakshmi Boppana. Large language models in aws. In 2024 1st International Conference on Robotics, Engineering, Science, and Technology (RESTCON), pages 112–117, 2024. doi: 10.1109/RESTCON60981.2024.10463557.
Junyou Li, Qin Zhang, Yangbin Yu, Qiang Fu, and Deheng Ye. More agents is all you need, 2024.
OpenAI. OpenAI Pricing. https://openai.com/pricing, 2024.
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor Rühle, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, and Dongmei Zhang. Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression, 2024.
Chan S. Park. Fundamentals of Engineering Economics. Pearson, 3 edition, 2013.
Project Management Institute. A Guide to the Project Management Body of Knowledge (PMBOK® Guide). Project Management Institute, Newtown Square, Pennsylvania, 7 edition, 2021. ISBN 978-1628256642.
Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. A systematic survey of prompt engineering in large language models: Techniques and applications, 2024.
Andrea Saltelli, Stefano Tarantola, Francesca Campolongo, and Marco Ratto. Sensitivity Analysis in Practice: A Guide to Assessing Scientific Models. John Wiley & Sons, 2004.
Andrea Saltelli, Marco Ratto, Terry Andres, Francesca Campolongo, Jessica Cariboni, Debora Gatelli, Michaela Saisana, and Stefano Tarantola. Global Sensitivity Analysis: The Primer. Wiley-Interscience, 2008.
Leonard J. Savage. The Foundations of Statistics. Dover Publications, New York, 2 edition, 1954.
Shivanshu Shekhar, Tanishq Dubey, Koyel Mukherjee, Apoorv Saxena, Atharv Tyagi, and Nishanth Kotla. Towards optimizing the costs of llm usage, 2024.
Ilya M Sobol. Global sensitivity indices for nonlinear mathematical models and their monte carlo estimates. Mathematics and computers in simulation, 55 (1-3):271–280, 2001.
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. A survey of large language models, 2023.
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, and Qing Li. Recommender systems in the era of large language models (llms), 2024.
Acknowledgements
This paper was written with the help of different artificial intelligence tools to partially generate code, find references, and verify the style and grammar. Among the LLMs used were Google’s AI Assistant for Google Colab, Google Search Lab AI, OpenAI ChatGPT-4o, Microsoft Co-Pilot for Visual Studio Code, and Writeful. All authors have English as their second language.
This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior – Brasil (CAPES) – Finance Code 001”.
Authors:
(1) Geraldo Xexéo, Programa de Engenharia de Sistemas e Computação – COPPE, Universidade Federal do Rio de Janeiro, Brasil;
(2) Filipe Braida, Departamento de Ciência da Computação, Universidade Federal Rural do Rio de Janeiro;
(3) Marcus Parreiras, Programa de Engenharia de Sistemas e Computação – COPPE, Universidade Federal do Rio de Janeiro, Brasil and Coordenadoria de Engenharia de Produção - COENP, CEFET/RJ, Unidade Nova Iguaçu;
(4) Paulo Xavier, Programa de Engenharia de Sistemas e Computação – COPPE, Universidade Federal do Rio de Janeiro, Brasil.
This paper is