
This article introduces an offline data governance platform built on DolphinScheduler, addressing issues like task dependency black holes and scalability bottlenecks. By implementing YAML-based dynamic compilation and automatic lineage capture, the platform enables efficient task dependency management and data tracking. It leverages the Neo4j graph database for lineage storage, supporting second-level impact analysis and root cause localization. Additionally, with a self-developed high-performance data import tool, data transmission efficiency is significantly improved.
Background and Challenges
Under the pressure of processing petabytes of data daily, the original scheduling system faced two major issues:
- Task dependency black holes: Cross-system task dependencies (Hive/TiDB/StarRocks) were manually maintained, resulting in troubleshooting times exceeding 30 minutes.
- Scalability bottlenecks: A single-point scheduler couldn't handle thousands of concurrent tasks. The lack of a retry mechanism led to data latency rates surpassing 5%.
Technology Stack
|
Component |
Selection Rationale |
Performance Advantages |
|---|---|---|
|
Scheduling Engine |
DolphinScheduler 2.0 |
Distributed scheduling throughput increased 3x |
|
Configuration Center |
Go template engine + YAML |
Lineage update iteration efficiency improved by 70% |
|
Data Synchronization |
Self-developed toolchain + DataX dual engine |
StarRocks import performance reaches 2TB/min |
|
Monitoring & Alerting |
SMS + Voice Call |
Alert response latency < 5s |
Core Architecture Design
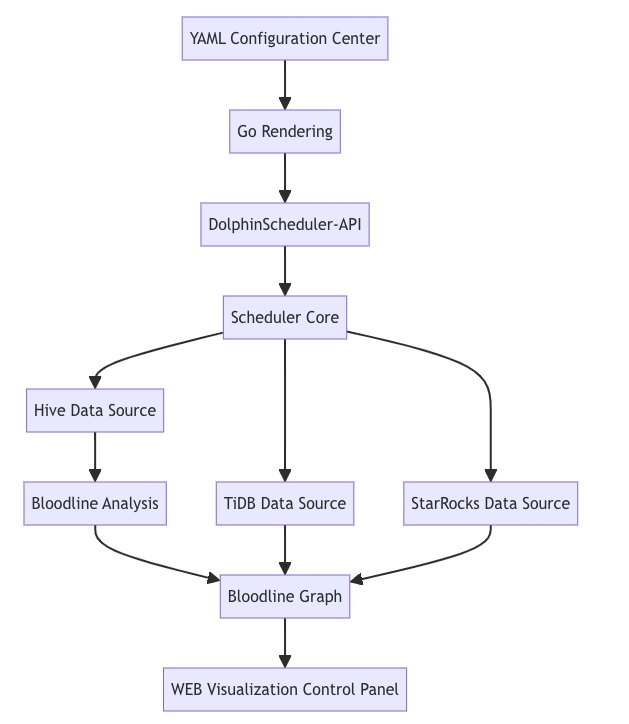
Key Technical Implementations:
- YAML Dynamic Compilation
type TaskDAG struct {
Nodes []Node `yaml:"nodes"`
Edges []Edge `yaml:"edges"`
}
func GenerateWorkflow(yamlPath string) (*ds.WorkflowDefine, error) {
data := os.ReadFile(yamlPath)
var dag TaskDAG
yaml.Unmarshal(data, &dag)
// Convert to DolphinScheduler DAG structure
return buildDSDAG(dag)
}
- Automatic Lineage Capture
- Intercepts SQL execution plans to parse input/output tables
- For non-SQL tasks, uses hooks to capture file paths
# StarRocks Broker Load Lineage Capture
def capture_brokerload(job_id):
job = get_job_log(job_id)
return {
"input": job.params["hdfs_path"],
"output": job.db_table
}
Solutions to Key Challenges
- Zero-Incident Migration Plan
- Dual-run comparison: Run both old and new systems in parallel; use the DataDiff tool to verify result consistency
- Canary release: Split traffic by business unit in stages
- Rollback mechanism: Full rollback capability within 5 minutes
- Self-Developed High-Performance Import Tool
|
Scenario |
Tool |
TPS Comparison |
|---|---|---|
|
Hive → StarRocks |
Hive2SR |
4×+ improvement over DataX |
|
Hive → DB |
Hive2db |
4×+ improvement over DataX |
|
TiDB → Hive |
Db2Hive |
2× improvement over Sqoop |
Key Optimizations:
- Batch submission using Go's coroutine pool
- Dynamic buffer adjustment strategy
func (w *StarrocksWriter) batchCommit() {
for {
select {
case batch := <-w.batchChan:
w.doBrokerLoad(batch)
// Dynamically adjust batch size
w.adjustBatchSize(len(batch))
}
}
}
Lineage Management Implementation
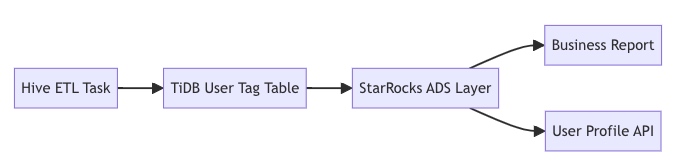
Lineage data is stored in the Neo4j graph database, enabling:
- Impact Analysis: Locate the affected scope of a table-level change within seconds
- Root Cause Analysis: Trace the source of an issue within 30 seconds during failures
- Compliance Auditing: Meets GDPR data traceability requirements
Performance Gains
|
Metric |
Before Migration |
After Migration |
Improvement Rate |
|---|---|---|---|
|
Task Failure Rate |
8.2% |
0.1% |
98.8% |
|
Daily Delayed Tasks |
47 |
<3 |
94% |
|
Lineage Maintenance Time |
10h/week |
0.5h/week |
95% |
[story continues]
tags