
Table of Links
Supplementary Material
-
Image matting
-
Video matting
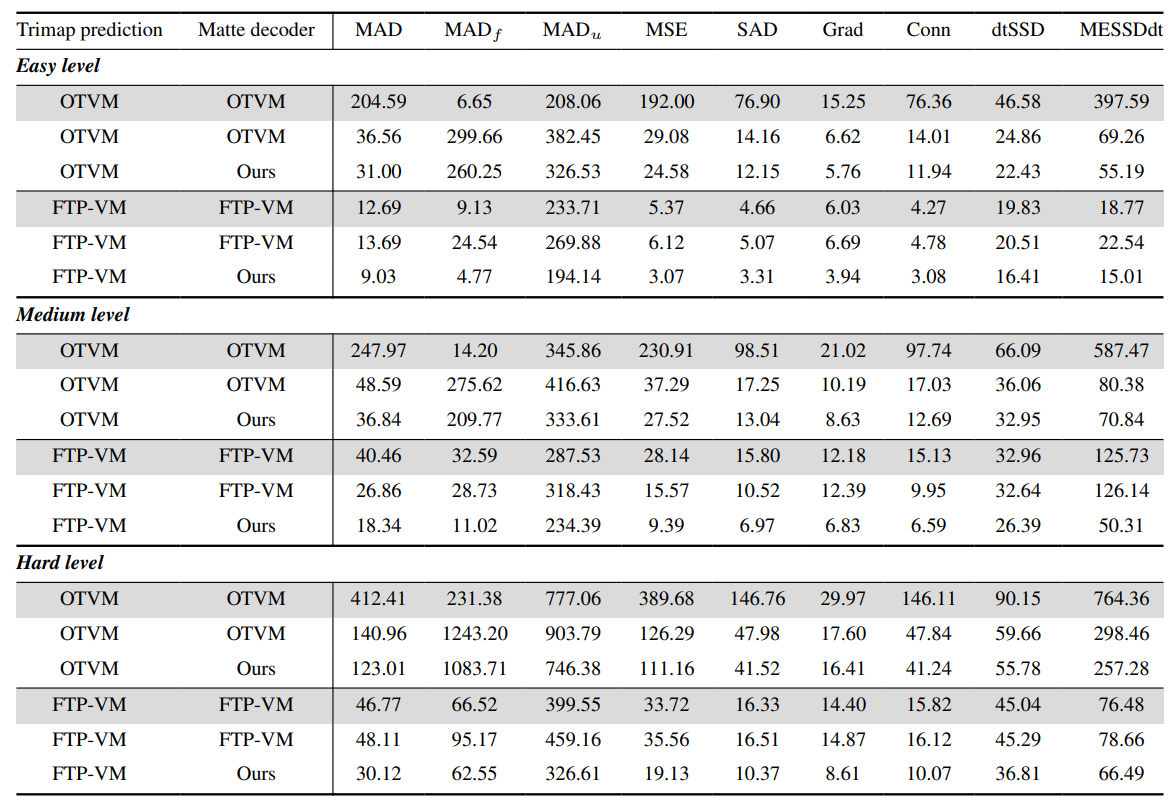
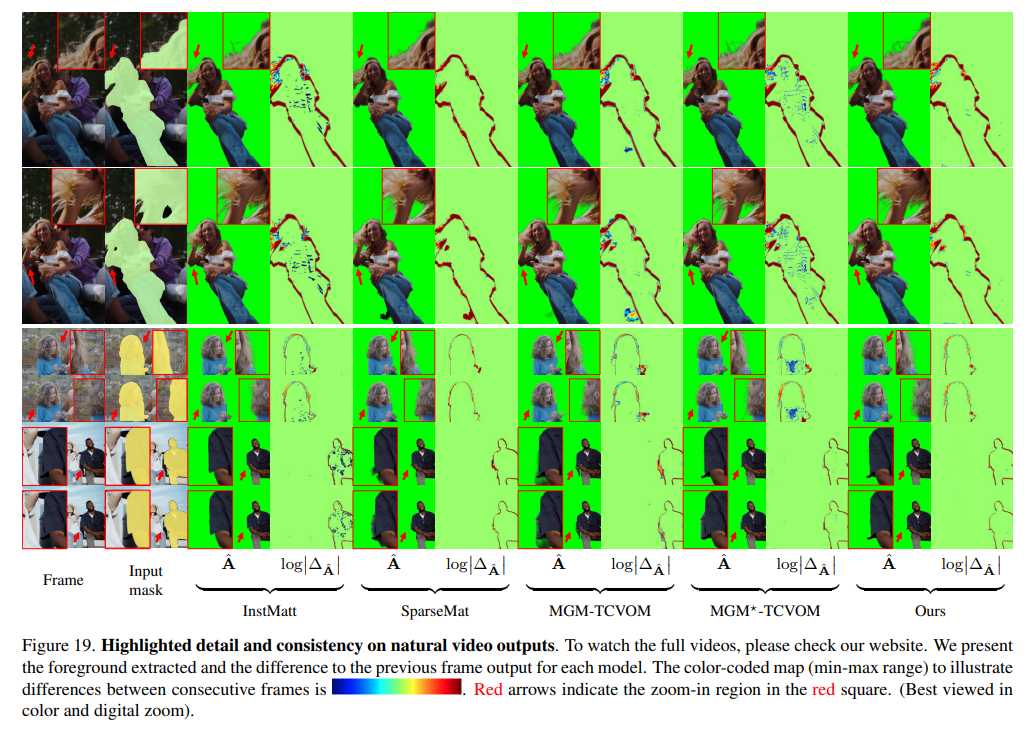
9.4. More qualitative results
For a more immersive and detailed understanding of our model’s performance, we recommend viewing the examples on our website which includes comprehensive results and comparisons with previous methods. Additionally, we have highlighted outputs from specific frames in Fig. 19.
Regarding temporal consistency, SparseMat and our framework exhibit comparable results, but our model demonstrates more accurate outcomes. Notably, our output maintains a level of detail on par with InstMatt, while ensuring consistent alpha values across the video, particularly in background and foreground regions. This balance between detail preservation and temporal consistency highlights the advanced capabilities of our model in handling the complexities of video instance matting.
For each example, the first-frame human masks are generated by r101 fpn 400e and propagated by XMem for the rest of the video.

Authors:
(1) Chuong Huynh, University of Maryland, College Park (chuonghm@cs.umd.edu);
(2) Seoung Wug Oh, Adobe Research (seoh,jolee@adobe.com);
(3) Abhinav Shrivastava, University of Maryland, College Park (abhinav@cs.umd.edu);
(4) Joon-Young Lee, Adobe Research (jolee@adobe.com).
This paper is
[story continues]
tags