GitHub is more than just a platform for hosting repositories—it’s a highly scalable distributed system that processes millions of transactions daily. From handling git push requests to computing file differences efficiently, GitHub relies on robust algorithms and architecture to ensure high performance and reliability.
This article explores how GitHub processes vast amounts of data, scales to handle millions of transactions, and employs diff algorithms to track file changes efficiently. The article also includes detailed JavaScript implementations of core algorithms used in version control systems.
1. The Challenges of Large-Scale Version Control Systems.
Modern version control systems must deal with several key challenges:
- Processing millions of transactions per day, including commits, merges, and pull requests.
- Efficiently computing differences between files, which is critical for version tracking and merging.
- Scaling storage and processing power, ensuring fast response times for developers worldwide.
These principles are not exclusive to GitHub. Similar architectures and algorithms are used in GitLab, Bitbucket, and other platforms that deal with version control at scale.
2. How GitHub Computes File Differences (Diff Algorithm Implementation in JavaScript)
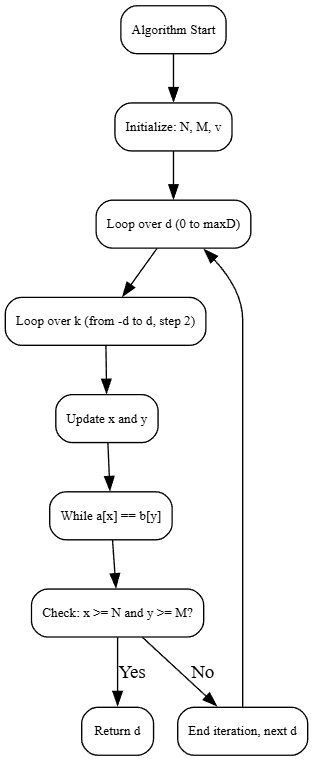
When tracking changes in a file, GitHub (and Git itself) uses diff algorithms to compute the minimum number of edits needed to transform one version of a file into another. A widely used algorithm for this is Myers’ Diff Algorithm.
2.1. How Myers’ Algorithm Works.
Myers’ algorithm finds the shortest sequence of insertions and deletions required to convert one file into another. It operates by iterating through possible edit distances (d) and computing possible transformations along “diagonals” in the edit graph.
2.2. JavaScript Implementation of Myers’ Algorithm.
/**
* Computes the minimum edit distance between two arrays using Myers' Diff Algorithm.
* @param {Array} a - The original array (e.g., characters of a file)
* @param {Array} b - The modified array
* @returns {number} The minimum number of edit operations required
*/
function myersDiff(a, b) {
const N = a.length;
const M = b.length;
const maxD = N + M;
let v = {
1: 0
};
for (let d = 0; d <= maxD; d++) {
for (let k = -d; k <= d; k += 2) {
let x;
if (k === -d || (k !== d && (v[k - 1] || 0) < (v[k + 1] || 0))) {
x = v[k + 1] || 0;
} else {
x = (v[k - 1] || 0) + 1;
}
let y = x - k;
while (x < N && y < M && a[x] === b[y]) {
x++;
y++;
}
v[k] = x;
if (x >= N && y >= M) {
return d;
}
}
}
return maxD;
}
// Example usage:
const oldVersion = Array.from("Hello World");
const newVersion = Array.from("Hello GitHub World");
const operations = myersDiff(oldVersion, newVersion);
console.log(`Minimum number of edits: ${operations}`);
Breakdown of the code:
-
Initialization: The algorithm initializes an array v to store the maximum x values for each diagonal in the edit graph.
-
Loop through possible edit distances (d): Iterates through each possible number of edits needed.
-
Computing the optimal path: Determines whether to insert or delete based on v[k] values.
-
“Greedy match” step: Moves diagonally as long as characters match, minimizing unnecessary operations.
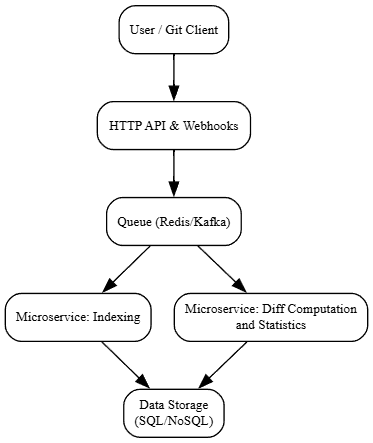
3. GitHub’s Transaction Processing Architecture.
To handle millions of transactions, GitHub employs a multi-layered architecture. Here’s how a typical transaction flows:
- Receiving the request: API and Webhooks receive transactions (git push, git pull, etc.).
- Queueing the request: Transactions are placed in a distributed queue (Redis/Kafka) for parallel processing.
- Processing in microservices: Dedicated services handle indexing, diff computation, and statistics updates.
- Updating storage: Results are committed to a database (SQL/NoSQL) and cached for quick access.
This architecture allows GitHub to scale efficiently, ensuring that no single component becomes a bottleneck

4. JavaScript Implementation of GitHub-Like Transaction Processing.
GitHub processes transactions asynchronously to handle high traffic. The following JavaScript code simulates parallel processing of transactions using Promises.
/**
* Simulates a transaction in a version control system.
*/
class Transaction {
constructor(id, action, payload) {
this.id = id;
this.action = action;
this.payload = payload;
}
}
/**
* Simulates processing a transaction step-by-step.
* @param {Transaction} tx - The transaction to process
* @returns {Promise<string>} The result of processing
*/
function processTransaction(tx) {
return new Promise((resolve) => {
console.log(`Processing transaction ${tx.id}: ${tx.action}`);
setTimeout(() => {
console.log(`Indexing ${tx.id}...`);
setTimeout(() => {
console.log(`Computing diff for ${tx.id}...`);
setTimeout(() => {
console.log(`Updating database for ${tx.id}...`);
resolve("success");
}, 100);
}, 50);
}, 100);
});
}
/**
* Simulates processing multiple transactions in parallel.
*/
async function processTransactions() {
const transactions = [
new Transaction("tx001", "commit", "Modified file A"),
new Transaction("tx002", "commit", "Fixed bug in file B"),
new Transaction("tx003", "merge", "Merged branches"),
];
const promises = transactions.map(async (tx) => {
const result = await processTransaction(tx);
console.log(`Transaction ${tx.id} result: ${result}`);
});
await Promise.all(promises);
console.log("All transactions processed.");
}
// Run transaction processing
processTransactions();
Key takeaways from this code:
- Asynchronous processing: Transactions run in parallel using Promise.all().
- Step-by-step simulation: Each transaction follows the same processing flow—indexing, computing diffs, and updating storage.
- Scalability: Similar principles apply in real-world systems like GitHub, where Redis/Kafka queues help distribute workloads across microservices.

5. Conclusion: GitHub’s Scalable Approach to Version Control.
GitHub’s ability to process millions of transactions per day relies on a combination of:
- Optimized diff algorithms, like Myers’ Algorithm, to efficiently compute file changes.
- Scalable distributed architecture, using microservices and message queues to balance workload.
- Parallel transaction processing, ensuring fast responses even under heavy loads.
These techniques aren’t exclusive to GitHub—they are widely used in GitLab, Bitbucket, and large-scale data processing systems. Understanding these principles helps developers build efficient, scalable applications for handling high volumes of transactions.
[story continues]
tags