Table of Links
-
Hypothesis testing
2.5 Optional Stopping and Peeking
-
Safe Tests
-
Safe Testing Simulations
4.1 Introduction and 4.2 Python Implementation
-
Mixture sequential probability ratio test
6 Online Controlled Experiments
As A/B testing adoption has increased, new statistical methodologies have similarly proliferated. Variance reduction techniques such as CUPED [Den+13] and new statistical tests such as mSPRT [Joh+17] have become standard techniques at various technology companies. The A/B testing landscape is becoming increasingly crowded with innovative methods but there isn’t a benchmark with which to easily compare and contrast them. To address this issue, researchers from Imperial College London have compiled a series of datasets for online controlled experiments (OCE) [Liu+22]. These datasets contain real data from randomized controlled trials conducted online as well as some synthesized results. Collectively known as the OCE datasets, they can be used to benchmark and compare novel methods for conducting A/B tests.
The OCE datasets are a taxonomy of 13 anonmyized datasets found around the internet. The datasets contain daily snapshots of four metrics measured on 78 experiments and up to three variants. The data from the experiments can be binary, integer, or real-valued, allowing for a wide range of statistical methodologies to be tested.
A potential use case for the OCE datasets is benchmarking optional stopping methods, as newly developed methods may have unrealistic assumptions to ensure validity of their results. The availability of daily snapshots in the datasets means that a semi-sequential approach to testing can be applied. In the paper, mSPRT is compared to the classical t-test to validate the test on the OCE datasets. Table 4 shows the results.
In this section, the safe t-test will be conducted on the collection of OCE datasets, and the results compared with both the classical t-test and the mSPRT.
6.1 Safe t-test on OCE datasets
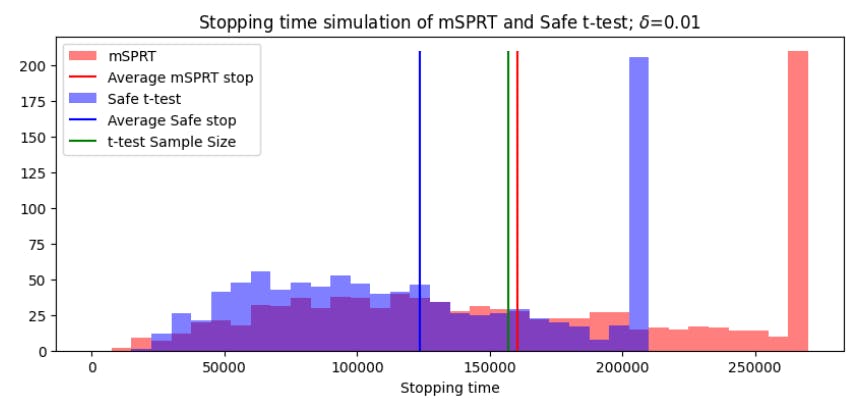
In order to benchmark the performance of the safe t-test, we can compare its results with the t-test. As we’ve seen in Figure 4 (right), the two tests do not always reach the same conclusion for each set of data. However, since the t-test is the most widely used statistical test for A/B testing, it is important to contrast the results in order to understand the situations in which the results differ. Table 5 shows the results of the t-test and the safe t-test on the collection of OCE datasets.
The safe t-test detects many more effects than the classical t-test. While, in theory, the false positive rate of the safe t-test should be below α, it seems unlikely that all of these rejections of H0 correspond to true effects. Following analysis of the behaviour of the E-values over the course of these experiments, we conclude that the high number of H0 rejections likely has to do with novelty effect. As mentioned previously, the novelty effect refers to an increased attention for the feature shortly after its release. The result is that the assumption of independent and identically distributed data is violated, with evidence against the null hypothesis to accumulate rapidly. For a fixed-sample test this is less of an issue because the distribution reverts over the course of an experiment. However, for safe tests this can cause a rejection of H0 before the true impact of the feature is determined. This fact is particularly relevant to practitioners seeking to implement anytime-valid statistical testing. Next, in Table 6, we compare the safe test and the mSPRT on the OCE datasets.
Unsurprisingly given the behaviour observed in Figure 8, the null hypotheses rejected by the mSPRT are similarly rejected by the safe t-test. However, the safe test rejects even more of the hypotheses than the mSPRT. This is likely because the safe test is more sensitive than the mSPRT and reacts more strongly to data which contradict the null hypothesis. In the next section, we continue analyzing the performance of safe tests at a large-scale tech company, Vinted.
Author:
(1) Daniel Beasley
This paper is