
Table of Links
-
Related Works
2.3 Evaluation benchmarks for code LLMs and 2.4 Evaluation metrics
-
Methodology
-
Evaluation
4 Evaluation
A total of 10944 tasks in Lua programming language were solved by the five code LLMs at 2-bit, 4-bit, and 8-bit quantization levels. The total inference time was approximately 87 hours.
4.1 Pass@1 rates
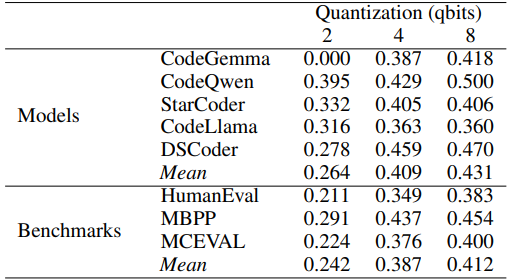
Fig. 1 depicts pass@1 rates by (a) models and quantization and by (b) benchmarks and quantization. The exact values and corresponding means are listed in Table 4. For example, CodeLlama 7B Instruct with 2-bit integer quantization produced correct solutions for 31.6% of tasks across all benchmarks. In the HumanEval benchmark, the correct solutions constitute 34.9% of all solutions produced by the five models with 4-bit integer quantization. Here, a correct solution is a pass@1 solution that passed all unit tests. With the exception of 8-bit CodeQwen, the models demonstrate pass@1 rates below 50%. It is in line with the expectation for a low-resource language like Lua.
Fig. 1a suggests a negative effect of quantization on models’ performance. The drop in performance is more evident in 2-bit models. A special case is CodeGemma, which failed to solve any task at the 2-bit quantization. The biggest performance gains are from the 2-bit model to the 4-bit models. However, compared to the 4-bit models, the 8-bit models perform only marginally better. The performance of DeepSeek Coder, StarCoder, and CodeLlama does not
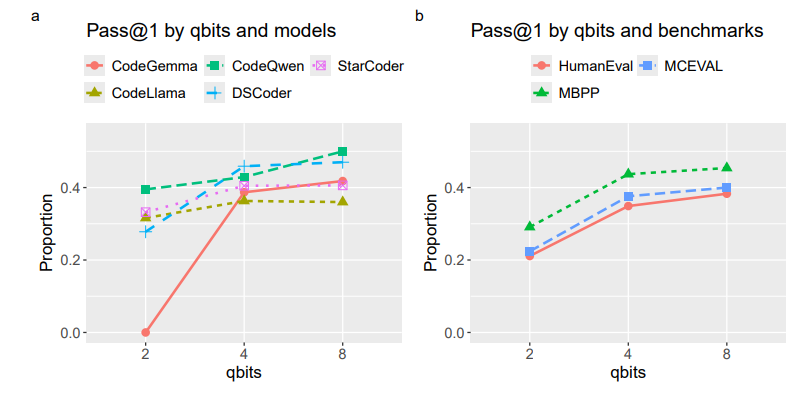
change much between 4-bit and 8-bit quantization. CodeQwen benefited the most from the 8-bit quantization by increasing its pass@1 rate by about 7%. According to Fig. 1b, in all three benchmarks, the 4-bit models perform better than the 2-bit models. This effect also holds after considering the skewed values for the 2-bit models due to CodeGemma. The performance gains level up with the 8-bit models.
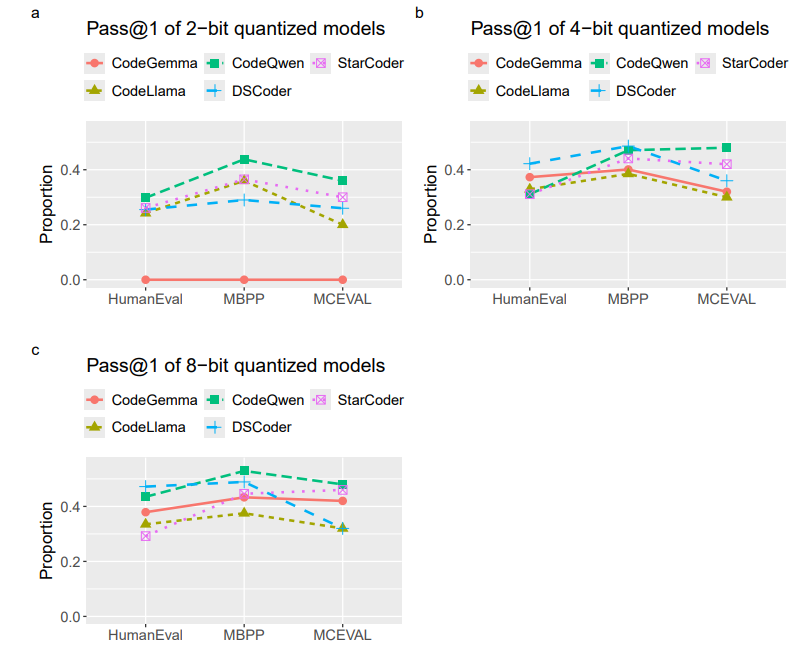
Fig. 1 also reveals that CodeQwen is consistently among the top-performing models, while CodeLlama is a poorerperforming one. True to its name, MBPP is the easiest benchmark among the three. HumanEval is slightly more difficult than MCEVAL. However, Fig. 2 suggests that MCEVAL may contain a greater variety of tasks highlighting the differences between the models. The pass@1 rates for the 2-bit and 4-bit models are closer to each other in HumanEval and MBPP. But for MCEVAL, the pass@1 rates remain more spread out independently of quantization.
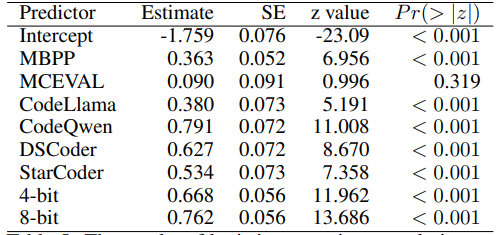
To statistically verify the descriptive analysis, a logistic regression was applied on pass@1. The predictors were the three benchmarks, five models, and three quantization levels. All were nominal predictors. The predictors were verified for multicollinearity with adjusted generalized VIF (GVIF). No GVIF value exceeded 2 suggesting no or low multicollinearity. Table 5 lists the result of the regression. The intercept represents the log odds of a correct solution by 2-bit CodeGemma in the HumanEval benchmark. According to the regression, the log-odds increase for 4-bit and 8-bit quantization but the increase from 4-bit to 8-bit (0.094) is not as high as from 2-bit to 4-bit (0.668). The log odds are also significantly higher for MBPP compared to HumanEval but do not change significantly for MCEVAL. Lastly, the log odds suggest that CodeQwen and DeepSeek Coder are the overall top-performing models. CodeLlama is shown to be better than CodeGemma but it is likely due to skewed data from the 2-bit models.
The logistic regression model should be interpreted with certain care. McFadden’s Pseudo R2 for the regression model is 0.035 meaning that the model fails to explain a major part of variance. Also, Fig. 1 and 2 suggest at least two interaction effects: between quantization levels and models and between benchmarks and models. We also tested a logistic model that includes all combinations of two-way interactions between the predictors. This more complex model had only a marginal increase in McFadden’s pseudo R2 (0.065) and a slightly lower AIC of 11275.06 compared to the AIC of 11602.03 of the first model. Furthermore, only one interaction effect was significant in the complex model and none of the main effects was significant. This result and the overall low pseudo R2 may be explained by a large variance in task difficulty that may be present in the benchmarks. This variance cannot be properly captured with the current predictors. Nevertheless, the model in Table 5 is sufficient for exploring the effects of quantization.
4.2 Errors
As discussed in Section 3, the failed solutions were categorized into failed unit tests, runtime errors, syntax errors, and timeouts. Fig. 3 depicts the proportions of these categories among all solutions generated by all models in the three benchmarks and at the three quantization levels.
The failed tests constitute the majority of errors in all three quantization levels followed by the syntax errors. It should be noted that the data for 2-bit quantization is skewed because 2-bit CodeGemma was not able to solve any task due

to persistent hallucinations. Listing 3 shows example hallucinations from three tasks that demonstrate a complete breakdown of any ability to produce a coherent response.
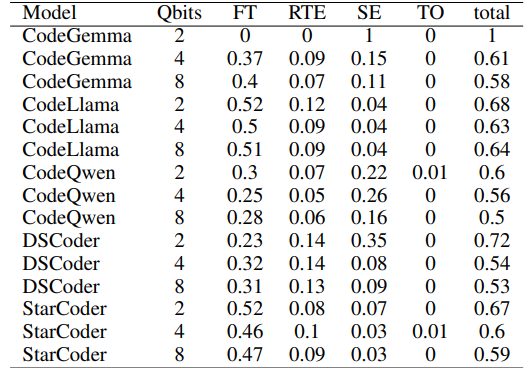
For a more accurate view, Table 6 breaks down Fig. 3 by the models. There is a general trend of increasing syntax errors with lower-precision quantization (lower qbits). CodeLlama seems to be less susceptible to this, but it also demonstrated poorer overall performance among the five models. DeepSeek Coder shows a decreased rate of failed tests for its 2-bit model. It is likely explained by the induction of syntax errors rather than better performance. CodeQwen is among the better-performing models. However, it seems to be more prone to syntax errors when it fails to generate a correct solution. Overall, quantization seems to affect the models’ ability to produce syntax error-free code resulting in lower performance for the lower-precision models.

Author:
(1) Enkhbold Nyamsuren, School of Computer Science and IT University College Cork Cork, Ireland, T12 XF62 (enyamsuren@ucc.ie).
This paper is available on arxiv under CC BY-SA 4.0 license.
[story continues]
tags