
Authors:
(1) Samson Yu, Dept. of Computer Science, National University of Singapore (samson.yu@u.nus.edu);
(2) Kelvin Lin. Dept. of Computer Science, National University of Singapore;
(3) Anxing Xiao, Dept. of Computer Science, National University of Singapore;
(4) Jiafei Duan, University of Washington;
(5) Harold Soh, Dept. of Computer Science, National University of Singapore and NUS Smart Systems Institute (harold@comp.nus.edu.sg).
Table of Links
- Abstract and I. Introduction
- II. Related Work
- III. PhysiClear - Tactile and Physical Understanding Training & Evaluation Suite
- IV. Octopi - Vision-Language Property-Guided Physical Reasoning
- V. Experimental Setup
- VI. Experimental Results
- VII. Ablations
- VIII. Conclusion and Discussion, Acknowledgements, and References
- Appendix for Octopi: Object Property Reasoning with Large Tactile-Language Models
- APPENDIX A: ANNOTATION DETAILS
- APPENDIX B: OBJECT DETAILS
- APPENDIX C: PROPERTY STATISTICS
- APPENDIX D: SAMPLE VIDEO STATISTICS
- APPENDIX E: ENCODER ANALYSIS
- APPENDIX F: PG-INSTRUCTBLIP AVOCADO PROPERTY PREDICTION
- Appendix for Octopi: Object Property Reasoning with Large Tactile-Language Models
VII. ABLATIONS
In this section, we describe ablation studies to examine (i) the impact of the encoder’s learned representations on physical property prediction and (ii) the influence of end-to-end finetuning data quantity on physical reasoning. For the following sections, we report test accuracy on unseen objects.
A. Ablation: The Impact of Encoder Fine-tuning
We used vision-based tactile inputs in this work and pretrained vision foundation models (i.e. CLIP) have shown impressive performance on vision tasks. To test whether additional fine-tuning improves the pre-trained CLIP encoder’s representations for physical property prediction using tactile images, we conducted ablation experiments. We compared the performance of two OCTOPI versions — one trained with the off-the-shelf CLIP encoder and the other trained with the finetuned CLIP encoder.
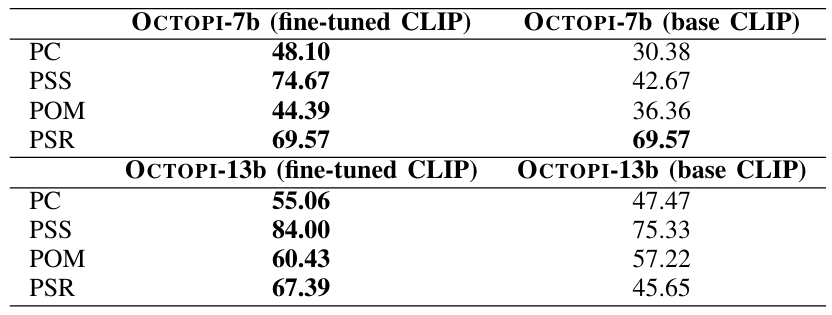

In Table X, our Object Property Description results show that OCTOPI-7b trained with a fine-tuned CLIP encoder outperforms one trained with an unmodified CLIP encoder by 7.90% on combined accuracy. Similarly, OCTOPI-13b with the fine-tuned CLIP visual encoder performs better on the combined, roughness, and bumpiness predictions, with the combined accuracy being 5.26% higher. This suggests that a fine-tuned CLIP generally improves its learned representations for physical property prediction in an end-to-end LVLM.
We further tested both OCTOPI versions on physical understanding tasks with results in Table XI. For OCTOPI-7b, the version trained with a fine-tuned CLIP encoder performs better across the three physical understanding tasks (by 17.72% on PC, 32.00% on PSS, 8.03% on POM). Similarly, OCTOPI-13b with the fine-tuned CLIP encoder has a better performance for physical understanding tasks, which suggests that finetuning generally helps physical understanding and physical reasoning performance. Further encoder analysis can be found in Appendix E.
B. Ablation: The Impact of End-to-end Fine-tuning
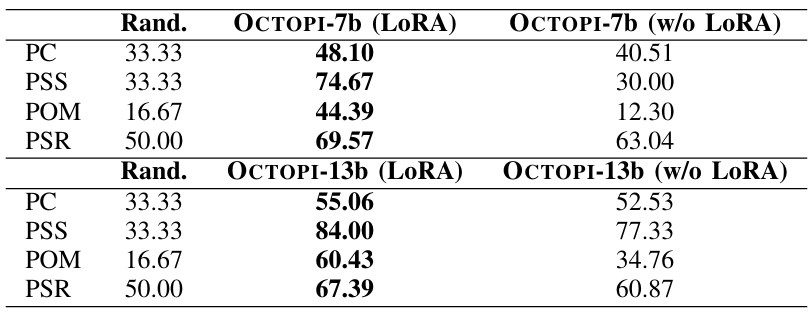
Table XII shows OCTOPI’s performance on the property prediction task before and after end-to-end fine-tuning with LoRA. For both OCTOPI-7b and OCTOPI-13b, the fine-tuned variants generally performed better. We see sharp improvements for OCTOPI-13b with improvements across the properties. Our results suggest that end-to-end fine-tuning improves physical property prediction accuracy. Similar to the property prediction task, we observed that fine-tuning with LoRA also improves OCTOPI’s performance on physical understanding tasks (Table XIII).
This paper is available on arxiv under CC BY 4.0 DEED license.
[story continues]
tags