It was a Thursday, 11:22 PM, when our on-call rotation pinged me. Not because of an outage — nothing was down. The deployment pipeline itself had refused to run. Our brand-new zero-trust policy engine had flagged the service account token as "unverified cross-boundary access" and hard-blocked a routine backend release that literally seventeen engineers had already reviewed and approved. The fix took four hours. The deployment took eleven minutes once we sorted the policy exception.
I'd been the one who championed the zero-trust initiative. I'd read the NIST framework, attended two vendor briefings, and put together a 40-slide deck for leadership in Q2 of 2024. We had real reasons to do it — a near-miss credential leak from a third-party contractor, increasing compliance pressure from enterprise customers asking for SOC 2 Type II, and a general sense that our flat network model was quietly becoming a liability. All of that was true. Still is.
But I never modeled what it would cost in velocity. That was my mistake, and it's one I see teams making over and over right now as zero-trust moves from "security team initiative" to "engineering department mandate."
The Setup: Why We Actually Did This
Our stack at the time was about 60 microservices on ECS Fargate, a handful of Lambda functions handling async jobs, and a PostgreSQL cluster on RDS. Service-to-service auth was a mix of internal VPC rules, some IAM roles we'd half-migrated, and — I'll admit it — a few long-lived API keys that had been sitting in Parameter Store since 2021 with nobody entirely sure what they connected to anymore.
We brought in a security consultancy in April 2024 for a posture assessment. Their report was uncomfortable reading. Not catastrophic — no active exploits — but the blast radius of any single compromised service was much larger than it should have been. The recommendation was mTLS between services, workload identity via SPIFFE/SPIRE, OPA-based policy enforcement at the network edge, and elimination of all static credentials within 90 days.
🔒 What "Zero-Trust" Actually Meant For Us
mTLS for all service-to-service calls · SPIRE for workload identity · OPA policies enforced via Envoy sidecar · No static credentials in Secrets Manager · Certificate rotation every 24 hours · All deploy pipelines re-authenticated per-run against our identity provider
We scoped it as a six-month project. We finished in nine. And then the fun began.
Where the Time Actually Went
I spent two weeks after the rollout trying to understand what was eating deploys. My first guess was the obvious one: developers were avoiding releasing because the pipeline was painful. That turned out to be true, but it was only about a third of the story.
The rest broke down into categories I hadn't anticipated. Certificate rotation events were blocking pipelines roughly twice a week, because our SPIRE server wasn't designed to handle concurrent renewal requests from 60 services during a deployment window. Each service's Envoy sidecar needed a fresh SVID, and when they all hit the signing endpoint simultaneously during a deploy, we'd get timeout cascades.
Policy exception requests were the other killer. Every new deployment touching a cross-service call required an OPA policy review if the service had been modified in certain ways. We'd set the threshold conservatively — any change to service mesh routing or data classification touched a review gate. In Q1 2025, we logged 73 policy exception tickets. Average resolution time: 2.8 days.
Every new deployment touching a cross-service boundary required a policy review. We logged 73 exception tickets in one quarter. Average resolution time: 2.8 days.
The Honest Accounting
Let me be clear about what the data actually shows, because I've watched people use situations like this to argue against security investment and that's not what I'm doing. The security outcomes were real and significant. We went from 3.2 credential-related incidents per month (mostly internal — policy violations, over-permissioned service accounts, that kind of thing) to 0.4. That's not nothing. One of our enterprise customers specifically cited our zero-trust posture during a renewal conversation where a competitor had just disclosed a breach. We kept the account.
But the velocity costs were also real, and we never planned for them. We lost roughly 1.4 potential deploys per day across the team, sustained over about eight months before things started stabilizing. Each developer was burning an estimated 6.3 additional hours per week on auth-related friction — certificate debugging, policy exception requests, pipeline reruns after SVID timeouts. At a fully-loaded hourly rate, that's somewhere around $340K in lost engineering time in year one. The tooling itself cost $84K annually.
Year-One Financial Reality
Zero-trust tooling (SPIRE, OPA licensing, Envoy overhead): $84K/yr
Estimated lost engineering productivity (6.3 hrs/dev/week × team size × hourly rate): ~$340K
Prevented incidents (estimated cost avoidance vs. one credential breach event): $180K–$2.1M
Enterprise contract retained, partly attributed to security posture: $420K ARR
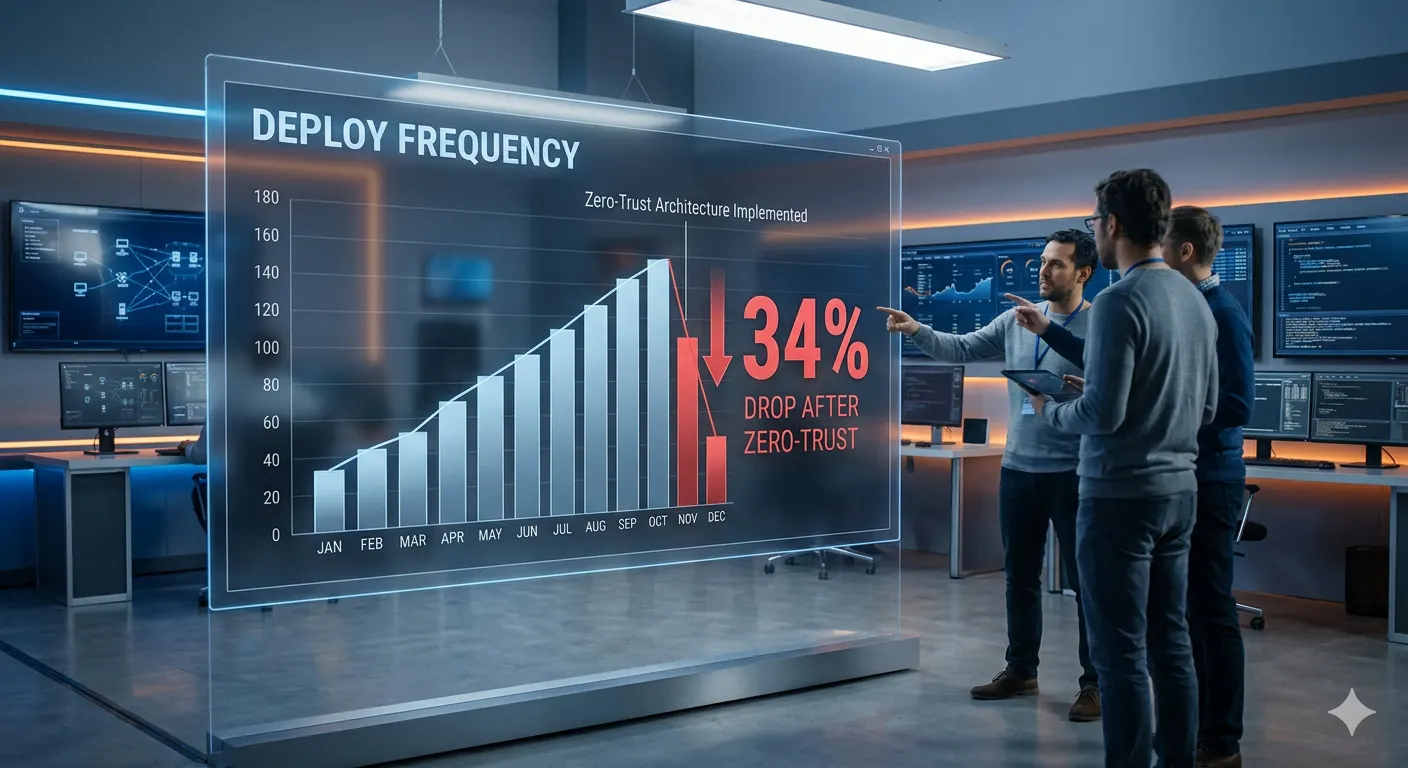
The math probably still works in favor of zero-trust. Probably. The problem is the costs hit immediately and the benefits are diffuse, future-tense, and hard to attribute cleanly. Finance doesn't put "avoided breach cost" on a spreadsheet. They do put "engineering velocity down 34%" on one.
What I'd Do Differently
I've had eighteen months to think about this and three conversations with other architects who've been through the same experience at different companies. The consensus is pretty consistent.
The biggest mistake wasn't adopting zero-trust. It was treating it as a platform project rather than a developer experience project. Our security team owned the rollout. Our DevEx team wasn't in the room. The result was tooling that was technically correct and practically miserable. SPIRE with 24-hour certificate rotation is fine if your deployment pipeline is designed around it. Ours wasn't, and retrofitting it took four months we hadn't budgeted.
We also set our OPA policy thresholds too conservatively at launch, then never revisited them. The 73-ticket quarter was entirely avoidable. We should have started with warn-mode for six months, analyzed what triggered reviews, and only promoted policies to enforce-mode once we understood the real traffic patterns. We did the opposite — enforce-mode from day one, loosen later. "Loosen later" never really happens once the security team has locked in the settings.
- Budget for DevEx time, not just implementation time. Plan to spend 40% of your zero-trust project timeline on tooling, documentation, and pipeline integration — not policy design.
- Start policies in warn mode. Run your OPA rules in log-only mode for at least two sprints before enforcing. You will be surprised by what normal traffic looks like.
- Decouple certificate rotation from deployment triggers. SPIRE certificate renewal should happen continuously on its own schedule, not as part of the deploy pipeline. If they're coupled, every cert event becomes a deploy event.
- Measure velocity before you start. We didn't have clean baseline metrics on deploy frequency, so our first three months of post-rollout data were partially confounded by measurement changes. Know your baseline.
- Tell leadership the velocity cost upfront. Not as a reason not to do it — as a reason to plan properly. The 34% drop would have been survivable if we'd budgeted around it. Instead it was a surprise, and surprised stakeholders are difficult stakeholders.
The Part That's Still True
None of this means zero-trust isn't worth it. The security posture improvement is real, the compliance benefits are real, and the enterprise sales motion around security is absolutely real in 2026. If you're building B2B infrastructure and your customers are serious companies, you are going to need this eventually. The question is whether you go in knowing what you're signing up for.
We went in assuming it was a security project. It turned out to be a delivery infrastructure project with security properties. That reframe would have changed everything about how we resourced it, who owned it, and how we measured success.
Our deploy frequency is at about 79% of where it was before. We've accepted that the remaining 21% is probably the permanent cost of operating at the security level our customers require. I wish I could tell you we found a way to get it all back. We didn't. But we did stop being surprised by that, and that's its own kind of progress.