Overview
- VLANeXt identifies the key design choices that make vision-language-action models effective for robot learning
- The research breaks down model building into three critical areas: foundational components, perception, and action modeling
- Strong architectural decisions across all three areas compound to create models that work well in practice
- The paper provides concrete guidance rather than presenting a single novel technique
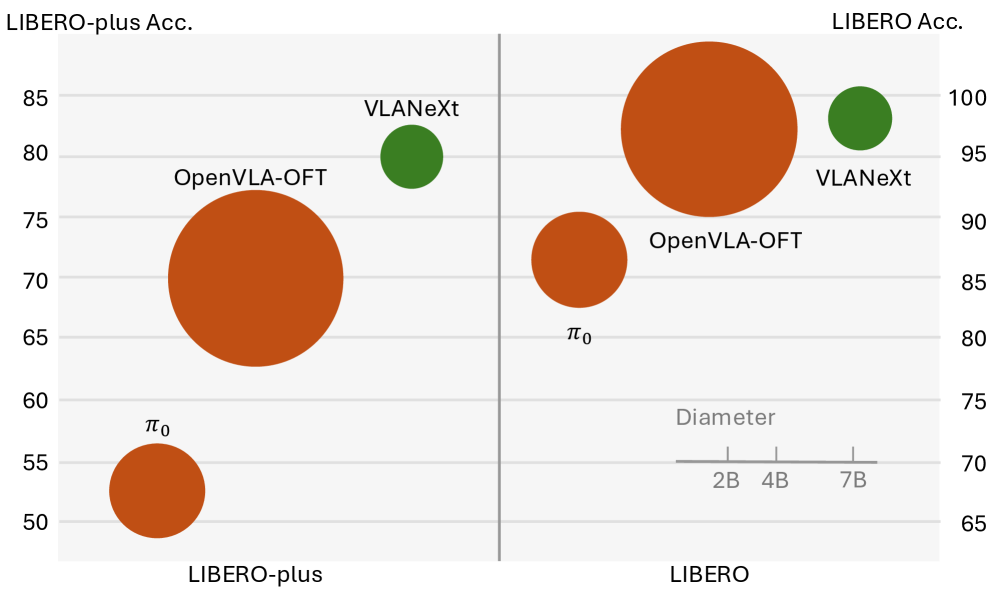
- Results show that following these recipes improves performance across different robot tasks and datasets
Plain English Explanation
Building a robot that can follow instructions is harder than it sounds. You need the robot to understand what it sees, understand what you're asking it to do, and then figure out what actions to take. Vision-language-action models tackle this by combining three things: vision (what the robot sees), language (what the human says), and action (what the robot does).
The trick is that there are many ways to wire these three pieces together, and some combinations work much better than others. VLANeXt doesn't invent new pieces—instead, it systematically tests which combinations actually work. Think of it like a recipe: you can make good pasta with many different ingredients, but certain choices matter more than others.
The foundational layer is about picking the right base models and how to connect them. The perception layer is about how the robot processes visual information. The action layer is about how it converts understanding into actual movements. Get all three right, and you have a capable robot. Skip steps in any one area, and performance drops.
Key Findings
- Architectural choices matter significantly: Decisions about how components connect have larger effects than researchers previously recognized
- Perception design is critical: The way a model processes visual input directly impacts downstream action quality across robot learning tasks
- Action modeling approaches vary in effectiveness: Different strategies for predicting robot movements produce meaningfully different results
- Scaling principles apply: Larger models and better pretraining consistently improve performance, with clear tradeoffs between capability and efficiency
- Dataset composition influences outcomes: The types of tasks used during training shape what kinds of behaviors the model learns
Technical Explanation
VLANeXt evaluates three interconnected design dimensions. The foundational components layer determines which pretrained vision models and language models serve as the backbone. This choice affects everything downstream because the quality of initial representations propagates through the entire system. The researchers test combinations with different vision encoders and language models to see which pairings produce the strongest overall behavior.
The perception essentials section examines how visual information flows through the model. This includes decisions about spatial resolution, how frames are processed over time, and whether the model maintains multiple views of the scene. These choices determine whether the robot can perceive relevant details—whether it can tell if an object is reachable, what state it's in, or where to direct its attention.
The action modeling perspectives investigate how the model translates understanding into movement commands. Some approaches predict the next action directly, while others predict multiple steps ahead or model the consequences of actions. The research shows these choices substantially affect whether robots can execute complex multi-step tasks or only handle simple single-action commands.
The experimental design tests these components on standard robot manipulation benchmarks, measuring success rates on tasks involving picking, placing, pushing, and other common robot behaviors. Results are evaluated across multiple datasets to confirm findings generalize rather than appearing due to dataset-specific quirks.
Implications for the field: This work provides practitioners with a principled framework for building robot models rather than relying on trial-and-error. By identifying which design decisions matter most, it accelerates development of generalist robot policies that can handle diverse tasks. The systematic evaluation also establishes baselines that future work can build from rather than starting from scratch each time.
Critical Analysis
The paper's strength lies in its comprehensiveness—testing many combinations to identify what actually works. However, the research is primarily empirical, establishing which designs work without always explaining why. This means practitioners get good recipes but limited insight into the underlying principles.
The evaluation focuses on standard benchmarks, which may not capture real-world deployment challenges. Robots in research labs face different conditions than robots in homes or factories. The extent to which these findings transfer to novel environments or task types remains uncertain.
There's also a question about the stability of the conclusions. As foundation models improve and new architectures emerge, some of these recipes may become outdated. The paper provides a snapshot of what works now but doesn't necessarily describe timeless principles.
The computational requirements for training these models aren't thoroughly discussed. While the paper shows that larger models perform better, the practical cost-benefit analysis of scaling for specific applications could use more attention. For teams with limited resources, understanding the efficiency tradeoffs matters significantly.
Additionally, the paper doesn't deeply explore failure modes or adversarial cases. Knowing where these models break down would help practitioners recognize when they've chosen an inappropriate design for their specific problem.
Conclusion
VLANeXt provides a practical guide for building vision-language-action models that work well in practice. Rather than proposing revolutionary new techniques, it systematically identifies which existing design patterns combine effectively. The research shows that careful architectural choices compound: getting the foundation right, then perception, then action modeling creates models substantially better than careless combinations of the same components.
For robot learning specifically, this means development teams can move faster by following established patterns rather than exploring the full space of possibilities. The framework also creates a clearer conversation about what matters in model design, making it easier to discuss tradeoffs and improvements.
The broader significance extends to other multimodal problems where understanding, perception, and output generation must work together. The insights about how to structure these connections apply beyond robotics. As these efficient vision-language-action models become more accessible, understanding the design principles behind them becomes increasingly valuable for practitioners building real systems.
This is a Plain English Papers summary of a research paper called VLANeXt: Recipes for Building Strong VLA Models. If you like these kinds of analysis, join AIModels.fyi or follow us on Twitter.