
A Deeply Un-boring Dive into the New Rules for API Protection
A finance lead once said her worst day wasn’t the market crash, it was the moment customer data streamed out of one forgotten API, unnoticed until the damage was done. In the cloud and AI era, APIs aren’t just plumbing; they’re the lifeblood of business. When they break, they break loudly, expensively, and in public.
The fix? NIST SP 800–228, a Zero Trust–driven playbook that assumes attackers are already inside and teaches you to verify everything.
Why the Old Model Fails

The core problem, as SP 800–228 outlines, is that the old model is dead. The idea of a hardened perimeter with a soft, chewy center is a recipe for disaster in a world where applications are distributed across multiple clouds and on-prem environments. Your “internal” network is about as private as a conversation shouted in the middle of Times Square. This is why the document champions a Zero Trust architecture, where the fundamental assumption is that no user or service can be trusted by default . It’s not paranoia if they really are out to get you.
Attackers understand the terrain better than most defenders. They know where the forgotten endpoints hide. They steal tokens, slip in malicious payloads, or use an AI prompt to trick a model into revealing what it shouldn’t. One unchecked API call can go from a minor glitch to a company-wide breach in hours.
SP 800–228 doesn’t waste time pretending the walls will hold. It works on a Zero Trust assumption: verify everything, every time. Identity. Context. Authorization. All checked before anything moves.
Form, Storm, Norm, Perform: The Lifecycle of API Security
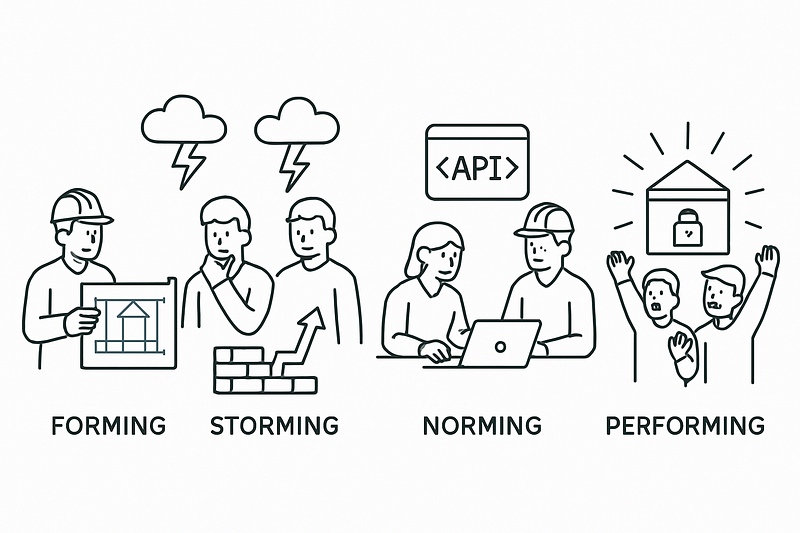
Dr. Bruce Tuckman’s classic model of team development: Forming, Storming, Norming, Performing is a perfect metaphor for how we need to approach API security . You can’t just throw a bunch of APIs together and expect them to work harmoniously. Security must be built-in throughout the entire iterative life cycle, from the moment of conception to the end of its operational life . SP 800–228 wisely splits its recommended controls into two main phases that mirror this journey: Pre-Runtime Protections and Runtime Protections.
Pre-Runtime Protections: Building the Blueprint
Before you even write a line of code, you need a plan. This is where you move from having a vague idea to creating a detailed blueprint. As the great philosopher Yogi Berra said, “If you don’t know where you’re going, you’ll end up somewhere else”.
Basic Protections (The “Just Add Water” Phase):
- Have an API Spec (REC-API-1): Every single API needs a specification document. Think of this as its birth certificate. In the beginning, this can be a simple wiki page, but the goal is to move to a formal, state-of-the-art Interface Definition Language (IDL) like OpenAPI or gRPC.
- Define Your Schemas (REC-API-3): Your spec must define the request and response schema for every endpoint. What fields are required? What are their data types? This isn’t just good documentation; it’s the foundation for automated validation down the line.
- Create a Central API Inventory (REC-API-4): Most organizations have APIs scattered everywhere, a result of organizational silos, mergers, and ad hoc projects . You can’t protect what you don’t know you have. A centralized inventory is non-negotiable. It should include the API spec, ownership information, and runtime details. This is your single source of truth — the north star guiding your security efforts.
Advanced Protections (The “Michelin Star Chef” Phase):
Once you have the basics down, it’s time to add the finesse that separates the amateurs from the pros.
- Semantic Validation (REC-API-5): Go beyond basic data types. If a field should only contain a positive number, define it as an unsigned integer. If a string has a maximum length, clearly specify it. Design your API so that invalid input is rejected by default.
- Tag Your Data (REC-API-6, REC-API-7): Mark every field with the right classification. Is it public or internal? Does it include PII, PHI, or PCI data? These tags allow runtime tools to automatically enforce rules, such as removing sensitive data before sending it to an untrusted source or monitoring how that data moves through your system. It’s like placing a digital “Confidential” label on your most valuable information.
Runtime Protections: Navigating the Open Road
Once your API is deployed, it’s live on the open road. This is where the rubber meets that road, and unfortunately, that road is filled with potholes, bad drivers, and the occasional roving band of malicious hackers . Runtime protections are the seatbelts, airbags, and anti-lock brakes for your data.
Basic Protections (The “Driver’s Ed” Essentials):
- Encrypt Everything (REC-API-9): All communication must be encrypted in transit. No exceptions. This ensures integrity (the data hasn’t been tampered with) and confidentiality (no eavesdropping) .
- Authenticate and Authorize (REC-API-11, REC-API-12): This is the heart of Zero Trust. Every single API call must authenticate both the calling service and the end user. Then, you must authorize that each is allowed to perform the requested action. Use standards like OIDC, OAuth2, or SPIFFE SVIDs whenever possible .
- Enforce Limits (REC-API-15): Unrestricted access is a DoS attack waiting to happen. You must enforce rate limits, timeouts, and payload size limits on all callers. And remember, rate limits are not quotas; they are about protecting the system from overuse in the short term, not managing a customer’s monthly billing plan .
- Log and Monitor (REC-API-18): If a tree falls in the forest and no one is around to hear it, did it make a sound? If your API is attacked and you have no logs, did it even happen? You need robust telemetry (logging, metrics, and distributed tracing) to see what’s happening and ensure your policies are actually working .
Advanced Protections (The “Formula 1” Upgrades):
- Field-Level Validation and Filtering (REC-API-19, REC-API-20): Now you can use those advanced pre-runtime annotations. The API gateway can automatically validate that a “name” field is less than 100 characters, or that an “amount” field is a positive number. It can also automatically filter out internal fields from responses going to external callers, preventing data leakage .
- This moves security from the application logic to the platform level, making it more consistent and easier to audit.
- Block Resource Enumeration (REC-API-24): Attackers love to figure out what resources exist in your system. A common trick is to query for sequential IDs (user/1, user/2, etc.) and see what comes back. If user/1 returns a “Permission Denied” (403) and user/99 returns a “Not Found” (404), the attacker knows user/1 exists.
- The fix? Always return “Permission Denied” for unauthorized requests, and use rate limiting and anomaly detection to block enumeration attempts.
The Gateway Question You Cannot Avoid
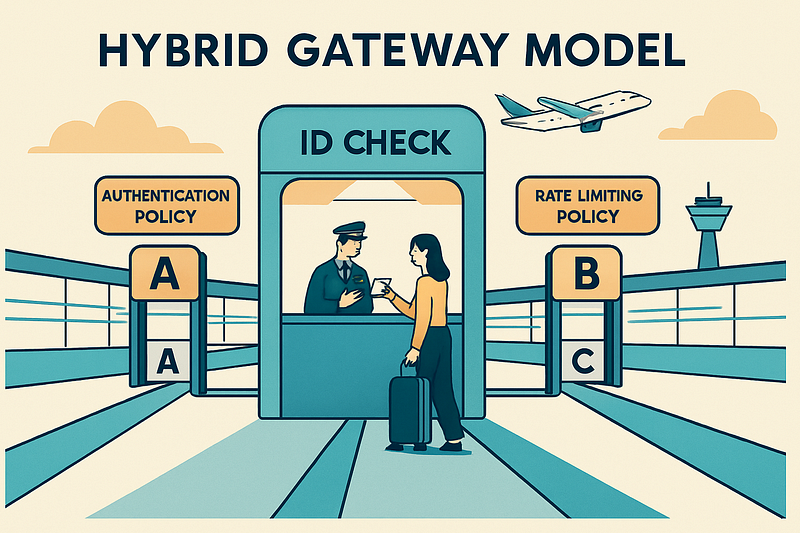
So, how do you actually implement all these controls? SP 800–228 outlines three main patterns for deploying your API gateway, which is the component that will enforce most of these policies. To make this less abstract, let’s compare them to something more familiar: airport security systems.
1# The Centralized Gateway
This is like having a single, massive, all-powerful security checkpoint at the main entrance to an entire international airport.
The Good: It’s a single point of enforcement, making it easy to monitor and audit. Application developers just need to clear the basics; they don’t have to set up their own checks.
The Bad: It creates a single point of failure. If the checkpoint malfunctions (or a bad configuration crashes the gateway), the whole airport grinds to a halt. You also get “noisy neighbors,” where a delay in one terminal’s line backs up traffic for everyone else.
2# The Hybrid Gateway
This is like having the big security line at the airport entrance checking IDs and carry-ons, but each individual terminal or gate has its own agents to enforce boarding rules and scan for prohibited items.
The Good: You move the most application-specific (and error-prone) policies out of the shared checkpoint, reducing the risk of widespread delays. App teams get more control and can move faster.
The Bad: Policy enforcement is now split between the central checkpoint and dozens of terminals, making it harder to ensure consistency. Application teams now have more operational responsibility.
3# The Distributed Gateway
This is like equipping every passenger with a smart boarding pass or biometric device that gets verified automatically at every gate, lounge, and shop they visit. In the real world, this is often implemented with a service mesh.
The Good: This is the Zero Trust dream. Policies are enforced right at each access point. There are no noisy neighbors and no shared-fate outages (beyond the airport infrastructure itself). It provides maximum security and agility.
The Bad: It puts the most operational burden on app teams and can create a massive number of policy checks across the system, which can strain your authorization service. Auditing is also more complex because enforcement is so decentralized.
While all three patterns can work, NIST strongly recommends the distributed gateway pattern as the one that best aligns with the principles of Zero Trust and offers the most robust security posture.
A Note for the Age of AI: Your APIs Now Fly Planes

Let’s talk about the behemoth in the control tower: Artificial Intelligence. The principles in SP 800–228 aren’t just relevant for today; they are absolutely critical for surviving the age of AI. Why? Because generative AI systems are, at their core, massive API-driven engines. They are also the perfect example of a “hijackable autopilot.”
The “confused deputy problem (Unintended Proxy or Intermediary, CWE-441)” is a classic security vulnerability where a program with legitimate authority (the deputy) is tricked by an attacker into misusing that authority. Think of a skilled pilot who can navigate complex skies but gets fed bad coordinates by a saboteur, sending the plane off course.
A large language model (LLM) is that pilot: highly capable, with clearance to vast stores of sensitive data, but vulnerable to being redirected by a sneaky “prompt injection” attack. This is like slipping false instructions into the flight plan, tricking the AI into leaking secrets or veering into dangerous territory.
This is where SP 800–228 becomes your AI security flight manual. The advanced controls are precisely what you need to keep your autopilot on the right path:
- Non-Signature Payload Scanning (REC-API-22): Traditional firewalls scan for known turbulence patterns. But prompt injection attacks are like invisible wind shear, unpredictable and context-driven. You need tools that analyze the semantics and intent of API requests and responses to spot manipulation, even without a matching threat signature.
- Traffic Monitoring with Semantic Labels (REC-API-21): By tagging your data (PII, PHI, etc.), you can enforce flight rules that prevent the AI from routing sensitive information to an unauthorized destination, no matter how convincing the detour request.
- Resource Consumption Limits (REC-API-15): AI APIs can burn through fuel at an alarming rate. Protections like capping query complexity and outbound calls per request stop attackers from forcing an endless loop that racks up a massive cloud bill on your watch.
Key Takeaways: Beyond the Blame Game, The Goal Is Boring Security
Let’s be honest. Nobody gets excited about reading a government PDF. But the real story of SP 800–228 isn’t about compliance; it’s about ending the 2 a.m. panic calls. It’s about replacing the “who-approved-this-API?” blame game with a “let’s-check-the-inventory” conversation.
This isn’t about adding more process. It’s about building a platform so trustworthy that your teams can stop acting like gatekeepers and start being partners. When security becomes observable, verifiable, and frankly, a little boring… that’s when you know you’ve won.
The question isn’t just about protecting data. It’s about protecting your team’s sanity. What will you do this week to make their jobs less heroic and a lot more predictable?
May Secure API Be with You!
[story continues]
tags