Table of Links
4. Ablations on synthetic data
5. Why does it work? Some speculation
7. Conclusion, Impact statement, Environmental impact, Acknowledgements and References
A. Additional results on self-speculative decoding
E. Additional results on model scaling behavior
F. Details on CodeContests finetuning
G. Additional results on natural language benchmarks
H. Additional results on abstractive text summarization
I. Additional results on mathematical reasoning in natural language
J. Additional results on induction learning
K. Additional results on algorithmic reasoning
L. Additional intuitions on multi-token prediction
3. Experiments on real data
We demonstrate the efficacy of multi-token prediction losses by seven large-scale experiments. Section 3.1 shows how multi-token prediction is increasingly useful when growing the model size. Section 3.2 shows how the additional prediction heads can speed up inference by a factor of 3× using speculative decoding. Section 3.3 demonstrates how multi-token prediction promotes learning longer-term patterns, a fact most apparent in the extreme case of byte-level tokenization. Section 3.4 shows that 4-token predictor leads to strong gains with a tokenizer of size 32k. Section 3.5 illustrates that the benefits of multi-token prediction remain for training runs with multiple epochs. Section 3.6 showcases the rich representations promoted by pretraining with multi-token prediction losses by finetuning on the CodeContests dataset (Li et al., 2022). Section 3.7 shows that the benefits of multi-token prediction carry to natural language models, improving generative evaluations such as summarization, while not regressing significantly on standard benchmarks based on multiple choice questions and negative log-likelihoods.
To allow fair comparisons between next-token predictors and n-token predictors, the experiments that follow always compare models with an equal amount of parameters. That is, when we add n − 1 layers in future prediction heads, we remove n − 1 layers from the shared model trunk. Please refer to Table S14 for the model architectures and to Table S13 for an overview of the hyperparameters we use in our experiments.
3.1. Benefits scale with model size
To study this phenomenon, we train models of six sizes in the range 300M to 13B parameters from scratch on at least 91B tokens of code. The evaluation results in Figure 3 for MBPP (Austin et al., 2021) and HumanEval (Chen et al., 2021) show that it is possible, with the exact same computational budget, to squeeze much more performance out of large language models given a fixed dataset using multi-token prediction.
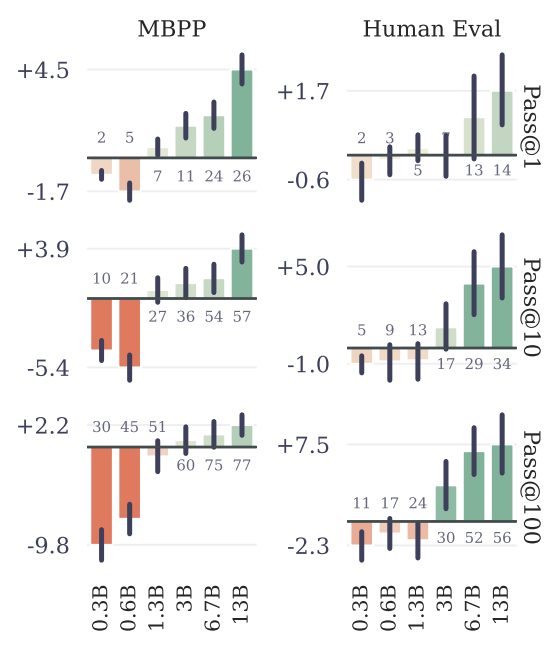
We believe this usefulness only at scale to be a likely reason why multi-token prediction has so far been largely overlooked as a promising training loss for large language model training.
3.2. Faster inference
We implement greedy self-speculative decoding (Stern et al., 2018) with heterogeneous batch sizes using xFormers (Lefaudeux et al., 2022) and measure decoding speeds of our best 4-token prediction model with 7B parameters on completing prompts taken from a test dataset of code and natural language (Table S2) not seen during training. We observe a speedup of 3.0× on code with an average of 2.5 accepted tokens out of 3 suggestions on code, and of 2.7× on text. On an 8-byte prediction model, the inference speedup is 6.4× (Table S3). Pretraining with multi-token prediction allows the additional heads to be much more accurate than a simple finetuning of a next-token prediction model, thus allowing our models to unlock self-speculative decoding’s full potential.
3.3. Learning global patterns with multi-byte prediction
To show that the next-token prediction task latches to local patterns, we went to the extreme case of byte-level tokenization by training a 7B parameter byte-level transformer on 314B bytes, which is equivalent to around 116B tokens. The 8-byte prediction model achieves astounding improvements compared to next-byte prediction, solving 67% more problems on MBPP pass@1 and 20% more problems on HumanEval pass@1.
Multi-byte prediction is therefore a very promising avenue to unlock efficient training of byte-level models. Selfspeculative decoding can achieve speedups of 6 times for the 8-byte prediction model, which would allow to fully compensate the cost of longer byte-level sequences at inference time and even be faster than a next-token prediction model by nearly two times. The 8-byte prediction model is a strong byte-based model, approaching the performance of token-based models despite having been trained on 1.7× less data.
3.4. Searching for the optimal n
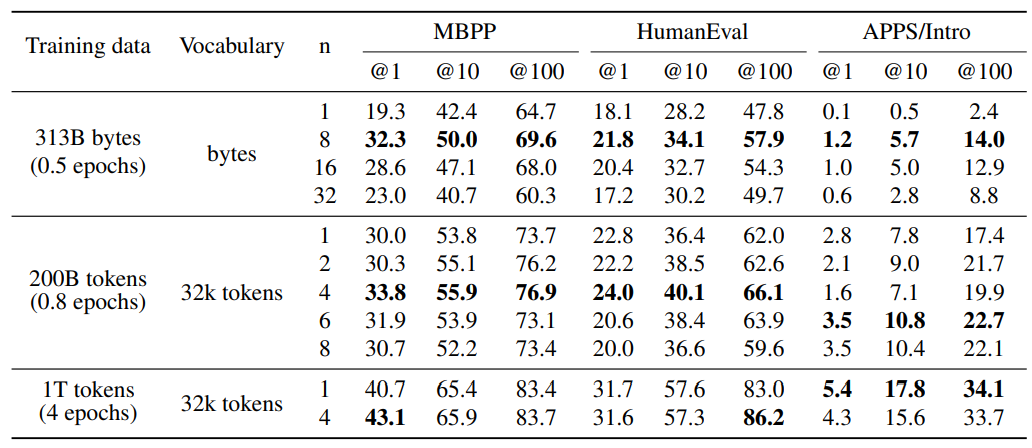
To better understand the effect of the number of predicted tokens, we did comprehensive ablations on models of scale 7B trained on 200B tokens of code. We try n = 1, 2, 4, 6 and 8 in this setting. Results in table 1 show that training with 4-future tokens outperforms all the other models consistently throughout HumanEval and MBPP for pass at 1, 10 and 100 metrics: +3.8%, +2.1% and +3.2% for MBPP and +1.2%, +3.7% and +4.1% for HumanEval. Interestingly, for APPS/Intro, n = 6 takes the lead with +0.7%, +3.0% and +5.3%. It is very likely that the optimal window size depends on input data distribution. As for the byte level models the optimal window size is more consistent (8 bytes) across these benchmarks.
3.5. Training for multiple epochs
Multi-token training still maintains an edge on next-token prediction when trained on multiple epochs of the same data. The improvements diminish but we still have a +2.4% increase on pass@1 on MBPP and +3.2% increase on pass@100 on HumanEval, while having similar performance for the rest. As for APPS/Intro, a window size of 4 was already not optimal with 200B tokens of training.
3.6. Finetuning multi-token predictors
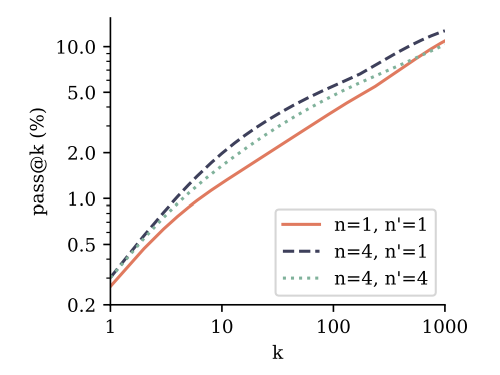
Pretrained models with multi-token prediction loss also outperform next-token models for use in finetunings. We evaluate this by finetuning 7B parameter models from Section 3.3 on the CodeContests dataset (Li et al., 2022). We compare the 4-token prediction model with the next-token prediction baseline, and include a setting where the 4-token prediction model is stripped off its additional prediction heads and finetuned using the classical next-token prediction target. According to the results in Figure 4, both ways of finetuning the 4-token prediction model outperform the next-token prediction model on pass@k across k. This means the models are both better at understanding and solving the task and at generating diverse answers. Note that CodeContests is the most challenging coding benchmark we evaluate in this study. Next-token prediction finetuning on top of 4-token prediction pretraining appears to be the best method overall, in line with the classical paradigm of pretraining with auxiliary tasks followed by task-specific finetuning. Please refer to Appendix F for details.
3.7. Multi-token prediction on natural language
To evaluate multi-token prediction training on natural language, we train models of size 7B parameters on 200B tokens of natural language with a 4-token, 2-token and next-token prediction loss, respectively. In Figure 5, we evaluate the resulting checkpoints on 6 standard NLP benchmarks. On these benchmarks, the 2-future token prediction model performs on par with the next-token prediction baseline
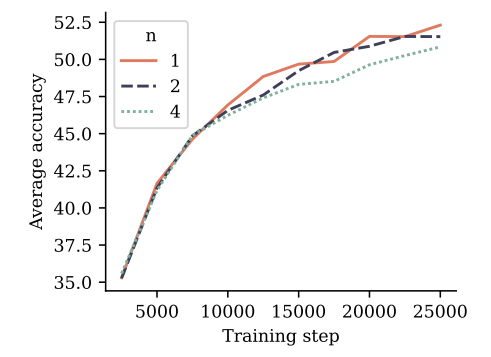
throughout training. The 4-future token prediction model suffers a performance degradation. Detailed numbers are reported in Appendix G.
However, we do not believe that multiple-choice and likelihood-based benchmarks are suited to effectively discern generative capabilities of language models. In order to avoid the need for human annotations of generation quality or language model judges—which comes with its own pitfalls, as pointed out by Koo et al. (2023)—we conduct evaluations on summarization and natural language mathematics benchmarks and compare pretrained models with training sets sizes of 200B and 500B tokens and with nexttoken and multi-token prediction losses, respectively.
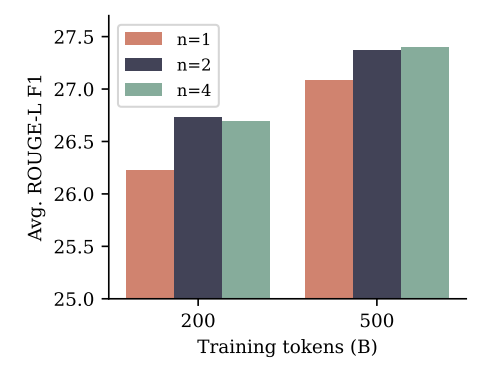
For summarization, we use eight benchmarks where ROUGE metrics (Lin, 2004) with respect to a ground-truth summary allow automatic evaluation of generated texts. We finetune each pretrained model on each benchmark’s training dataset for three epochs and select the checkpoint with the highest ROUGE-L F1 score on the validation dataset. Figure 6 shows that multi-token prediction models with both n = 2 and n = 4 improve over the next-token baseline in ROUGE-L F1 scores for both training dataset sizes, with the performance gap shrinking with larger dataset size. All metrics can be found in Appendix H.
For natural language mathematics, we evaluate the pretrained models in 8-shot mode on the GSM8K benchmark (Cobbe et al., 2021) and measure accuracy of the final answer produced after a chain-of-thought elicited by the fewshot examples. We evaluate pass@k metrics to quantify diversity and correctness of answers like in code evaluations
and use sampling temperatures between 0.2 and 1.4. The results are depicted in Figure S13 in Appendix I. For 200B training tokens, the n = 2 model clearly outperforms the next-token prediction baseline, while the pattern reverses after 500B tokens and n = 4 is worse throughout.
Authors:
(1) Fabian Gloeckle, FAIR at Meta, CERMICS Ecole des Ponts ParisTech and Equal contribution;
(2) Badr Youbi Idrissi, FAIR at Meta, LISN Université Paris-Saclayand and Equal contribution;
(3) Baptiste Rozière, FAIR at Meta;
(4) David Lopez-Paz, FAIR at Meta and a last author;
(5) Gabriel Synnaeve, FAIR at Meta and a last author.
This paper is
[story continues]
tags