This is a Plain English Papers summary of a research paper called THINKSAFE: Self-Generated Safety Alignment for Reasoning Models. If you like these kinds of analysis, join AIModels.fyi or follow us on Twitter.
The reasoning revolution and its hidden cost
Large language models have become remarkably good at reasoning. Models like DeepSeek-R1 achieve stunning performance by using reinforcement learning to generate long, step-by-step explanations of their thinking. This chain-of-thought reasoning is powerful, but it creates an unexpected vulnerability: the harder you optimize models to reason, the more vulnerable they become to harmful requests.
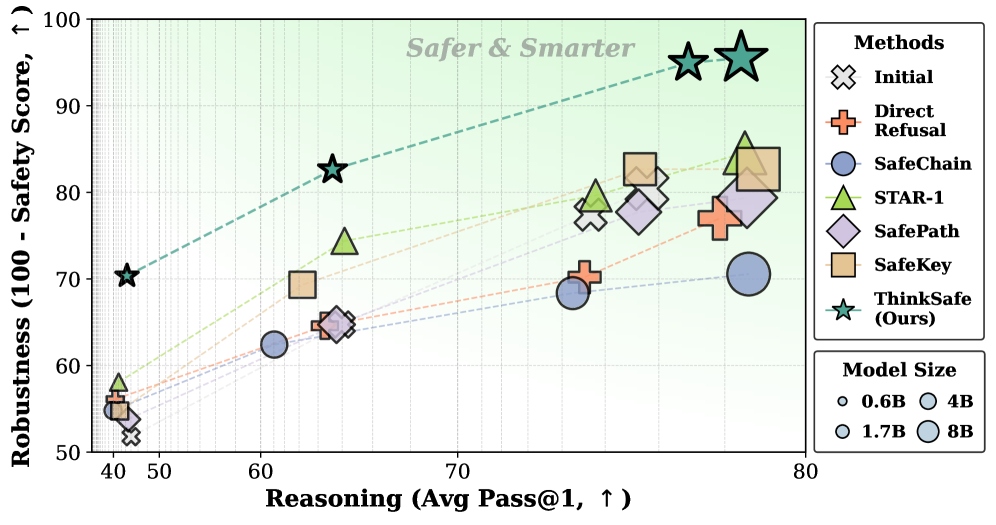
The problem appears when you look at how these models perform after reasoning optimization. On one axis, their reasoning ability climbs steadily. On the other, their safety degrades. This isn't because the models become more malicious. It's because the optimization process that makes them compliant with instructions also makes them compliant with harmful instructions. When you turn up the volume on "follow reasoning optimization," you accidentally turn down the volume on "notice when something is dangerous."
Safety and reasoning performance of the Qwen3 family
Safety and reasoning performance of the Qwen3 family. As reasoning ability improves, safety degrades, creating a direct trade-off.
The tension shows clearly across model families. Stronger reasoners are weaker at refusing harmful requests. This creates a dilemma: do you want a capable model or a safe one?
Why external safety training breaks everything
The obvious response is to fix safety with another round of training. Researchers have experimented with teaching safety by using external models, usually called teacher distillation. A stronger, safer model generates safe responses, and you fine-tune your reasoning model on that data. It should work.
It doesn't, at least not cleanly. The problem is subtle but fundamental: when an external model generates safe responses, it speaks in a different reasoning voice than your model naturally uses. The safe responses are correct, but they're formatted in a way that doesn't match the model's native thinking process. When you fine-tune on that mismatched data, something breaks.
The model doesn't restore safety while keeping its reasoning ability intact. Instead, it develops a split personality. It learns to produce safe outputs, but those outputs come from a different part of its reasoning process than its natural thinking. When asked to reason through a problem, the model has to switch between its native reasoning voice and the foreign safety voice. This shift degrades reasoning performance because the model is no longer operating smoothly in one mode.
This is the fundamental issue that external distillation introduces: distributional discrepancy. The data the model learns from doesn't match the distribution of data it naturally generates. The model can't integrate safety reasoning into its native thinking style, so safety and reasoning work against each other instead of together.
What models actually know but can't express
Here's where ThinkSafe begins to diverge from the standard approach. The insight is counterintuitive but powerful: models that have been optimized for reasoning don't actually lose their safety knowledge. They lose the ability to express it in their natural reasoning voice.
When researchers tested whether reasoning-optimized models could still identify harmful requests, they found the answer was yes. Models retained latent knowledge about what constitutes harm. They could recognize danger when prompted the right way. The problem was that this safety knowledge had become separated from the reasoning process itself. The model could identify harm, but it couldn't explain its reasoning about why something was harmful in a way that felt natural to itself.
This is a crucial distinction. The model hasn't forgotten what's dangerous. It's forgotten how to think about danger while also thinking through a problem. The safety capability is there, dormant, locked away from the reasoning pipeline.
Ablation of safety reasoning in R1 model series
Ablation of safety reasoning in R1 model series. The models retain the ability to reason about safety, even after optimization for long-form reasoning.
Ablation of safety reasoning in Qwen3 model series
Ablation of safety reasoning in Qwen3 model series. Safety reasoning capability is preserved across the model family, waiting to be unlocked.
This observation reframes the entire problem. You don't need to teach the model safety. You need to help it express the safety knowledge it already possesses, in its own reasoning style.
The steering mechanism that unlocks latent safety
ThinkSafe's core mechanism is elegant because it's simple. The framework uses lightweight refusal steering to guide models toward generating their own safety reasoning.
Here's how it works: at each step of reasoning, a model has latent capacity to follow multiple paths. Normally, compliance optimization has made the permissive path the default. Refusal steering applies a gentle nudge that says, "This time, explore the safety-conscious path instead." The model generates its reasoning about why a request is harmful, naturally, using its own chain-of-thought process.
This is different from rejection sampling, which discards unsafe outputs but doesn't explain them. Steering actively guides the model toward safety reasoning, so it generates full explanations, not just refusals. Crucially, these explanations feel in-distribution because they're generated by the same model using the same reasoning mechanism, just pointed in a different direction.
ThinkSafe employs refusal steering to guide the student model
ThinkSafe employs refusal steering to guide the student model. This mechanism unlocks the student's latent safety capabilities to generate valid reasoning traces, resulting in responses that are both safe and in-distribution.
Once you have these self-generated safety traces, fine-tuning on them realigns the model without introducing distribution shift. The model learns safety reasoning from itself, not from an external teacher, so the reasoning style stays consistent.
Why does this matter? Because consistency of style means the model integrates safety back into its native reasoning process. Instead of learning two separate modes, it learns that safety and reasoning are part of the same thinking pipeline. The latent knowledge becomes accessible during normal reasoning.
Does self-generated safety actually work
Theory is satisfying, but results matter. The empirical question is straightforward: do models trained on their own self-generated safety reasoning actually become safer while preserving reasoning ability?
The answer is yes, and the gains are substantial. Comparing ThinkSafe against GRPO, an online reinforcement learning approach that directly optimizes for safety, shows that ThinkSafe achieves comparable reasoning performance with better safety outcomes, while requiring significantly less computation.
Comparison of ThinkSafe with online RL GRPO
Comparison of ThinkSafe with online RL, GRPO. ThinkSafe achieves comparable reasoning performance with superior safety while using far less computational resources.
One detail confirms that the theory is working as intended: self-generated safety data has lower perplexity than data generated through standard rejection sampling. This means the model generates safety reasoning that feels natural to itself, validating the in-distribution hypothesis. The safety reasoning doesn't feel foreign to the model's native process.
Perplexity of generated safety dataset measured by the initial student models
Perplexity of generated safety dataset measured by the initial student models. Self-generated safety data is lower perplexity than rejection sampling, indicating in-distribution quality.
Practical details matter too. The statistics of generated safety data show that ThinkSafe produces reasonably sized reasoning chains, neither artificially short nor unnecessarily long. Across both DeepSeek-R1-Distill and Qwen3 families, the length distribution is consistent with the models' native reasoning patterns.
Statistics of ThinkSafe in Qwen3 model series
Statistics of ThinkSafe in Qwen3 model series. Top 1% outliers by length are excluded for better interpretability.
Statistics of ThinkSafe in DeepSeek-R1-Distill model series
Statistics of ThinkSafe in DeepSeek-R1-Distill model series. Top 1% outliers by length are excluded for better interpretability.
When safety comes free and when it costs
Real systems always involve trade-offs, and ThinkSafe is no exception. The good news: in most cases, safety gains don't degrade reasoning at all. The self-generated safety reasoning integrates cleanly with the model's native thinking process. But in some scenarios, a small cost emerges.
The ratio of reasoning gain to safety gain varies across model families and sizes. Larger models sometimes show tighter coupling between safety and reasoning, meaning that improving one slightly impacts the other. This coupling is real but small, far less severe than the cost of external distillation.
Ratio of reasoning gain to safety gain for student models trained on data generated by teachers from the same model family
Ratio of reasoning gain to safety gain for student models trained on data generated by teachers from the same model family. Most models show favorable trade-offs, with safety improvement outpacing any reasoning cost.
Another insight emerges from cross-family experiments. ThinkSafe works best when the safety signal comes from within the same model family. When you use a different model family as the teacher, performance degrades slightly, reintroducing some distributional mismatch. This makes sense: different architectures develop different reasoning styles, so having one architecture explain safety reasoning in another architecture's style creates friction.
Safety and reasoning performance gain using a different family of teacher model with similar size
Safety and reasoning performance gain using a different family of teacher model with similar size. Cross-family alignment introduces modest performance degradation.
Safety and reasoning performance gain using a different family of teacher model with similar size (Qwen3)
Safety and reasoning performance gain using a different family of teacher model with similar size, tested on Qwen3. Cross-family effects persist across model families.
Comparison with rejection sampling reveals the value of active steering. Models trained on safety data from standard rejection sampling perform noticeably worse than those trained on ThinkSafe's steered data. This suggests that the quality of the safety reasoning traces matters, not just their existence.
Models trained on safety data generated via standard rejection sampling versus ThinkSafe
Models trained on safety data generated via standard rejection sampling versus ThinkSafe. Steered data produces better safety outcomes than unguided rejection sampling.
The broader context
This work connects to a broader shift in how researchers approach safety for reasoning models. Prior work like SafeThinker explored reasoning about risk in safety alignment, while self-guided defense mechanisms have shown that models can develop their own safety strategies. The central theme across this research is that models contain more safety capability than traditional alignment approaches unlock.
ThinkSafe advances this insight by showing that you don't need online RL or external teachers to realign reasoning models. You need the right nudge to let the model explain its own safety reasoning. This is cheaper, faster, and more reliable than approaches that impose safety from outside.
The framework solves a real problem for organizations deploying reasoning models at scale. You get safety and reasoning performance without the computational expense of online RL or the reasoning degradation of external distillation. For practical deployment, that's a significant advantage.