Table of Links
-
Related Works
2.3 Evaluation benchmarks for code LLMs and 2.4 Evaluation metrics
-
Methodology
-
Evaluation
5 Discussion
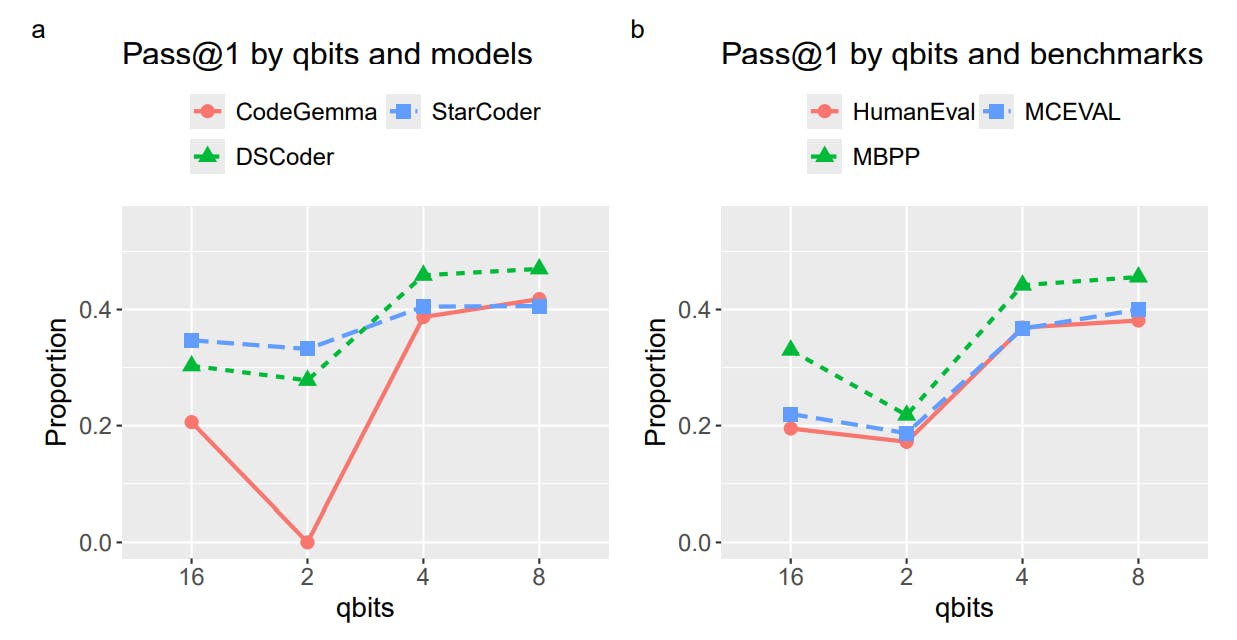
The results suggest that 4-bit integer quantization provides the best balance between model performance and model size. It is consistent with a conclusion made in the earlier study that evaluated quantized LLMs on general reasoning and knowledge tasks [16]. Furthermore, while still being smaller in size, quantized 4-bit models with 7 billion parameters performed better than non-quantized half-precision models with 3 billion or less parameters.
On the other hand, 2-bit integer quantization resulted in a significant performance degradation. In the extreme case of 2-bit CodeGemma, there was a complete breakdown in the model’s ability to generate coherent responses. This is likely an effect of hallucination [38; 39]. The low precision rounding likely impacted the model’s next token prediction ability (underlying probability distributions) resulting in a sequence of repetitive out-of-context tokens.
According to [14], StarCoderBase 1B, StarCoderBase 15B, and CodeLlama 34B demonstrated MultiPL-E pass@1 percentages of 12.1, 26.6, and 43.9 for Lua. In another study [33], the InCoder 6.7B, CodeGen 16.1B, and Codex 12B models demonstrated MultiPL-HumanEval pass@1 rates of approximately 0.05, 0.08, and 0.41 for Lua. In the same study, the corresponding pass@1 rates in the MultiPL-MBPP Lua benchmark were 0.13, 0.09, and 0.49. These values can be compared with the pass@1 rates in Table 4. The 4-bit and 8-bit quantized models with 7B parameters generally do not perform much worse than the non-quantized models in [14; 33] with higher parameter numbers. This may be
explained by advances made in LLM training and fine-tuning since the studies were published. For example, we used StarCoder2 7B while [14] evaluated StarCoderBase 15B. Compared to the original StarCoder released in 2023 [40], StarCoder2 was released in 2024 and trained on the Stack V2 dataset [21], which is seven times larger than the dataset the original StarCoder was trained on.
In Chai, Liu, Yang, et al. [22], CodeQwen 1.5 7B Chat, DeepSeek Coder 1.5 7B Instruct, CodeLlama 7B Instruct, and Codegemma 7B it (instruct tuned) demonstrated pass@1 percentages of 48%, 48%, 30%, and 48% on the MCEVAL Lua benchmark. According to Fig. 2, the 4-bit and 8-bit quantized CodeLlama Instruct models performed comparatively to the non-quantized CodeLlama Instruct model. Similarly, the 4-bit and 8-bit quantized CodeQwen 1.5 Chat only slightly underperforms the non-quantized models. There is a greater discrepancy between quantized and non-quantized CodeGemma and DeepSeek Coder models.
This demonstrated that performance-wise the effect of quantization differs between models. Many factors may influence the quantization such as model architecture, training datasets, training process, underlying foundational models, etc. For example, the underperforming quantized models are heavily instruction fine-tuned models. The DeepSeek Coder Instruct models were pre-trained from scratch on 2 trillion tokens and further instruction-tuned on 2 billion tokens of instruction data [19]. CodeGemma 7B [20] was pre-trained on 500 billion tokens but is based on the Gemma 7B model, which was pre-trained on 6 trillion tokens and further instruction-tuned on an undisclosed amount of data [41]. In contrast, CodeQwen 1.5 is based on Qwen 1.5 pre-trained on 3 trillion tokens and was further pre-trained on 90 billion tokens [18]. Therefore, It can be hypothesized that quantization may negatively affect most instruction fine-tuning performance. Overall, further studies are necessary to granularize the effects of quantization on different facets of code LLMs.
The study demonstrates that quantized 4-bit and 8-bit models with 7 billion parameters can be run reasonably well on laptops even without a dedicated GPU. From the perspective of computational demand, it is becoming increasingly feasible to use code LLMs for everyday programming tasks. This is especially true with the introduction of integrated environments, such as LM Studio and Ollama, that provide convenient and easy-to-use UIs for locally deploying LLMs. Generating 20 lines of correct code may require 30-50 seconds Fig. 7, which is a reasonable amount of time on a laptop oriented for business rather than coding productivity. The main problem lies with increasing inference time for generating incorrect solutions. Higher inference time does not necessarily result in better-quality code. This particularly applies to 8-bit models. Ironically, it can be another argument for using 4-bit models that can fail sooner rather than unproductively spend more time on generating incorrect solutions.
Performance-wise, both non-quantized code LLMs geared toward consumer devices and quantized code LLMs leave a lot to be desired. In most cases, these models demonstrate pass@1 rates lower than 50% in Lua. This is very low for precision tasks such as programming. The problem is further deepened by the difficulty of detecting errors. Ironically, code LLMs are quite good at generating incorrect code that is otherwise syntactically correct and does not produce
runtime errors (see Table 6). Therefore, any code generated by code LLMs requires extensive testing and supervision, which may negate any advantages of using code LLMs.
In this study, the Lua programming language was used for benchmarking the code LLMs. Lua is a low-resource language [14] characterized by a lower amount of available training data compared to high-resource languages like Python and Java. Moreover, Lua has programming patterns and constructs, such as metatables and class emulations, typically not found in other languages. Hence, it is not straightforward for code LLMs to leverage generic knowledge from other languages while generating Lua code. In other words, there is no bias imposed by high-resource programming languages. Therefore, performance in Lua is more representative of the real-life performance of code LLMs on a variety of tasks. It can be further argued that real-life professional programming that code LLMs ideally need to support is about writing efficient code for specific or even niche tasks. Similar to Lua, these kinds of tasks can be seen as ‘low-resource tasks’ even within high-resource programming languages. As such, Lua, as a niche language [33], may arguably be a better representative of these ‘low-resource’ tasks.
Likely, both proprietary and permissively licensed foundational models such as GPT-4o and Llama 3.1 405B can demonstrate significantly better performance, but accessibility is a major issue for these models. On the one hand, proprietary models like GPT-4o are pay-walled. On the other hand, permissive models like Llama 3.1 405B require a computational infrastructure that also may require considerable financial commitments. Therefore, further research is necessary to bring democratization of code LLMs. While quantization still remains a highly relevant topic, optimizing fine-tuning to be feasible on consumer devices is also essential. The ability to both fine-tune and quantize smaller LLMs for specific tasks is the necessary gap to address to enable greater consumer adoption. It should be noted that fine-tuning is not only a technical challenge. Unfortunately, datasets on which LLMs are pre-trained usually remain obscure and inaccessible to the public. Therefore, greater transparency and democratization of datasets is a necessary step toward the democratization of LLMs.
Author:
(1) Enkhbold Nyamsuren, School of Computer Science and IT University College Cork Cork, Ireland, T12 XF62 (enyamsuren@ucc.ie).
This paper is available on arxiv under CC BY-SA 4.0 license.