
You’re reading the final part of a 3-Part Series on Paxos Consensus Algorithms in Distributed Systems.
In Part 1, Alice and Bob fought for a lock using Paxos. In Part 2, we explored Paxos in the wild — messy situations like minority partitions, delayed proposals, and dueling proposers. Paxos ensured safety, but left developers with plenty of complexity to untangle.
Now, in Part 3, we’ll see how Raft tackles the same scenarios — with a much simpler leader–follower model.
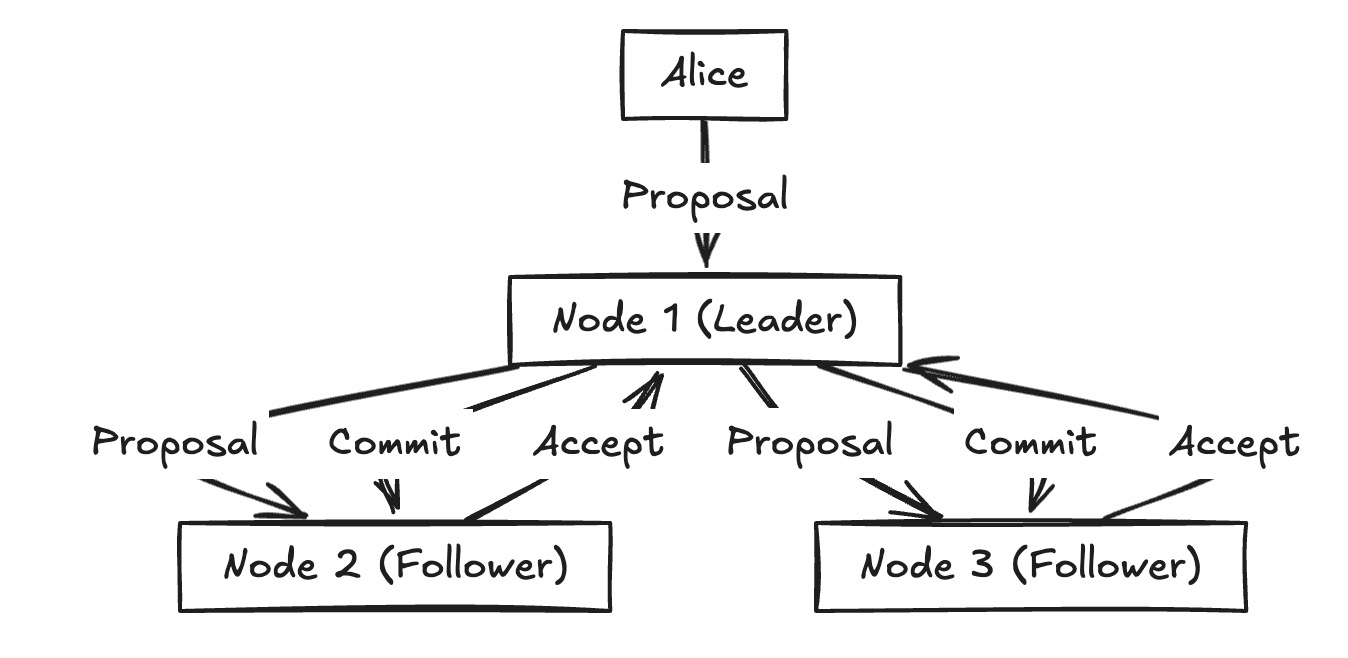
Normal Case
In Paxos, both Alice and Bob could try proposing values. Acceptors had to juggle these and eventually converge on one.
In Raft, the story is simpler. A single node is elected as the Leader. The client sends its proposal to the leader. The leader then replicates this proposal to their followers. Once a majority of followers accept, the leader commits and informs everyone.
- Proposal → Client (Alice) sends to the leader.
- Accept → Followers acknowledge the proposal.
- Commit → Leader commits after majority acceptance.
Edge Case 1 — Leader Crash — No Lost Commit
In Paxos, Alice could succeed in getting a majority but still stall if acknowledgments were lost or she disappeared before hearing back. The value was safe, but Alice might never know.
Raft avoids this ambiguity by making the leader responsible for all commits.
Alice’s case:
- Alice’s client sends a proposal to the leader (Node 4).
- Node 4 replicates the proposal to its followers.
- Suppose Node 4 crashes before sending a commit back to Alice.
In Paxos, this might look like Alice’s proposal is lost.
But in Raft:
- The followers who accepted Alice’s proposal still have it.
- When a new leader is elected, it must contain the most up-to-date log.
- The new leader finishes the commit, ensuring Alice’s value isn’t dropped.
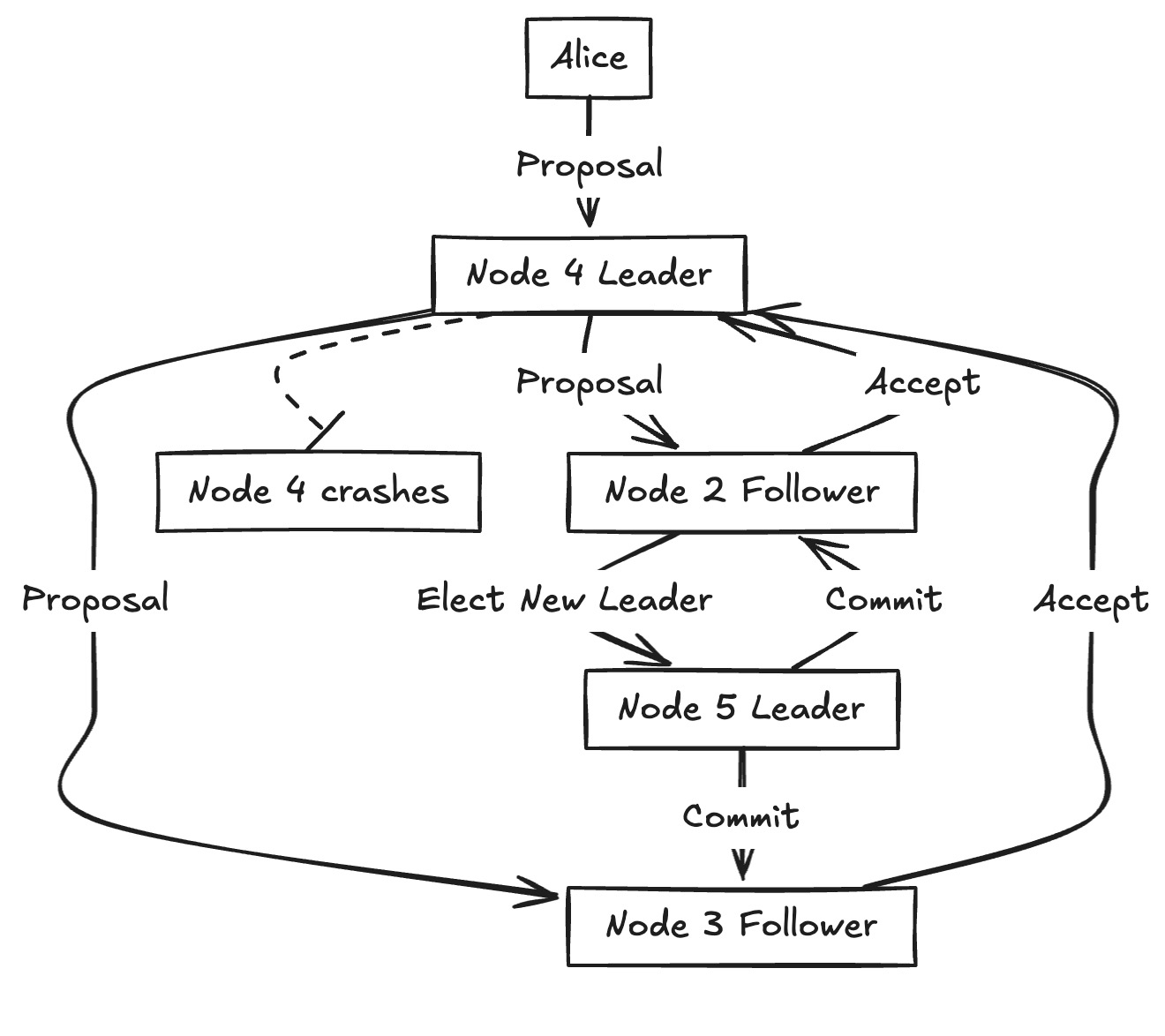
Result: No phantom successes — if a majority saw it, Raft guarantees it will eventually be committed.
Edge Case 2 — Simultaneous Proposals — No Dueling
In Paxos, Alice and Bob could both propose at the same time, causing the cluster to juggle values until a higher-numbered proposal won.
In Raft, this competition is eliminated by the single-leader model.
Alice vs Bob:
- Alice sends a proposal to Node 4, the current leader.
- At the same time, Bob also sends his proposal — but followers redirect him to Node 4.
- Only Node 4 can replicate proposals. Bob’s request is queued behind Alice’s.
If leadership changes mid-flight (say Node 4 crashes):
- A new leader is elected from the followers with the most complete log.
- Both Alice and Bob’s requests are retried through the new leader in order.
Result: Raft eliminates dueling proposers. Alice’s and Bob’s requests are funneled through one leader, keeping the log consistent.
Edge Case 3 — Minority Partition
In Paxos, even a minority group could keep sending proposals that ultimately wouldn’t succeed, leading to wasted work.
Raft takes a stricter stance. If a node is isolated in a minority partition, it simply cannot make progress. Only the majority side can elect a leader and continue processing proposals. When the network heals, the isolated node catches up with the leader’s log.
- Proposal from isolated node → ignored.
- Majority elects leader → proposals succeed.
- Commit happens only on the majority side.
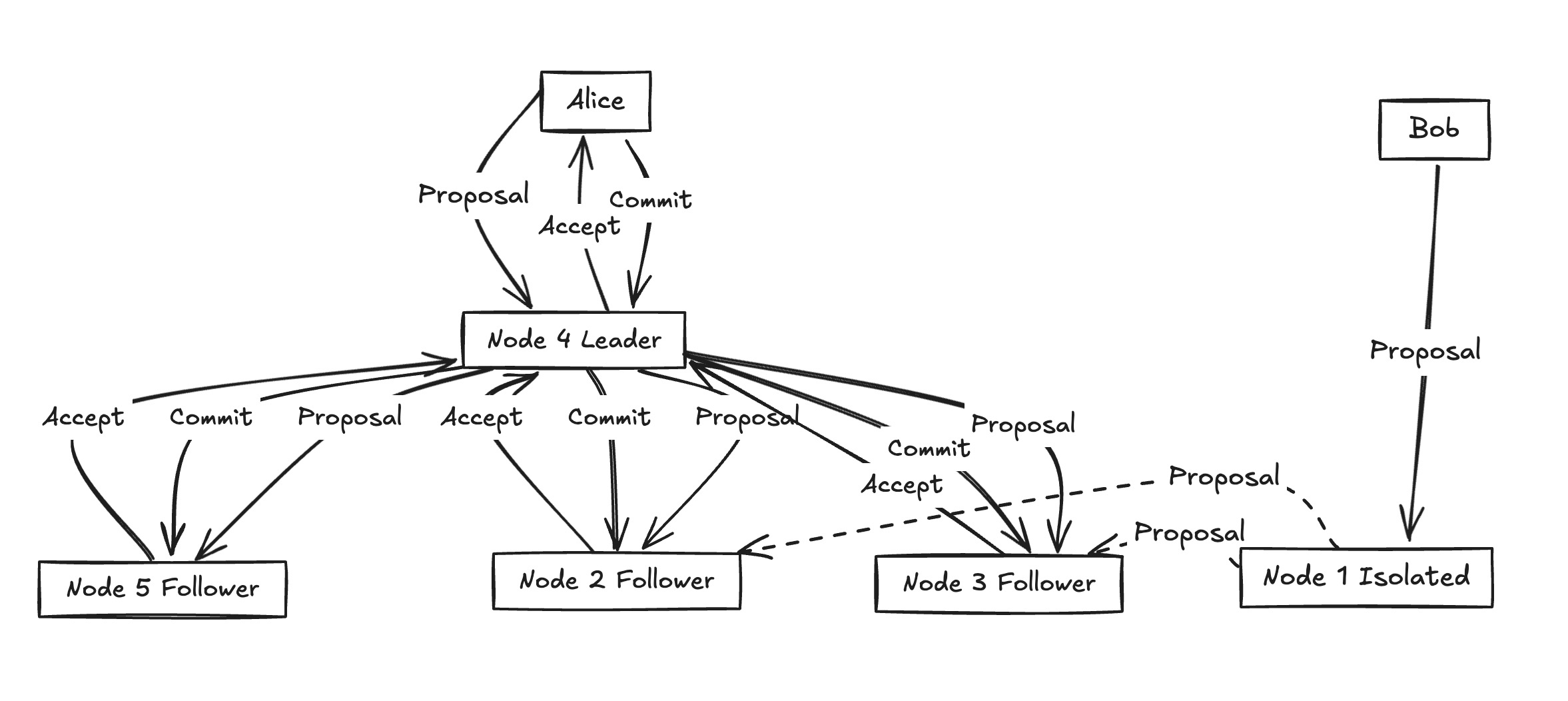
Alice’s side (majority):
Alice sends her proposal to the cluster. Node 4 is elected as Leader.
- Node 4 then replicates the Proposal to its followers: Node 2, Node 3, and Node 5.
- Each follower responds with Accept.
- Once a majority (Node 4 + 2 of the 3 followers) have accepted, Node 4 sends a Commit message.
- The log entry is safely applied cluster-wide in the majority partition.
Bob’s side (minority):
Bob sends a Proposal to Node 1. But Node 1 is in a minority partition (cut off from the rest).
- Node 1 cannot gather enough Accept responses to form a majority.
- Without majority, there is no Commit.
- Bob’s request stalls — Raft ensures safety by refusing to make progress in the minority.
Result: Only the majority moves forward. Alice’s proposal succeeds, Bob’s stalls — wasted work is avoided and consistency preserved.
Edge Case 4 — Delayed Proposal
In Paxos, old proposals could show up late and confuse acceptors, forcing extra reconciliation rounds.
Raft avoids this confusion. If a proposal arrives late after the cluster has already agreed on another value, followers simply reject it and move on. Only the leader’s current proposal can make progress.
In Alice and Bob’s case:
- Bob’s delayed proposal finally shows up at some nodes, but they’ve already agreed to Alice’s lock. They reject Bob’s message.
- Alice’s fresh proposal flows cleanly through the leader to the followers. They accept, and once a majority has responded, the leader sends a commit.
Bob’s late message:
- Bob’s old proposal finally reaches Node 1. Node 1 tries to forward it to Node 2 and Node 3.
- But by now, the cluster has already agreed on Alice’s lock.
- Node 2 and Node 3 simply reject Bob’s message, because it doesn’t match the decision they’ve already accepted.
Alice’s active proposal:
- Meanwhile, when Alice sends a new proposal through Node 4, the leader, it goes out cleanly to Node 2 and Node 3.
- Both followers accept it right away.
- With a majority on board, Node 4 issues a commit and everyone moves forward consistently.
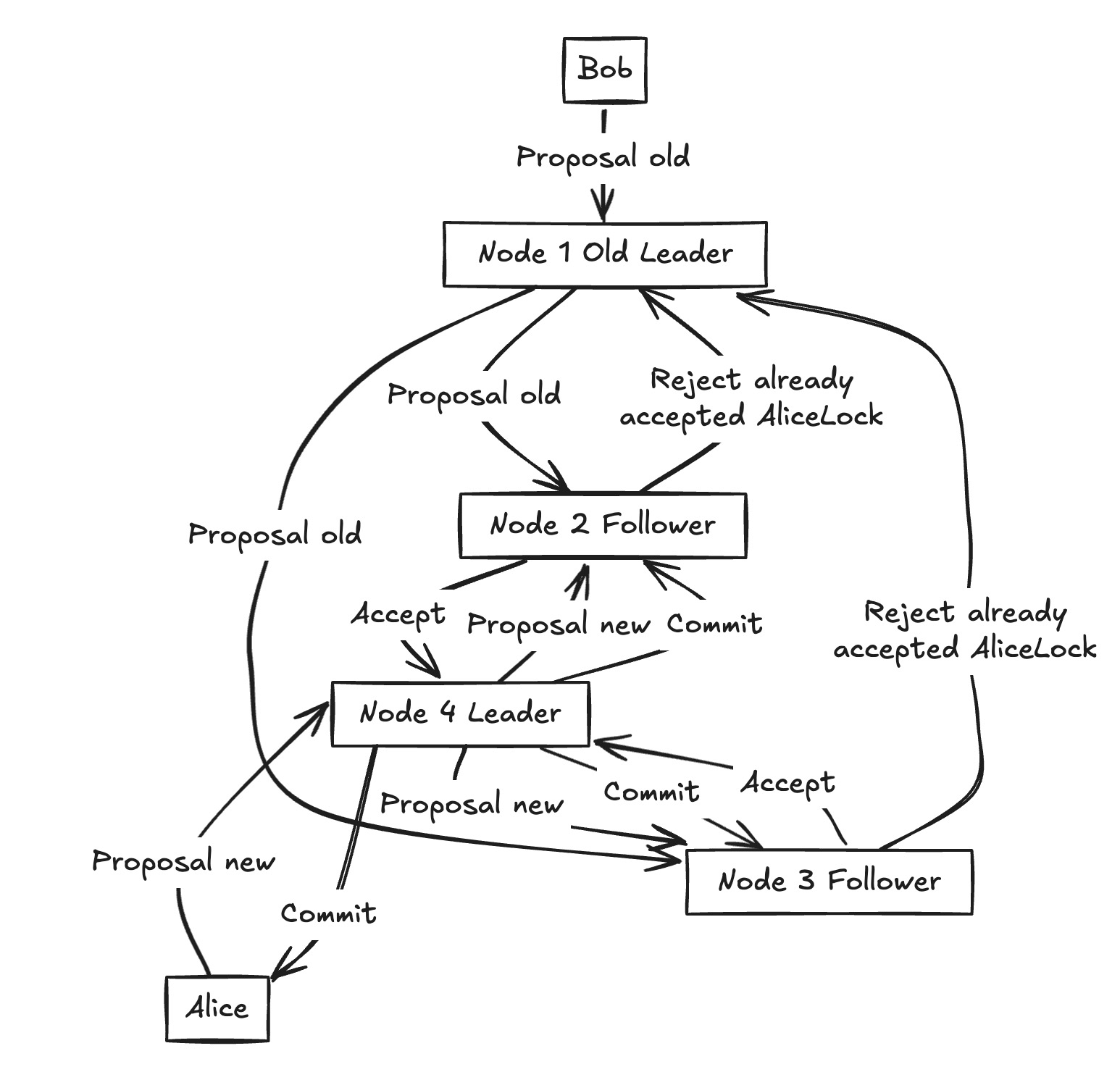
Result: Bob’s stale proposal is ignored. Alice’s proposal commits, and the log stays clean..
Wrap-Up for Part 3
Raft takes Paxos’s safety guarantees and adds clarity:
- Leader crashes → no lost commits.
- Simultaneous proposers → funneled through one leader.
- Minority partitions → stalled safely, no wasted work.
- Delayed proposals → rejected cleanly.
Where Paxos showed consensus is possible, Raft made it practical.
Wrapping up the Series
Over this 3-part series, we followed Alice and Bob as they fought for a lock across a cluster of unreliable nodes. Along the way, we explored why consensus is such a difficult problem in distributed systems — and how algorithms like Paxos and Raft rise to the challenge.
- Part 1 showed the heart of the problem. Alice and Bob could both try to claim the lock, but Paxos’s majority-based rules ensured that once a value was chosen, it could never be undone. Even with crashes, restarts, or rejoining nodes, the system stayed safe.
- Part 2 dropped us into the messy reality of distributed systems: lost messages, competing proposers, network partitions, and delayed packets. Paxos kept safety intact in every case, but at the cost of liveness. Progress could stall, proposers could starve, and operators were left managing a protocol that was correct but difficult to reason about.
- Part 3 showed how Raft simplifies these same scenarios. By introducing a clear leader–follower model, Raft avoided wasted work in minority partitions, rejected stale proposals cleanly, ensured no commits were lost after crashes, and eliminated dueling proposers. The result: a protocol that’s both safe and understandable — one reason Raft has become the consensus algorithm of choice in many real-world systems.
The Bigger Lesson
Consensus isn’t just about picking a value. It’s about surviving the messiness of real distributed systems — crashes, partitions, delays — while keeping the system both safe and live.
- Paxos proved consensus is possible.
- Raft showed consensus can be practical.
For Alice and Bob, that means fewer battles and more predictable outcomes. For us, it means distributed systems we can trust to keep running, even when the world around them falls apart.
[story continues]
tags