The total perspective vortex
Containerizing the best code in the world means nothing if that container does not have the resources to do its job.
The idea for this story started while writing about effective container probes. It became clear that returning accurate responses to kubelet inquiries was only the first part of the solution.
The second part is the subject of this article: allocating resources to containers, but exploring the entire landscape of resource allocation, from a single container in a Kubernetes pod to near-infinite capacity in the cloud.
Kubernetes resource management: a recap
“How to ensure containers always have the resources they need?”
Consider this section a recap for those just starting with Kubernetes resource management. The official documentation on Kubernetes resource management for containers and namespace limit ranges is still mandatory reading in the space. If you are already familiar with the subject, skip to the next section.
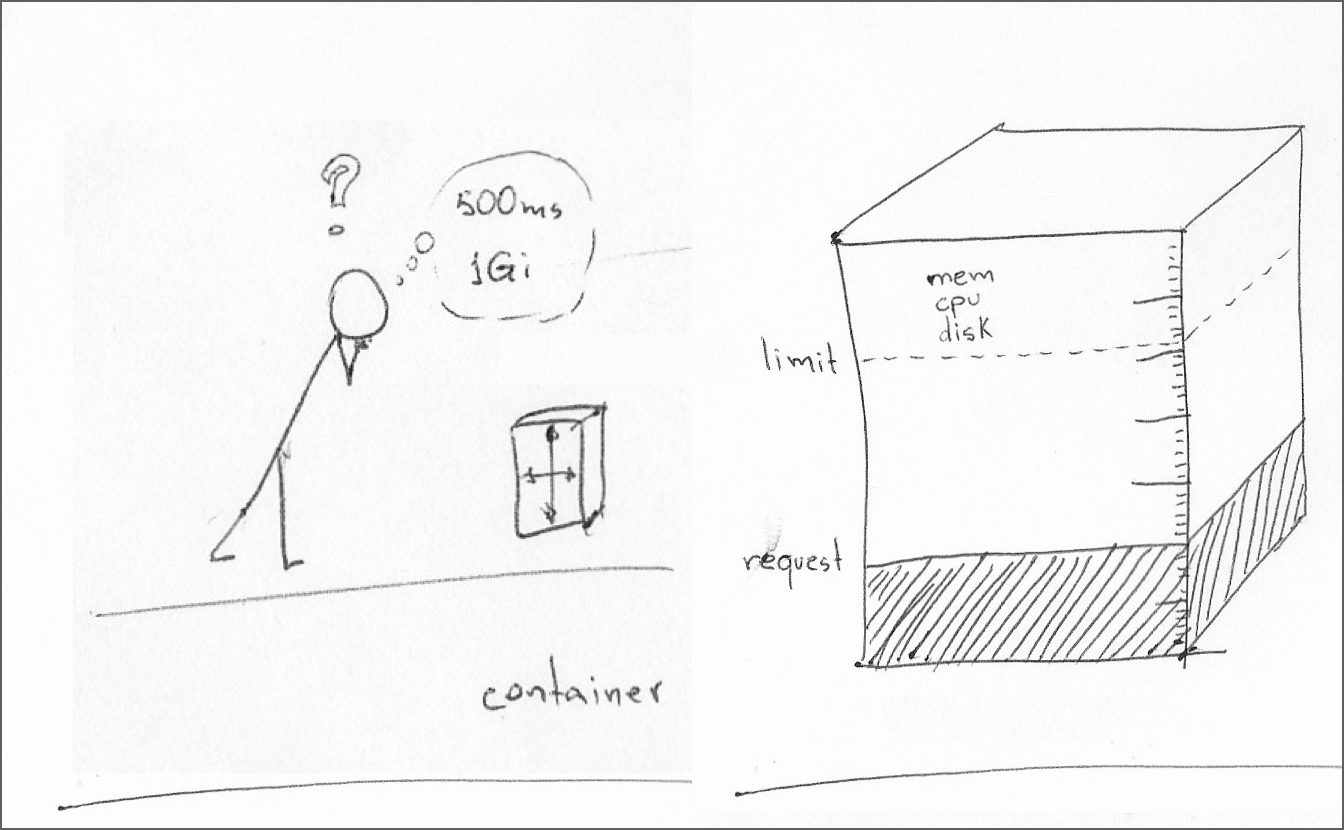
Kubernetes resource management primarily covers CPU, memory, and local ephemeral storage. A container specification may define resource requests and resource limits for each resource type.
A resource request is the minimum resource amount required for the container runtime. The node scheduler only schedules a pod on a node if that node can meet that minimum request for all containers in the pod.
A resource limit is the maximum amount of resources the kubelet should allocate to a container during its lifetime. When a container has the resource limit set but not a resource request, that is equivalent to setting the resource request to the same value as the resource limit.
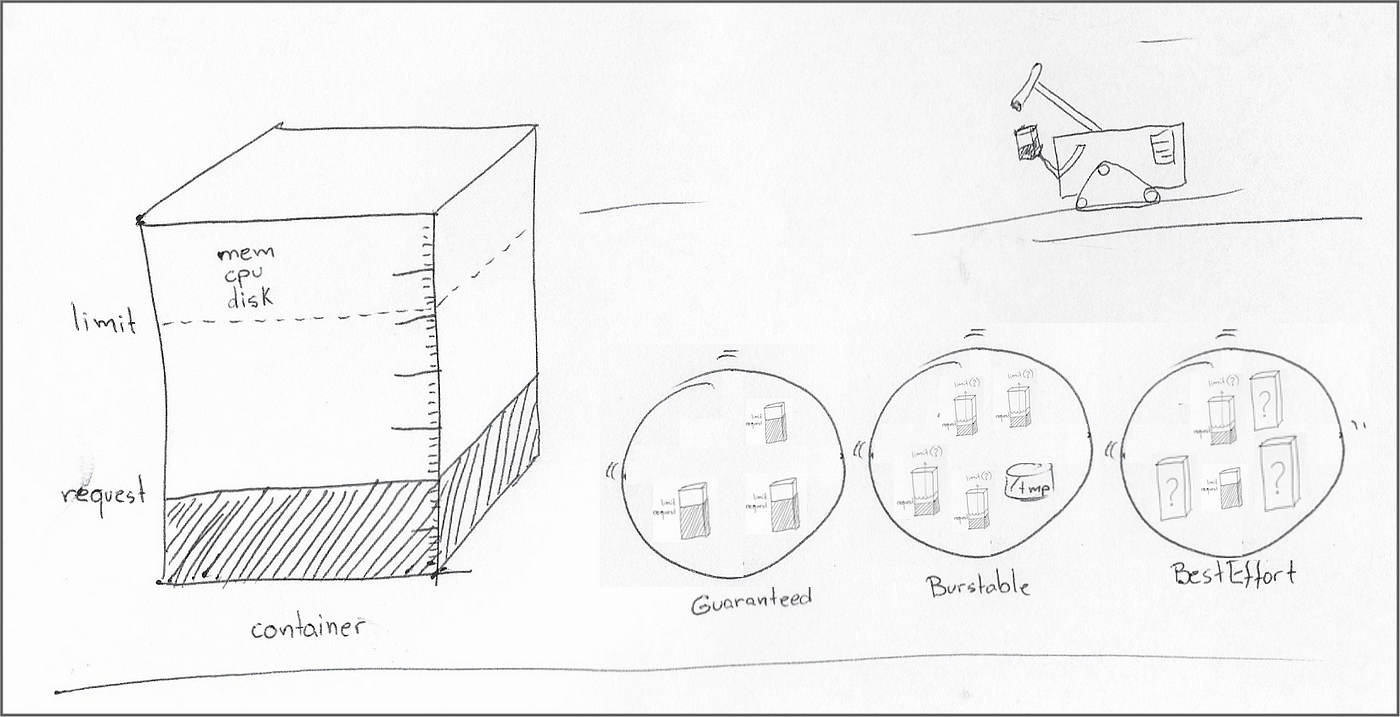
Kubernetes allows software developers and system administrators to collaborate on setting minimum reservations and maximum limits for resources like CPU, memory, and temporary storage. A container may have any combination of resource requests and limits, with the different combinations of CPU and memory reservations defining the quality of service for the parent pod as follows:
-
Every container in the pod has both resource request and limit set, and for each container, request and limit have the same value: Guaranteed.
-
Resource request or limit not set in at least one of the containers in the pod: BestEffort.
-
All other pods that are not in the two previous buckets: Burstable.
It is helpful to look at what these categories mean when thekube-scheduler decides to schedule a pod on a worker node:
-
“Guaranteed” means the scheduler only assigns the pod to worker nodes with enough resources to meet the requests of all containers in the pod.
-
“Burstable” QoS means the scheduler looks for a worker node with enough memory to meet the resource requests of all containers in the pod. The scheduler does not care whether the worker node can meet the resource limits of containers in the pod or anything above the resource request, for that matter.
-
“BestEffort” means the scheduler will first meet the resource requests of every pod with a “Guaranteed” or “Burstable” QoS before scheduling a “BestEffort” pod. The scheduler continuously revisits that assessment, so it may still mark a “BestEffort” pod for eviction if a “Guaranteed” or “Burstable” pod needs those same resources.
Decision time: Who should define container resources?
We must first understand that resource requests protect the container while resource limits protect the cluster.
The two main parties in that decision are product developers and system administrators. That “negotiation” amongst them is somewhat challenging because it is spread over time:
-
Product developers spend most of the time establishing resource boundaries in isolation from deployment to production environments.
-
System administrators often deal with Kubernetes workload specifications with insufficient documentation on how changes in preset requests and limits affect the workloads.
Product developers have greater visibility into the needs of the workloads and their behavior under different resource allocations. In general, they should be able to identify the following thresholds ahead of shipment:
-
Absolute minimum resource request. This value is the resource utilization required to load the runtime and be able to answer probe requests from the kubelet comfortably. This article shows several PromQL queries to identify troubled containers.
-
Maximum usable resource limit. This value is the point where the performance of the container starts to hit external limitations, such as disk I/O or bottlenecks in calls to 3rd party services.
I also encourage a look at Natan Yellin’s blog post titled “You can’t have both high utilization and high reliability”, examining important trade-offs related to the definition of resource requests and limits.

Ideally, product developers should also establish and document how container performance varies within those boundaries. That information enables system architects to plan initial capacity before deployment and system administrators to adjust resource requests in production environments.
Quotas, ranges, and the tragedy of the commons
System administrators have visibility into cluster capacity and how much of that capacity is still available. As someone who occasionally wears an SRE hat, I appreciate workloads in the “Guaranteed” QoS bucket. It takes a special kind of confidence (and lots of testing) for a development organization to set fixed resource boundaries on all containers in a pod and trust that pod to work reliably within those boundaries.
“Burstable” workloads fall somewhat lower in that spectrum of trust. When wearing my SRE hat, my best hope is that all containers in a burstable pod have those “absolute minimum” resource requests mentioned in the previous section.
When it comes to resource limits in a burstable workload, my opinion depends on the development philosophy behind those limits:
-
(good) Autoscaling within the workload (such as a Java Virtual Machine launched with minimum and maximum memory limits.) This kind of arrangement (resource limit set higher than the resource request) means the development team spent time identifying the usable operational range of the workload and has a good grip on managing those resources.
-
(bad) Protection against eventual bugs. This design philosophy reminds me of the “tragedy of the commons,” where everyone takes a bit more of a shared resource to anticipate its eventual exhaustion, accelerating the exhaustion of the shared resource. That philosophy is particularly disastrous when the development team underestimates the resource requests. In that situation, the workload continuously operates in the burstable zone of its operational range, making it susceptible to CPU throttling, memory exhaustion, and termination by the kubelet in the worker node.
And that finally leaves us with “BestEffort” workloads, a perennial source of worries due to their unfettered ability to exhaust cluster resources and their tenuous scheduling status in the face of other pods requesting those same resources.
When dealing with these types of workloads, a system administrator must take a moment to consider their options:
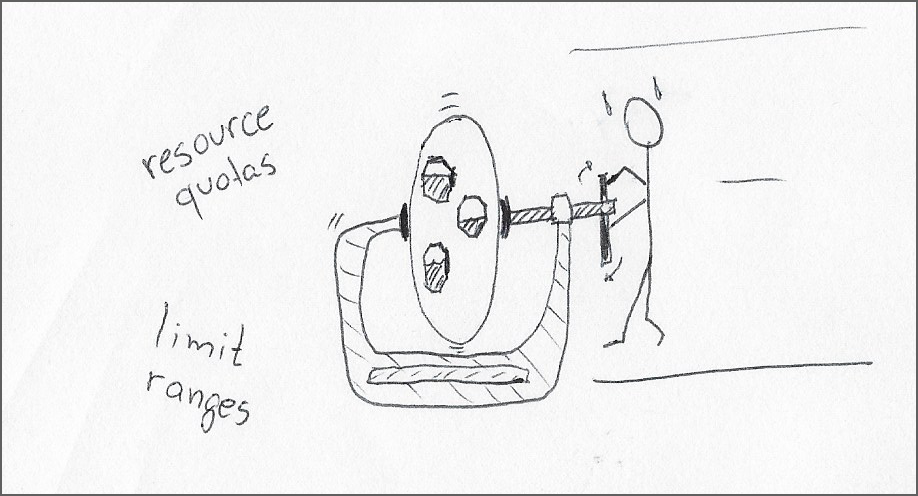
1. Use limit ranges to set default resource requests and limits for containers and pods in a namespace. I think the blanket assignment of identical resource limits for all workloads across the namespace, combined with the lack of input from the product developers, makes it an unrealistic proposition.
2. Use resource quotas to cap the combined resources for all pods in a namespace. This approach is a more promising solution. It reduces the “blast radius” of an eventual container going haywire to that namespace, with the advantage of avoiding the waste of multiplying the resource safety buffer by the number of pods in the namespace.
3. Take a deep breath and hope for relief from the pod autoscaling technologies covered in the next section.
Pod autoscaling: Beyond static sizing
Many readers are probably ready to bring up the usual workarounds for dealing with unruly workloads:
- Horizontal pod autoscaling (HPA)
- Vertical pod autoscaling (VPA)
These popular autoscaling techniques can dynamically allocate capacity within a cluster based on resource metrics; HPA can alter the number of pod replicas in a deployment, while VPA can change the resource requests and limits for a pod — Note that until this Kubernetes Enhancement Proposal is added to Kubernetes, VPA changes to a pod result in the pod being restarted.
While capable of automatically extending capacity, these components are not a free pass to forego the precise definition of the operational ranges for their workloads. For instance, HPA will not take action on a metric where containers in the pod do not have the resource request for that metric. HPA is also ill-suited to scenarios where a deployment relies on a specific number of replicas for the pod in the cluster.
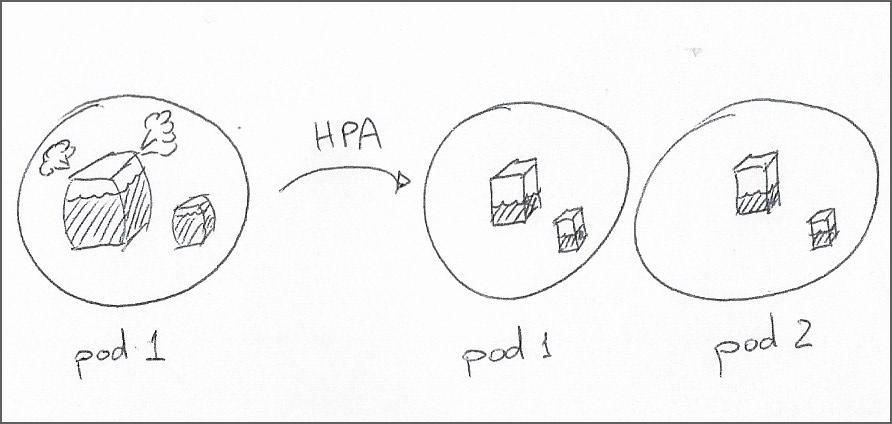
Turning to VPA is better for workloads that require a fixed number of replicas or where the workload does not ship with preset limits. There is, however, a relatively long list of limitations. Additionally, if using limit ranges, the considerations may get quite involved.
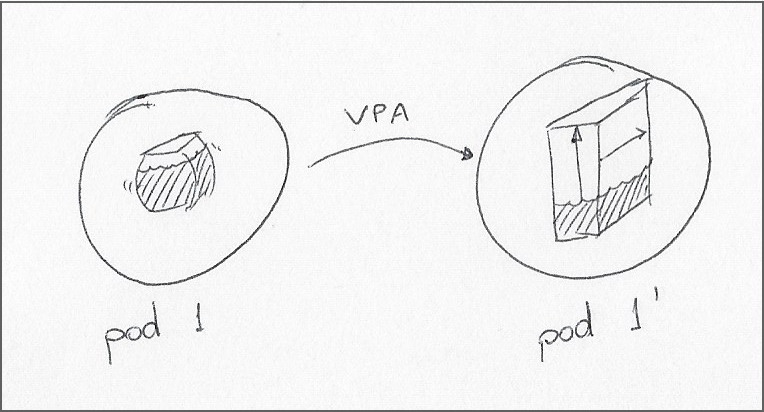
Ultimately, the effectiveness of these tools in autoscaling workloads depends on the profiling effort spent on defining well-researched resource requests and limits during development. Here, I must give VPA extra credit for its ability to “learn” the operational resource ranges for a deployment.
Auto Pilot operators: SRE in a box?
Kubernetes operators introduce the notion of custom resources to manage applications and workloads. Conceptually, an operator continuously watches a custom resource and maps its contents to workload resources.
The Operator Maturity Model calls for five different levels of autonomy, with the highest being level 5, or “Auto Pilot.” An operator at that stage of maturity should, amongst other kinds of autonomous behavior, apply horizontal or vertical scaling to the workloads it manages.
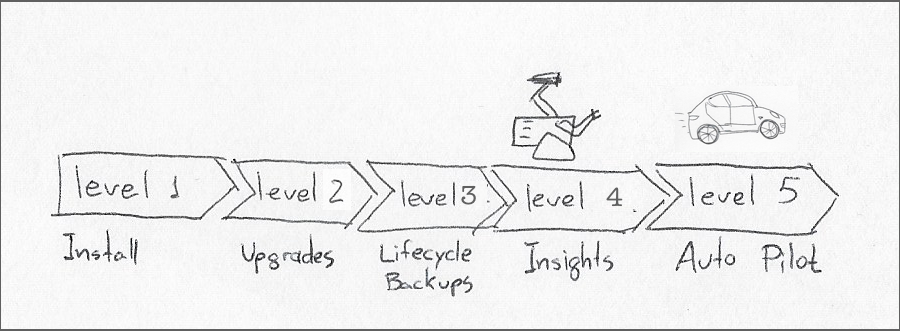
There is a natural extra cost in developing an operator, including designing and documenting custom resource definitions. There is also the additional runtime cost of the operator pod. That is why I think the value of operators starts to offset its costs only at level 4, or “Deep Insights,” which entails generating metrics, issuing alerts, workload analysis, and others.
Below level 4, operators do little to alleviate the continuous cycle of product developers attempting to predict the future and system administrators trying to bend those predictions into reality.
Knative: Elastic capacity with zero waste
According to its website, Knative “is an Open-Source Enterprise-level solution to build Serverless and Event-Driven Applications.”
From the perspective of this article, we are interested in Knative’s Serving module. That module contains the Knative Pod Autoscaler (KPA,) which mimics HPA’s ability to vary the number of pod replicas to meet demand, with two key distinctions:
-
Scale replicas based on the volume of external requests
-
Scale replicas down to zero when there are no external requests
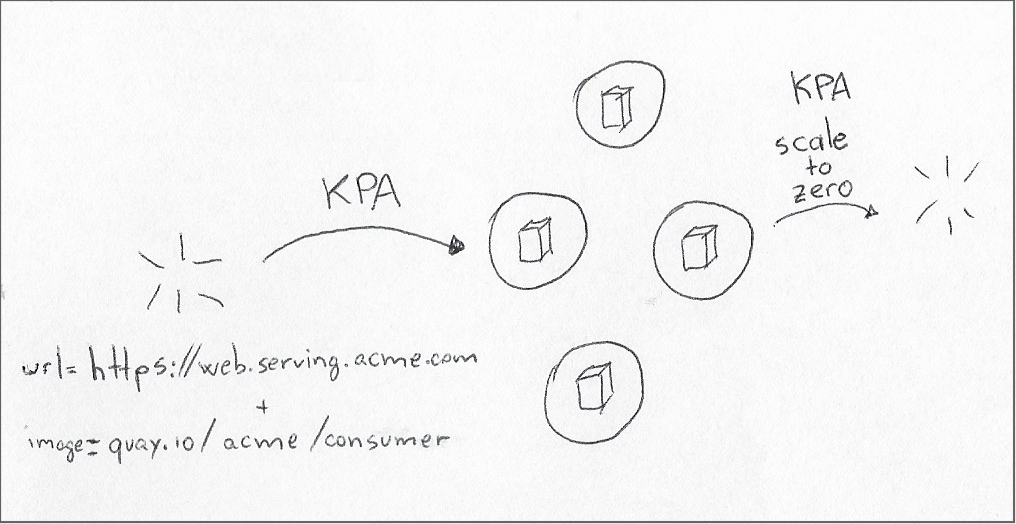
Unlike HPA, which reacts to resource utilization when it crosses preset boundaries, KPA makes its decisions based on concurrency and requests-per-second targets.
As a rule of thumb, HPA is better suited for long-running, slow-starting processes where resource demands do not change abruptly. In contrast, KPA favors transient processes that can boot quickly to meet immediate demand.
And last but not least, serverless or not, KPA works with containers, so resource limits still matter.
Cluster autoscaling: Pushing the limits
Once you have appropriately tuned all workload resources and pod autoscalers, it is time to look deeper into the toolbox and reach for the Kubernetes cluster autoscaler.
The cluster autoscaler can add (or remove) worker nodes based on resource demands. The autoscaler respects configurable lower and upper boundaries to ensure minimum capacity and some level of cost controls to avoid unruly workloads overstretching the cluster.
Slow stretching. Keep in mind that response times for a cluster autoscaler are decidedly sluggish compared to pod autoscalers, with a worker node taking several minutes to become available to the Kube-scheduler.
Suppose you need a cluster autoscaler to work with peak demands. In that case, you must resort to deploying a sacrificial buffer of “pause pods” (described in the cluster autoscaler documentation.) When new workloads need those resources, the Kube-scheduler immediately evicts the pause pods to free up resources. The cluster later scales up the number of nodes to reallocate the evicted pods.
Note that Kubernetes taints and tolerations also play a role in how autoscalers do their work, making tainted worker nodes off-limits for the placement of pods without tolerance for those taints.
Serverless: Limitless capacity…with limits
For the ultimate level of autoscaling, it is time to abandon the boundaries of a cluster — even Kubernetes has limits — and look at serverless capabilities at the cloud provider level.
Major cloud providers can spin up container images on demand based on multiple events, such as web requests, database operations, and timers. Compared to a single cluster, the resource capacity of a cloud provider is virtually unlimited, and the cost of running a container for a few moments is almost negligible compared to running the same workload inside a cluster.
Ironically, despite an ultra-low-cost per invocation, serverless approaches make you switch from worrying about resource limits to worrying about cost overruns:
- Container limits still matter: Cloud providers require you to indicate the number of CPUs and the amount of memory for each container invocation.
- Budget limits: Where a bug in a test suite may exhaust cluster capacity, that same bug in a serverless deployment may erase your entire department’s budget overnight.
You may find several variants of serverless offerings, such as handing a small function to the cloud engine rather than an entire container image or letting the cloud provider use one of your managed clusters to run the containers (trading scale for security.)
For added convenience, many of these offerings can start from a Git repository containing a Dockerfile, which they use to build and cache the container image before scheduling workloads referencing that image.

Conclusion
We covered the entire spectrum of resource allocation for a workload, from tuning a single container to hyperscaling a workload outside Kubernetes.
The article started with a recap of Kubernetes resource management and its core concepts of resource requests and limits. We then built upon those static limits into the realm of pod autoscalers: HPA, VPA, and KPA.
From pod autoscalers’ ability to efficiently utilize a cluster’s maximum capacity, we moved on to increase that capacity with cluster autoscaling. We then completed the total perspective vortex with virtually unlimited resources (and costs) in the form of serverless offerings across cloud providers.
Except for VPA, these techniques still build upon reasonable effort to determine a container’s resource consumption during development activities. For example, HPA does not take action based on resources where the limits are not specified, while cloud providers outright ask for the CPU and memory resources assigned to each container run.
With the landscape of resource scaling out of the way, my next article on this topic will cover concrete techniques to identify resource requests and limits during development and keep a watchful eye on them in production.
References
- Practical Kubernetes — Top Ten Challenges — Part 6: Sizing and Footprint Optimization, by Andre Tost
- You can’t have both high utilization and high reliability, by Nathan Yellin
- Vertical Pod Autoscaler deep dive, limitations and real-world examples
- Vertical Pod Autoscaling: The Definitive Guide
- Kubernetes Workload Resources
- IBM Code Engine (Managed Knative)
Also published here.
[story continues]
tags