Table of Links
-
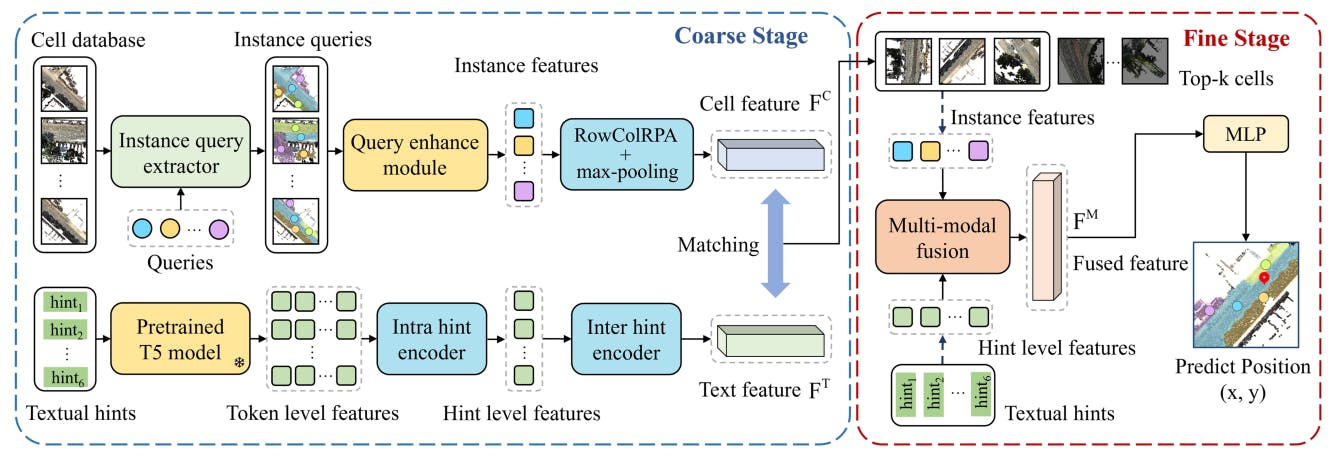
Method
-
Experiments
-
Performance Analysis
Supplementary Material
- Details of KITTI360Pose Dataset
- More Experiments on the Instance Query Extractor
- Text-Cell Embedding Space Analysis
- More Visualization Results
- Point Cloud Robustness Analysis
Anonymous Authors
- Details of KITTI360Pose Dataset
- More Experiments on the Instance Query Extractor
- Text-Cell Embedding Space Analysis
- More Visualization Results
- Point Cloud Robustness Analysis
Anonymous Authors
- Details of KITTI360Pose Dataset
- More Experiments on the Instance Query Extractor
- Text-Cell Embedding Space Analysis
- More Visualization Results
- Point Cloud Robustness Analysis
2 RELATED WORK
2.1 3D Place Recognition
3D place recognition aims to match a query image or LiDAR scan of a local region against a database of 3D point clouds to determine the location and orientation of the query relative to a reference map. This technique can be categorized into two approaches, i.e., dense-point based and sparse-voxel based [46]. Specifically, PointNetVLAD [36] represents a foundational work in the dense-point stream, extracting features with PointNet [29] and aggregating them into a global descriptor via NetVLAD [2]. With the advent of transformer [38], many studies [12, 15, 25, 53] have leveraged attention mechanisms to highlight significant local features for place recognition. In contrast, voxel-based methods start by voxelizing 3D point clouds, improving the robustness and efficiency. MinkLoc3D [22] extracts the local features from sparse voxelized point clouds using a feature pyramid network, followed by pooling to form a global descriptor. However, voxelization can lead to local information loss. Addressing this, CASSPR [41] combines voxelbased and point-based advantages with a dual-branch hierarchical cross-attention transformer. Breaking away from conventional point cloud query reliance, our method employs natural language descriptions to specify target locations, offering a novel direction in 3D localization.
2.2 Language-based 3D Localization
Language-based 3D localization aims to determine a position in a city-scale 3D point cloud map based on a language description. Text2Pos [21] pioneers this field by dividing the map into cells and employing a coarse-to-fine methodology, which initially identifies approximate locations via retrieval and subsequently refines pose estimation through regression. The coarse stage matches cell features and description features in a shared embedding space, while the fine stage conducts instance-level feature matching and calculates positional offsets for final localization. However, this method overlooks the relationships among hints and point cloud instances. Addressing this gap, RET [39] incorporates relation-enhanced self-attention to analyze both hint and instance connections, and employs crossattention in regression to improve multi-modal feature integration. Text2Loc [42] leverages the T5 [33] pre-trained language model and a hierarchical transformer for improved text embedding and introduces a matching-free fine localization approach, leveraging a cascaded cross-attention transformer for superior multi-modal fusion. By utilizing contrastive learning, Text2Loc significantly outperforms existing models in accuracy. Nonetheless, current methods depend on ground-truth instances as input, which are costly for new environments, and fail to fully leverage relative position information.
2.3 Understanding of 3D Vision and Language
In the realm of 3D vision and language understanding, significant strides have been made in indoor scenarios [17, 44, 47, 48]. ScanRefer [5] and Referit3D [1] set the initial benchmarks for 3D visual grounding through the alignment of object annotations with natural language descriptions on ScanNet [11]. Follow-up research [40, 45, 50] improve the performance by incorporating additional features like 3D instance features, 2D prior features, and parsed linguistic features to enhance performance. 3D dense captioning [7] emphasizes the detailed description of object attributes and has further been refined by integrating various 3D comprehension techniques [3, 6, 49]. Conversely, the outdoor domain remains relatively untapped, with most existing datasets [20, 26, 28] reliant on 2D inputs. Recently, the TOD3Cap [18] dataset brings 3D dense captioning into outdoor scenarios. The corresponding model leverages 2D-3D representations and combines Relation Q-Former with LLaMA-Adapter [51] to produce detailed captions for objects. Different from existing works, we focus on the outdoor city-scale text-to-point-cloud localization task, aiming to bridge the gap in outdoor 3D vision and language integration.
Authors:
(1) Lichao Wang, FNii, CUHKSZ (wanglichao1999@outlook.com);
(2) Zhihao Yuan, FNii and SSE, CUHKSZ (zhihaoyuan@link.cuhk.edu.cn);
(3) Jinke Ren, FNii and SSE, CUHKSZ (jinkeren@cuhk.edu.cn);
(4) Shuguang Cui, SSE and FNii, CUHKSZ (shuguangcui@cuhk.edu.cn);
(5) Zhen Li, a Corresponding Author from SSE and FNii, CUHKSZ (lizhen@cuhk.edu.cn).
This paper is
[story continues]
tags