
Table of Links
-
Related Work
2.1 Open-world Video Instance Segmentation
2.2 Dense Video Object Captioning and 2.3 Contrastive Loss for Object Queries
2.4 Generalized Video Understanding and 2.5 Closed-World Video Instance Segmentation
Supplementary Material
5 Conclusion
In this work, we introduce OW-VISCap to jointly detect, segment, track, and caption previously seen or unseen objects in videos. We introduce open-world object queries to encourage discovery of previously unseen objects without the need of additional user-inputs. Instead of assigning a fixed label to detected objects, we generate rich object-centric captions for each object by using masked attention in an object-to-text transformer. Further, we introduce an inter-query contrastive loss to ensure that the object queries differ from one another. Our approach mostly matches or surpasses the state-of-the-art on the diverse tasks of open-world video instance segmentation on the BURST dataset, dense video object captioning on the VidSTG dataset, and closed-world video instance segmentation on the OVIS dataset. Through an ablation study, we demonstrate the effectiveness of each of our proposed components.
Acknowledgements: This work is supported in party by Agriculture and Food Research Initiative (AFRI) grant no. 2020-67021-32799/project accession no. 1024178 from the USDA National Institute of Food and Agriculture: NSF/USDA National AI Institute: AIFARMS. We also thank the Illinois Center for Digital Agriculture for seed funding for this project. Work is also supported in part by NSF under Grants 2008387, 2045586, 2106825, MRI 1725729.
References
-
Arnab, A., Dehghani, M., Heigold, G., Sun, C., Lučić, M., Schmid, C.: Vivit: A video vision transformer. In: ICCV (2021)
-
Athar, A., Luiten, J., Voigtlaender, P., Khurana, T., Dave, A., Leibe, B., Ramanan, D.: Burst: A benchmark for unifying object recognition, segmentation and tracking in video. In: WACV (2023)
-
Athar, A., Mahadevan, S., Osep, A., Leal-Taixé, L., Leibe, B.: Stem-seg: Spatiotemporal embeddings for instance segmentation in videos. In: ECCV (2020)
-
Bertasius, G., Torresani, L.: Classifying, segmenting, and tracking object instances in video with mask propagation. In: ICCV (2020)
-
Braso, G., Leal-Taixe, L.: Learning a neural solver for multiple object tracking. In: CVPR (June 2020)
-
Caelles, A., Meinhardt, T., Brasó, G., Leal-Taixé, L.: Devis: Making deformable transformers work for video instance segmentation. arXiv preprint arXiv:2207.11103 (2022)
-
Cheng, B., Choudhuri, A., Misra, I., Kirillov, A., Girdhar, R., Schwing, A.G.: Mask2former for video instance segmentation. arXiv preprint arXiv:2112.10764 (2021)
-
Cheng, B., Misra, I., Schwing, A.G., Kirillov, A., Girdhar, R.: Masked-attention mask transformer for universal image segmentation. In: CVPR (2022)
-
Cheng, B., Schwing, A.G., Kirillov, A.: Per-pixel classification is not all you need for semantic segmentation. In: NeurIPS (2021)
-
Cheng, H.K., Oh, S.W., Price, B., Schwing, A., Lee, J.Y.: Tracking anything with decoupled video segmentation. In: ICCV (2023)
-
Cheng, H.K., Tai, Y.W., Tang, C.K.: Rethinking space-time networks with improved memory coverage for efficient video object segmentation. In: NeurIPS (2021)
-
Choudhuri, A., Chowdhary, G., Schwing, A.G.: Assignment-space-based multiobject tracking and segmentation. In: ICCV (2021)
-
Choudhuri, A., Chowdhary, G., Schwing, A.G.: Context-aware relative object queries to unify video instance and panoptic segmentation. In: CVPR (2023)
-
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
-
Heo, M., Hwang, S., Oh, S.W., Lee, J.Y., Kim, S.J.: Vita: Video instance segmentation via object token association. arXiv preprint arXiv:2206.04403 (2022)
-
Hornakova, A., Henschel, R., Rosenhahn, B., Swoboda, P.: Lifted disjoint paths with application in multiple object tracking. In: ICML (2020)
-
Hu, Y.T., Huang, J.B., Schwing, A.G.: Videomatch: Matching based video object segmentation. In: ECCV (2018)
-
Huang, D.A., Yu, Z., Anandkumar, A.: Minvis: A minimal video instance segmentation framework without video-based training. In: NeurIPS (2022)
-
Huang, X., Xu, J., Tai, Y.W., Tang, C.K.: Fast video object segmentation with temporal aggregation network and dynamic template matching. In: CVPR (2020)
-
Huang, X., Xu, J., Tai, Y.W., Tang, C.K.: Fast video object segmentation with temporal aggregation network and dynamic template matching. In: CVPR (2020)
-
Jain, J., Li, J., Chiu, M.T., Hassani, A., Orlov, N., Shi, H.: Oneformer: One transformer to rule universal image segmentation. In: CVPR (2023)
-
Ke, L., Ding, H., Danelljan, M., Tai, Y.W., Tang, C.K., Yu, F.: Video mask transfiner for high-quality video instance segmentation. In: ECCV (2022)
-
Kim, D., Xie, J., Wang, H., Qiao, S., Yu, Q., Kim, H.S., Adam, H., Kweon, I.S., Chen, L.C.: Tubeformer-deeplab: Video mask transformer. In: ICCV (2022)
-
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. arXiv preprint arXiv:2304.02643 (2023)
-
Koner, R., Hannan, T., Shit, S., Sharifzadeh, S., Schubert, M., Seidl, T., Tresp, V.: Instanceformer: An online video instance segmentation framework. arXiv preprint arXiv:2208.10547 (2022)
-
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pretraining with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597 (2023)
-
Liu, Y., Zulfikar, I.E., Luiten, J., Dave, A., Ramanan, D., Leibe, B., Ošep, A., Leal-Taixé, L.: Opening up open world tracking. In: CVPR (2022)
-
Liu, Y., Zulfikar, I.E., Luiten, J., Dave, A., Ramanan, D., Leibe, B., Ošep, A., Leal-Taixé, L.: Opening up open world tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19045–19055 (2022)
-
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer: Hierarchical vision transformer using shifted windows. In: ICCV (2021)
-
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
-
Lüddecke, T., Ecker, A.: Image segmentation using text and image prompts. In: CVPR (2022)
-
Luiten, J., Fischer, T., Leibe, B.: Track to reconstruct and reconstruct to track. RAL (2020)
-
Meinhardt, T., Kirillov, A., Leal-Taixe, L., Feichtenhofer, C.: Trackformer: Multiobject tracking with transformers. In: CVPR (2022)
-
Munkres, J.: Algorithms for the assignment and transportation problems. J-SIAM (1957)
-
Oh, S.W., Lee, J.Y., Xu, N., Kim, S.J.: Video object segmentation using space-time memory networks. In: ICCV (2019)
-
Qi, J., Gao, Y., Hu, Y., Wang, X., Liu, X., Bai, X., Belongie, S., Yuille, A., Torr, P.H., Bai, S.: Occluded video instance segmentation. arXiv preprint arXiv:2102.01558 (2021)
-
Qi, L., Kuen, J., Wang, Y., Gu, J., Zhao, H., Torr, P., Lin, Z., Jia, J.: Open world entity segmentation. PAMI (2022)
-
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: ICML (2021)
-
Thawakar, O., Narayan, S., Cholakkal, H., Anwer, R.M., Khan, S., Laaksonen, J., Shah, M., Khan, F.S.: Video instance segmentation in an open world. arXiv preprint arXiv:2304.01200 (2023)
-
Voigtlaender, P., Chai, Y., Schroff, F., Adam, H., Leibe, B., Chen, L.C.: Feelvos: Fast end-to-end embedding learning for video object segmentation. In: CVPR (2019)
-
Voigtlaender, P., Changpinyo, S., Pont-Tuset, J., Soricut, R., Ferrari, V.: Connecting vision and language with video localized narratives. In: CVPR (2023)
-
Voigtlaender, P., Krause, M., O˘sep, A., Luiten, J., Sekar, B.B.G., Geiger, A., Leibe, B.: MOTS: Multi-object tracking and segmentation. In: CVPR (2019)
-
Wang, Q., Zhang, L., Bertinetto, L., Hu, W., Torr, P.H.: Fast online object tracking and segmentation: A unifying approach. In: CVPR (2019)
-
Wang, W., Feiszli, M., Wang, H., Tran, D.: Unidentified video objects: A benchmark for dense, open-world segmentation. In: ICCV (2021)
-
Wang, Y., Xu, Z., Wang, X., Shen, C., Cheng, B., Shen, H., Xia, H.: End-to-end video instance segmentation with transformers. In: CVPR (2021)
-
Wang, Y., Xu, Z., Wang, X., Shen, C., Cheng, B., Shen, H., Xia, H.: End-to-end video instance segmentation with transformers. In: CVPR (2021)
-
Wu, J., Wang, J., Yang, Z., Gan, Z., Liu, Z., Yuan, J., Wang, L.: Grit: A generative region-to-text transformer for object understanding. arXiv preprint arXiv:2212.00280 (2022)
-
Wu, J., Jiang, Y., Sun, P., Yuan, Z., Luo, P.: Language as queries for referring video object segmentation. In: CVPR (2022)
-
Wu, J., Jiang, Y., Zhang, W., Bai, X., Bai, S.: Seqformer: a frustratingly simple model for video instance segmentation. arXiv preprint arXiv:2112.08275 (2021)
-
Wu, J., Liu, Q., Jiang, Y., Bai, S., Yuille, A., Bai, X.: In defense of online models for video instance segmentation. In: ECCV (2022)
-
Xu, N., Yang, L., Fan, Y., Yang, J., Yue, D., Liang, Y., Price, B., Cohen, S., Huang, T.: Youtube-vos: Sequence-to-sequence video object segmentation. In: ECCV (2018)
-
Xu, Z., Zhang, W., Tan, X., Yang, W., Huang, H., Wen, S., Ding, E., Huang, L.: Segment as points for efficient online multi-object tracking and segmentation. In: ECCV (2020)
-
Yan, B., Jiang, Y., Sun, P., Wang, D., Yuan, Z., Luo, P., Lu, H.: Towards grand unification of object tracking. In: ECCV (2022)
-
Yang, L., Fan, Y., Xu, N.: Video instance segmentation. In: ICCV (2019)
-
Yang, S., Fang, Y., Wang, X., Li, Y., Fang, C., Shan, Y., Feng, B., Liu, W.: Crossover learning for fast online video instance segmentation. In: ICCV (2021)
-
Zhang, L., Lin, Z., Zhang, J., Lu, H., He, Y.: Fast video object segmentation via dynamic targeting network. In: ICCV (2019)
-
Zhang, Z., Zhao, Z., Zhao, Y., Wang, Q., Liu, H., Gao, L.: Where does it exist: Spatio-temporal video grounding for multi-form sentences. In: CVPR (2020)
-
Zhou, X., Arnab, A., Sun, C., Schmid, C.: Dense video object captioning from disjoint supervision. arXiv preprint arXiv:2306.11729 (2023)
-
Zou, X., Dou, Z.Y., Yang, J., Gan, Z., Li, L., Li, C., Dai, X., Behl, H., Wang, J., Yuan, L., et al.: Generalized decoding for pixel, image, and language. In: CVPR (2023)

This is the supplementary material of the OW-VISCap paper. We develop OWVISCap, an approach for open-world video instance segmentation and captioning. We test our approach on the task of open-world video instance segmentation (OW-VIS), dense video object captioning (Dense VOC) and closed-world video instance segmentation (VIS) in Sec. 4.
In this supplementary material, we provide additional analysis (Sec. A) to support the contributions we made in Sec. 3 of the main paper. We then discuss the implementation details (Sec. B) and limitations (Sec. C) of our approach.
Fig. S1 shows additional results on the BURST [2] dataset. We successfully segment and track the closed-world objects: persons, and the open-world objects: rackets, throughout the video. Fig. S2 shows results on the VidSTG [57] dataset. The detected objects are tracked throughout the video and our method generates meaningful captions for each object.
A Additional Analysis
In this section we provide additional analysis on the different components discussed in Sec. 3 of the main paper.
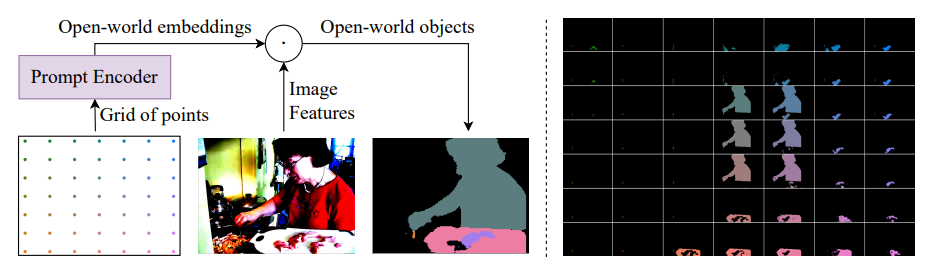
A.1 Open-World Embeddings as Object Proposals
We introduced open-world embeddings eow in Sec. 3.2 of the main paper. These embeddings are modulated in the object transformer (Fig. 2) to generate openworld object queries. We obtain the open-world embeddings by encoding a grid of

equally spaced points across the feature dimensions through a prompt encoder. This encourages object discovery throughout the video-frame. The open-world embeddings act as initial abstract object proposals.
In Fig. S3, we show that the open-world embeddings are strong object proposals, even before they are modulated by the object transformer by being combined with video frame features. The person, the spoon, the plate, and some food on the plate are discovered by the open-world embeddings. Their segmentation masks are obtained by the dot product between the open-world embeddings and the video frame features. Further, we see a strong spatial correlation between the grid of points and the segmentation masks generated by the corresponding open-world embeddings. This suggests that encoding a grid of points throughout the feature dimensions encourages object discovery throughout the video frames.
A.2 Masked Attention for Object-Centric Captioning
In Tab. 5, we quantitatively show that masked-attention (Sec. 3.3) helps in generating accurate object-centric captions for individual objects. Fig. S4 shows the high quality of the object-centric captions generated. The black caption (‘a family sitting on a couch with a child’) is obtained when no mask is provided in the object-to-text transformer. The entire image features are seen during the cross attention operation in each layer of the object-to-text transformer. The caption fails to capture the object-centric details.
The colored captions are generated with masked-attention for the individual objects. The colored captions on the left clearly highlight the effectiveness of masked attention to generate object-centric captions. For example, the three persons (highlighted in cyan, grayish blue, and green) have distinct captions, each one describing the individual identities of the corresponding person. The school bag (light blue) is also described correctly. We want to note that sometimes the method fails to generate meaningful object-centric captions for small objects (captions on the right). We discuss this more in Sec. C.

A.3 Contrastive Loss to Suppress Overlapping Predictions
In Tab. 3 and Tab. 4 of the main paper, we demonstrate the effectiveness of using the contrastive loss Lcont (discussed in Sec. 3.4) for object detection. This loss encourages that object queries differ from each other, among others by suppressing highly overlapping predictions. We highlight this in Fig. S5. The left image shows a frame from the OVIS [36] dataset. The top-right and bottomright images show a few predictions from our network trained without (top) and trained with (bottom) the contrastive loss. The repetitive predictions for the top-right image are highlighted with red and cyan boxes. The contrastive loss helps in removing these repetitions.

B Implementation Details
In this section, we provide the implementation details of OW-VISCap. We first describe the architecture of different components discussed in Sec. 3. We then discuss our choice of hyper-parameters for all experiments discussed in Sec. 4. We also discuss the resources and the licenses of the code-bases and datasets used in the paper.
B.1 Architecture
Prompt encoder. Our prompt encoder discussed in Sec. 3.2 is a lightweight network, following the architecture of the prompt encoder used in SAM [24]. We initialize our prompt encoder from SAM [24] and fine-tune it on the BURST [2] dataset.
Captioning head. Our captioning head discussed in Sec. 3.3 consists of an object-to-text transformer and a frozen large language model (LLM). The objectto-text transformer decoder has 11 transformer layers. Each layer has a self attention, masked cross attention (discussed in Sec. 3.3) operations, followed by a feed forward network. The object-to-text transformer and the text embeddings etext are initialized from BLIP-2 [26]. We use a frozen OPT-2.7B model as the LLM. We fine-tune the object-to-text transformer and the text embeddings on the VidSTG [57] dataset.
B.2 Hyper-Parameters
We now discuss the hyper-parameters used in this work. For experiments on the BURST [2] dataset, we encode a grid of 7 × 7 point across the width and height of the image features to obtain the open-world embeddings eow discussed in Sec. 3.2. Hence the total number of open-world object queries Nobj,ow is 49. We also experimented with a grid of 4×4 and 10×10, but didn’t see a significant change in performance. For experiments on the VidSTG [57] dataset, the number

of text embeddings etext is 32. In all experiments, the maximum number of closed world objects (Nobj,cw) in a given video for a ResNet-50 backbone is 100, and for a Swin-L backbone is 200. We use a feature dimension C (Sec. 3.1) of 256 in all models.
We trained the models with an initial learning rate of 0.0001 and ADAMW [30] optimizer with a weight decay of 0.05. We use a batch size of 8. The networks were first initialized with weights from Mask2Former [8] trained on the COCO image instance segmentation dataset. We then fine-tune the models on the respective BURST [2], VidSTG [57], and OVIS [36] datasets for 10, 000, 16, 000 and 8, 000 iterations respectively.
B.3 Resources
We used 8 NVIDIA A100 GPUs to run the experiments presented in this paper. Each experiment took roughly 10 GPU hours of training on the A100 GPUs for the BURST experiments, 16 GPU hours for the VidSTG experiments, and 8 GPU hours for the VIS dataset experiments.
B.4 Licenses
Our code is built on Mask2Former [8] which is majorly licensed under the MIT license, with some portions under the Apache-2.0 License. We also build on SAM [24], which is released under the Apache 2.0 License and BLIP-2 [26] which is released under the MIT license. The OVIS [36] dataset is released under the Attribution-NonCommercial-ShareAlike (CC BY-NC-SA) License. The VidSTG [57] and BURST [2] datasets are released under the MIT license.
C Limitations
In this section, we show some failure modes of our proposed approach and discuss limitations. Fig. S3 shows that our approach sometimes fails to detect some open-world objects that a human may find to be of interest. For example, the grinder on the left, the window at the top-right, etc., are not detected by the network. The colored captions on the right side of Fig. S4 show that our approach sometimes fails to generate meaningful object-centric captions for small objects. For the purple object (cushion on a sofa), the caption (‘the the the ...’) is not meaningful since it fails to form a complete sentence or capture the identity of the object it represents. For the red object (other cushions on a sofa), the caption (‘a family sits on the couch’) is not object-centric since it fails to provide a description specific to the object. Fig. S6 further highlights a failure mode. After a train crosses the scene for a prolonged period of time (∼ 30 frames), object identities may be lost.
These issues can be addressed by stronger strategies for open-world object discovery, stronger caption-generators, and integrating better object trackers, which we leave for future work.
Authors:
(1) Anwesa Choudhuri, University of Illinois at Urbana-Champaign (anwesac2@illinois.edu);
(2) Girish Chowdhary, University of Illinois at Urbana-Champaign (girishc@illinois.edu);
(3) Alexander G. Schwing, University of Illinois at Urbana-Champaign (aschwing@illinois.edu).
This paper is
[story continues]
tags