Table Of Links
4 Identifying API Privacy-relevant Methods
5 Labels for Personal Data Processing
6 Process of Identifying Personal Data
7 Data-based Ranking of Privacy-relevant Methods
8 Application to Privacy Code Review
Conclusion, Future Work, Acknowledgement And References
Identifying API Privacy-Relevant Methods
Native privacy-relevant methods form the basis for identifying what we refer to as API privacyrelevant methods. These are methods found in third-party libraries and frameworks that are likely to process personal data by calling upon native privacy-relevant methods. Understanding the relationship between API and native methods is crucial for a complete review of how personal data is processed in a codebase.
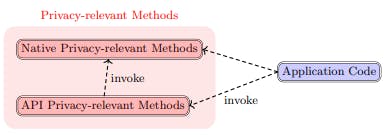
The identification process is iterative and takes into account the dependencies between libraries and codebases, as depicted in Fig. 2. The goal is to assemble a list of API privacy-relevant methods that have the potential to handle personal data. Understanding the relationship and dependency hierarchy among these libraries is essential for accomplishing this task.
4.1 Dependency Sorting and Identification of Privacy-relevant Methods
To manage library dependencies, we focus on import statements within each library’s source code. We organize the libraries in a sequence such that each library is evaluated only after all its dependencies have been assessed. This ensures a logical and efficient evaluation process. For the identification of API privacy-relevant methods, we define a set denoted as API.
This set includes methods from our organized list of libraries that invoke native privacy-relevant methods at some point during their execution. These methods are significant as they interact with native methods, either directly or through a chain of calls, making them critical for privacy code review.
Labels For Personal Data Processing
Compliance with data protection regulations like GDPR necessitates a nuanced understanding of how personal data is processed within code. While GDPR outlines various processing activities such as collection, recording, and organization, the four native privacy-relevant method categories [8] we previously discussed (I/O, security, database, and network) lack the granularity needed for comprehensive understanding.
For instance, the security category encompasses both authentication and encryption, warranting a more detailed labeling system. After analyzing top labels from Maven and NPM that pertain to personal data processing, we identified 20 labels that closely align with both GDPR’s definitions and our native privacyrelevant method categories. This shows how libraries handle data processing in different ways. For example, OAuth combines network and security functionalities, while Object-Relational Mapping (ORM) bridges database and I/O operations.
These overlaps underscore the necessity for a detailed set of labels tailored for privacy reviews. We present these labels and their alignment with GDPR requirements in Table 1. These labels serve a dual purpose: they categorize methods involved in data processing activities like collection, storage, and encryption, and they map these activities to GDPR compliance requirements. This streamlined mapping simplifies the task of identifying code sections that need to comply with legal standards. In our later approach, we use these labels to prioritize privacy-relevant methods, enabling a focused review on areas critical for data protection.
Authors:
- Feiyang Tang
- Bjarte M. Østvold
This paper is