Table of Links
-
Related Works
2.3 Evaluation benchmarks for code LLMs and 2.4 Evaluation metrics
-
Methodology
-
Evaluation
4.3 Inference Time
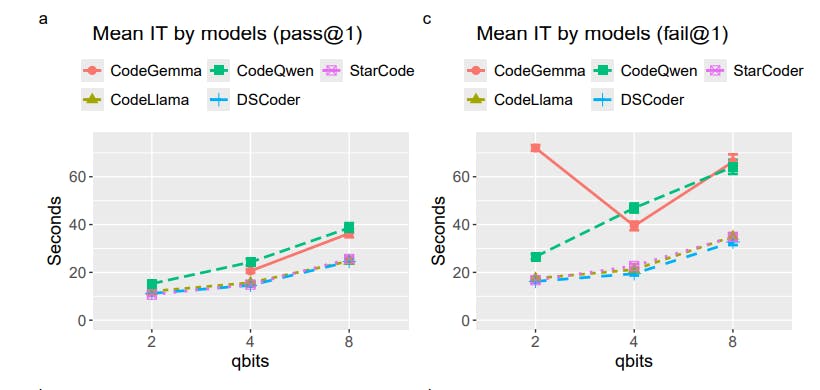
Fig. 4 depicts the inference times broken down by the models and benchmarks. The figure also shows the inference times separately for the correct (pass@1) and incorrect (fail@1) solutions.
For all models, the inference time increased with higher precision (more qbits). The effect is stronger for the failed solutions. Overall, the failed solutions took longer times to generate than the correct solutions. CodeGemma, StarCoder, and DeepSeek Coder share the same pattern. CodeQwen spent more time than the other models inferring both correct and failed solutions. CodeGemma similarly demanded longer inference times but this did not as effectively translate to better results as with CodeQwen (Fig. 2).
For the benchmarks, the inference times also increased with qbits. For the failed solutions in MBPP and MCEVAL, the inference times demonstrate a V-shaped pattern. It is due to CodeGemma’s inflated inference times at 2-bit quantization, where it had a complete breakdown of its inference ability.
Fig. 5 offers a more detailed view of the inference times. For the correct solutions, the divergence in inference times for CodeQwen from the other models is mainly observed in the HumanEval benchmark. Higher precision resulted in more divergence. According to Fig. 2, 8-bit CodeQwen is the second-best-performing model on HumanEval. However, the 4-bit CodeQwen model was not able to take similar advantage of longer inference time as its performance on HumanEval was not better than that of the other models. This demonstrates a variable effect of quantization on different models and benchmarks. For example, a longer inference time does not necessarily translate to better performance and may not compensate for the lower precision of a model. This is especially evident in CodeGemma, which consistently took longer inference time but demonstrated poorer performance across all three quantization levels than the other models.
A regression analysis was done on the inference times with solution correctness (boolean), benchmarks, model, and q-bits as nominal predictors. The regression model also included all possible two-way interactions. The data from CodeGemma was excluded from the analysis to avoid the skewed results from influencing the analysis. The model’s adjusted R2 is 0.38 compared to the adjusted R2 of 0.31 of the baseline regression model without any interactions. AIC is 63743.23 compared to the AIC of 64471.65 of the baseline model.
Table 7 lists the coefficients with corresponding statistics. Insignificant two-way interactions are not listed in Table 7. The intercept represents an average inference time in seconds for an incorrect solution generated by 2-bit CodeLlama in the HumanEval benchmark. The regression model confirms the effects observed in the descriptive statistics. The correct solutions required less time to generate than the incorrect solutions. For both the correct and incorrect solutions, the inference time increases with higher q-bits. The tasks in MBPP generally require less inference time than the tasks in the two other benchmarks. This discrepancy increases with higher quantization bits. Many of the interactions account for the effects related to CodeQwen: the rate of increase in inference time with more q-bits is higher than for the other models, and this effect is even more inflated in the HumanEval benchmark.
Author:
(1) Enkhbold Nyamsuren, School of Computer Science and IT University College Cork Cork, Ireland, T12 XF62 (enyamsuren@ucc.ie).
This paper is available on arxiv under CC BY-SA 4.0 license.