Last night, my project
This post is the story behind the project, but more importantly, it's about a simple idea: if we want autonomous agents to be useful in the real world, we need to take their memory and data freshness as seriously as we take their models.
The Problem: Agents Are Reasoning Over Yesterday's World
Most agent demos assume the world stands still while the model thinks. In production, nothing stands still:
- Issues are closed, tickets move stages, alerts fire, and resolve.
- Product catalogs change, prices update, and docs get refactored.
- Logs, events, and sensor data stream in continuously.
If your "knowledge" is a static dump you refresh once in a while, your agent ends up planning on a reality that no longer exists.
You see this as:
- Hallucinations that are actually just stale context.
- Agents repeating actions that have already succeeded or failed.
- Suggestions that would have been great… last week.
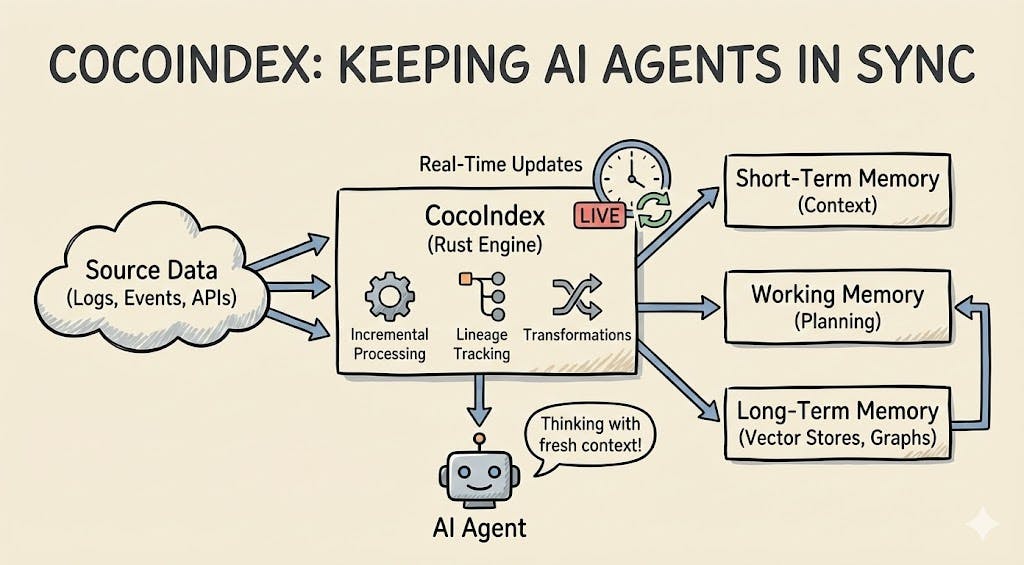
That was the itch that led to CocoIndex: a way to keep derived data—embeddings, graphs, tables—always in sync with the live sources feeding your agents.
How Memory Actually Works in Agents
If you've been following agent architectures, you've probably seen memory split into three layers: short-term, long-term, and working memory.
- Short-term memory: The immediate context — the last few messages, the current task, the current tool outputs. This lives in the model's context window and is cheap but extremely limited.
- Long-term memory: Everything you want the agent to "remember" across sessions: docs, conversations, events, user state, world knowledge. This typically lives in vector stores, databases, or knowledge graphs.
- Working memory: The scratchpad where the agent mixes both short-term and long-term information to reason, plan, and decide what to do next.
Most of the hype goes into working memory tricks and clever planning loops. But for real systems, long-term memory is where everything breaks: if that layer is incomplete, stale, or inconsistent, the nicest planner in the world can't save you.
Why incremental indexing is a superpower, not an implementation detail.
Rebuilding everything from scratch sounds simple… until you try it at scale. In a world of embeddings and LLM calls, "just re-run the pipeline" means:
- Repaying for embeddings that haven't changed.
- Re-processing entire document sets because a single section changed.
- Re-publishing whole indexes when only a few rows were touched.
Incremental indexing flips that:
- When a source object changes, CocoIndex identifies only the affected pieces.
- It recomputes just the transformations that depend on those pieces, and reuses cached outputs for everything else.
- It updates the targets (vector store, tables, graph) with minimal edits and cleans up stale entries via lineage tracking.
For agents, this has two huge implications:
- Freshness at lower cost: You can update continuously instead of batching once a day, without blowing up your compute or API bill.
- Trustworthy memory: When an item is updated or deleted at the source, the derived memory reflects that change quickly and correctly, instead of leaving ghost entries around.
The more you let agents act autonomously, the more they rely on this guarantee. Otherwise, you're handing them a map that never quite matches the terrain.
What CocoIndex Does for Incremental Processing
CocoIndex is a Rust-powered engine with a Python-first API that lets you describe how raw data turns into the "memory" your agents query. You point it at sources (files, object storage, APIs, databases), define transformations (chunking, embeddings, LLM extraction, graph building), and point it at your targets (vector stores, SQL, graph stores, custom sinks).
Three principles shaped the design:
- Dataflows, not glue scripts: You declare a flow: "take these documents, split them, embed them, write here," instead of wiring ad‑hoc scripts and cron jobs.
- Everything observable: You can inspect inputs and outputs of every transformation step, with lineage to track where each piece of derived data came from.
- Incremental by default: When something changes, CocoIndex figures out the minimal work needed and only recomputes what's necessary, reusing cached heavy steps like embeddings.
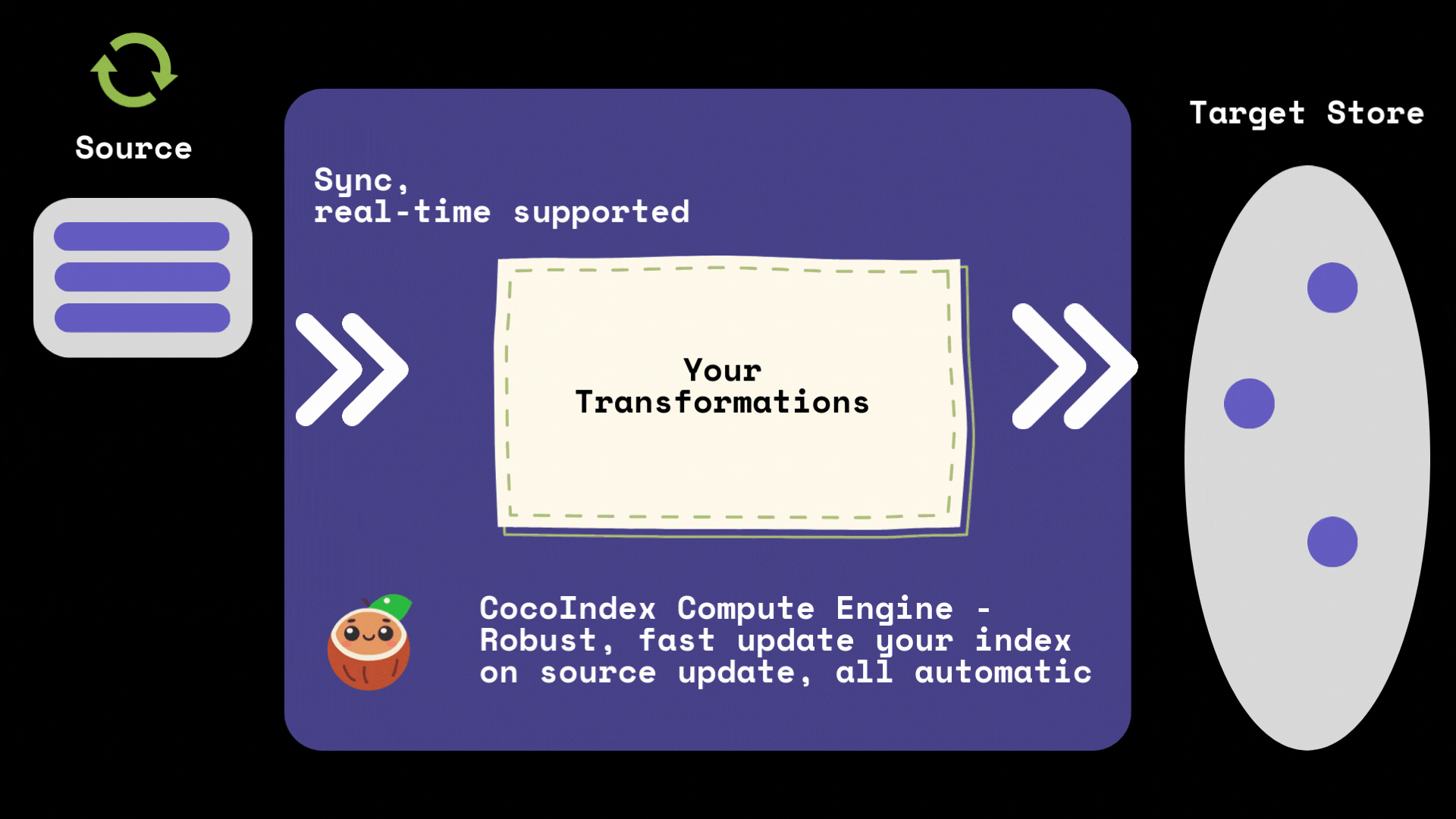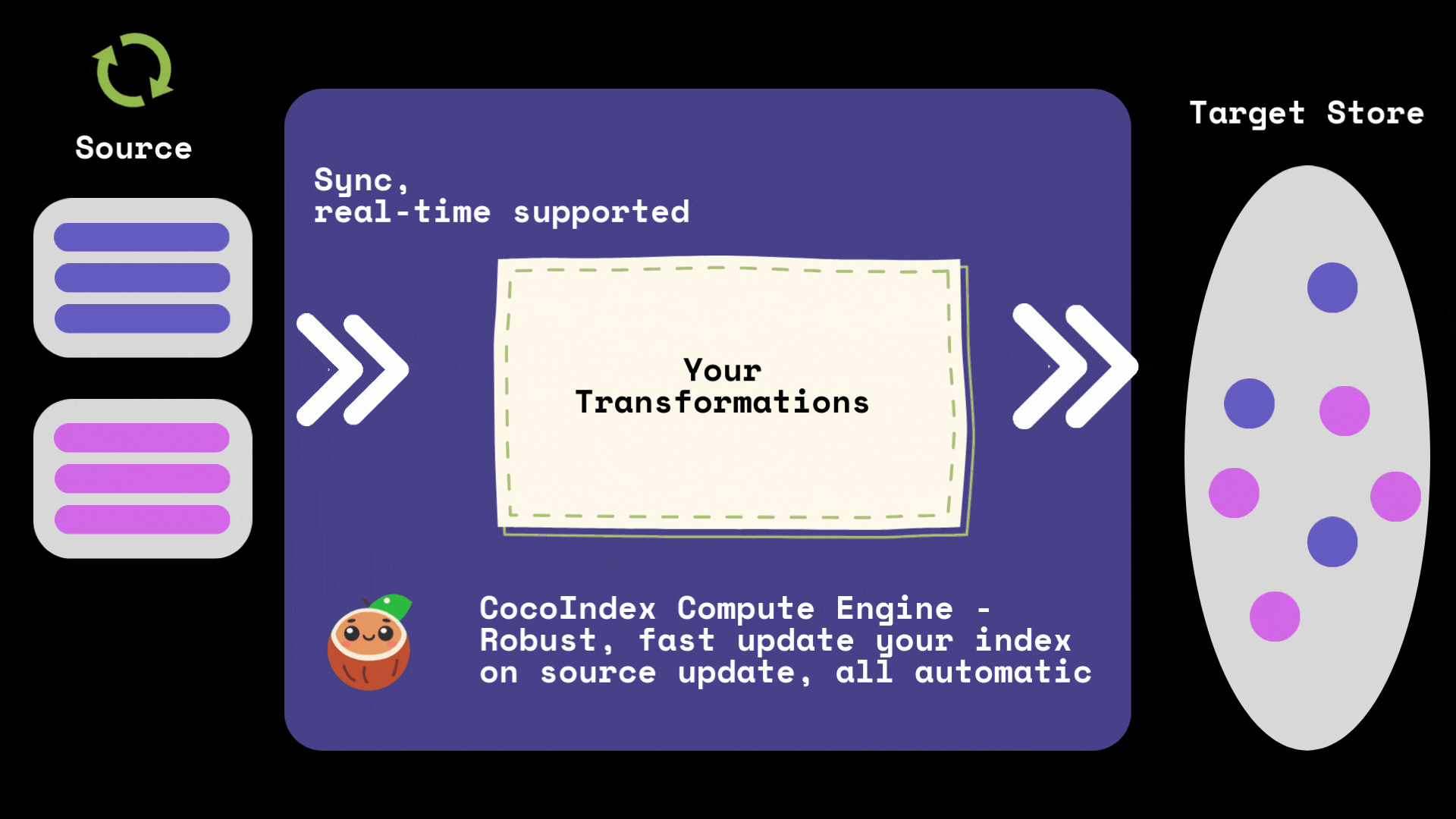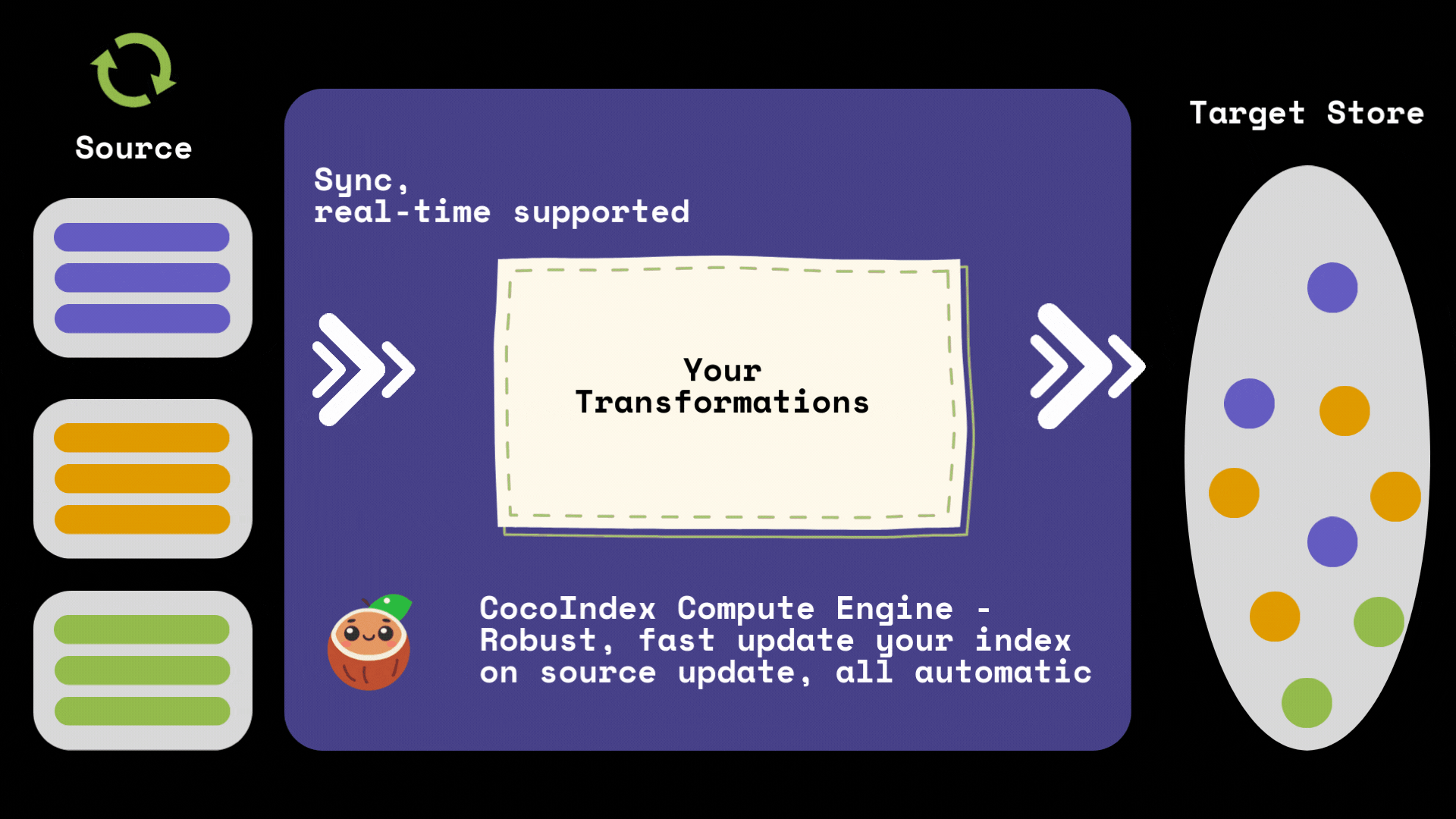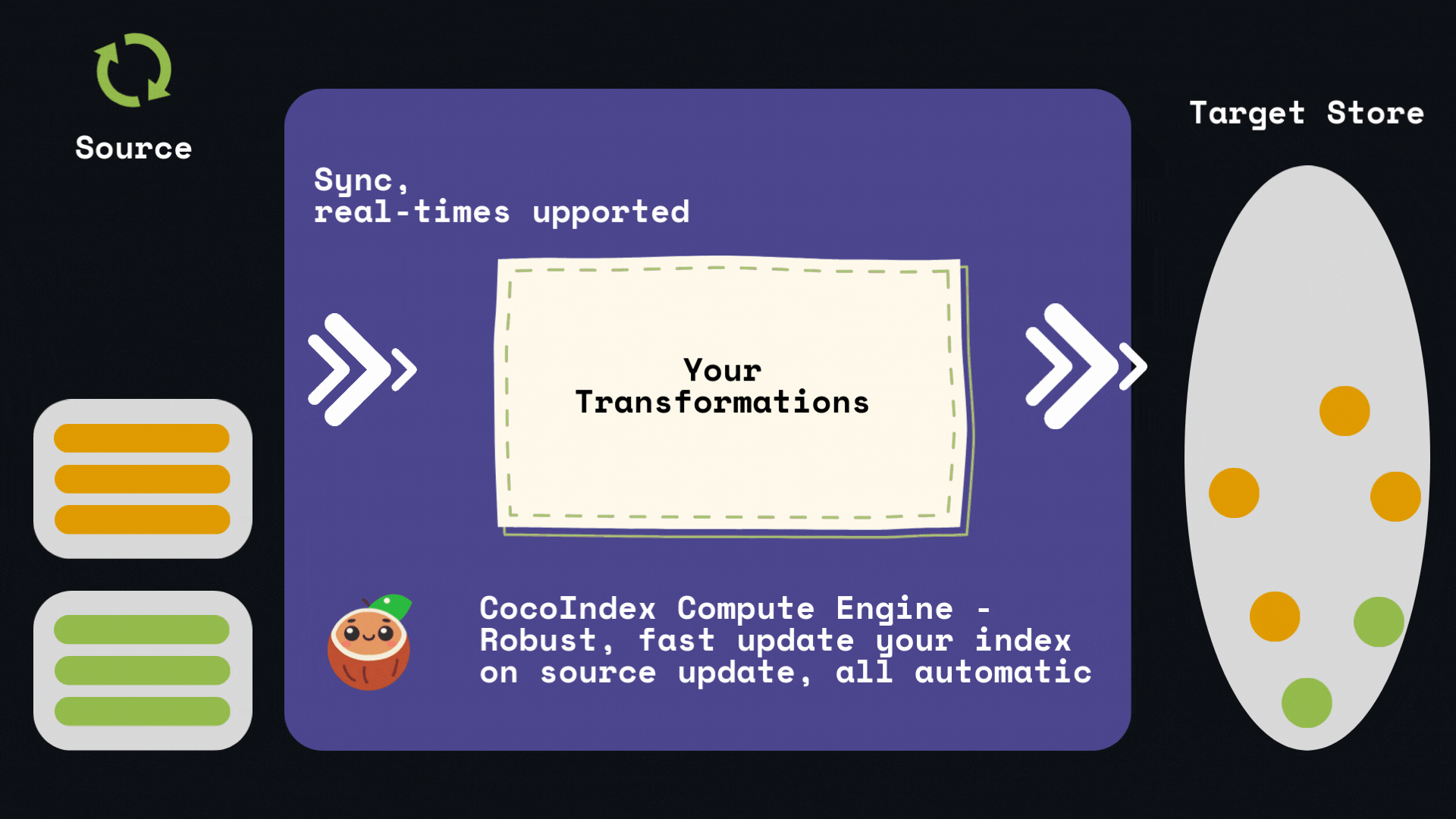
CocoIndex automatically tracks the lineage of your data and maintains a cache of computation results. When you update your source data, CocoIndex will:
- Identify which parts of the data have changed
- Only recompute transformations for the changed data
- Reuse cached results for unchanged data
- Update the index with minimal changes
Incremental Updates, by Examples
You don’t need to implement any below, because CocoIndex has it out of the box, but if you want to understand what is needed to implement incremental updates, here are a few examples.
Example 1: Update a Document
Consider this scenario:
- I have a document. Initially, it's split into 5 chunks, resulting in 5 rows with their embeddings in the index.
- After it's updated. 3 of them are exactly the same as the previous. Others are changed.
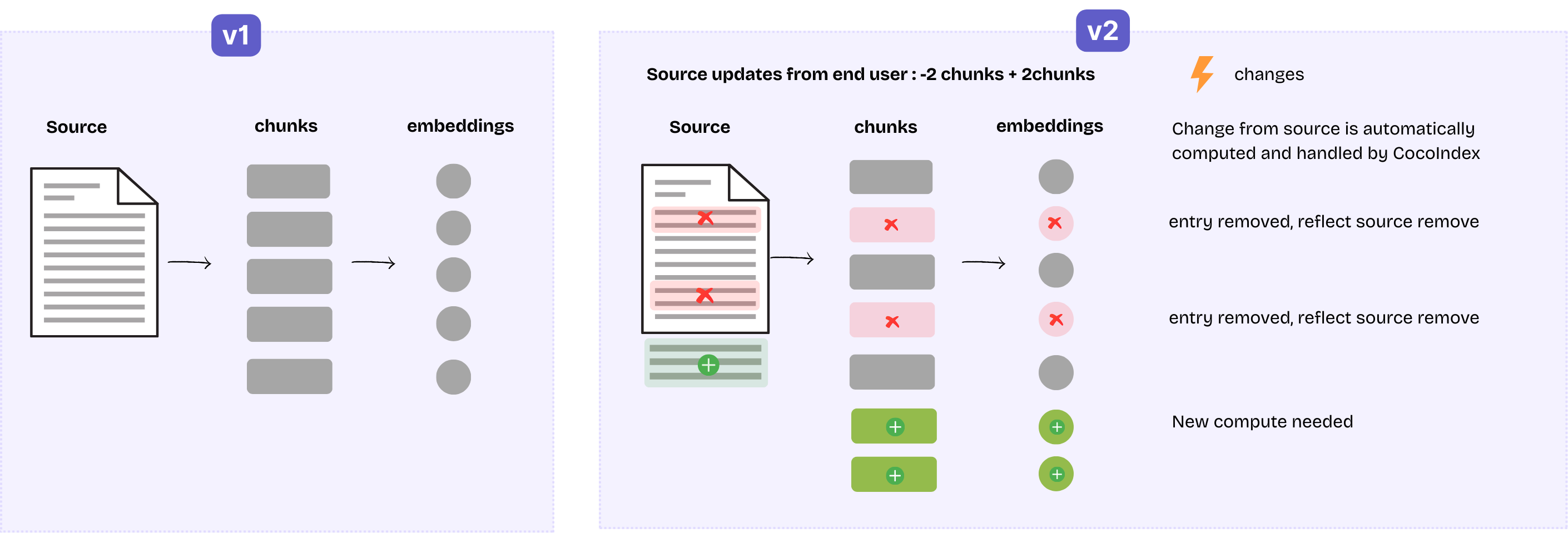
We need to keep 3 rows, remove 2 existing rows, and add 2 new rows. All of this happens behind the scenes.
Ideally, we only recompute embeddings for the 4 new rows and reuse the embeddings for the 3 unchanged chunks. This saves computation, especially when the embedding API charges per use. CocoIndex does this by caching expensive steps like embedding, and if the input to a transformation step hasn’t changed, the cached output is reused.
We also maintain lineage tracking in the internal storage. It records which rows in the index came from the previous version of the document, ensuring outdated versions are correctly removed.
Example 2: Delete a Document
Continuing with the same example. If we delete the document later, we need to delete all 7 rows derived from the document. Again, this needs to be based on the lineage tracking maintained by CocoIndex.
Example 3: Change of the Transformation Flow
The transformation flow may also be changed, for example, the chunking logic is upgraded, or a parameter passed to the chunker is adjusted. This may result in the following scenario:
- Before the change, the document was split into 5 chunks, resulting in 5 rows with their embeddings in the index.
- After the change, they become 6 chunks: 4 of the previous chunks remain unchanged, the remaining 1 is split into 2 smaller chunks.
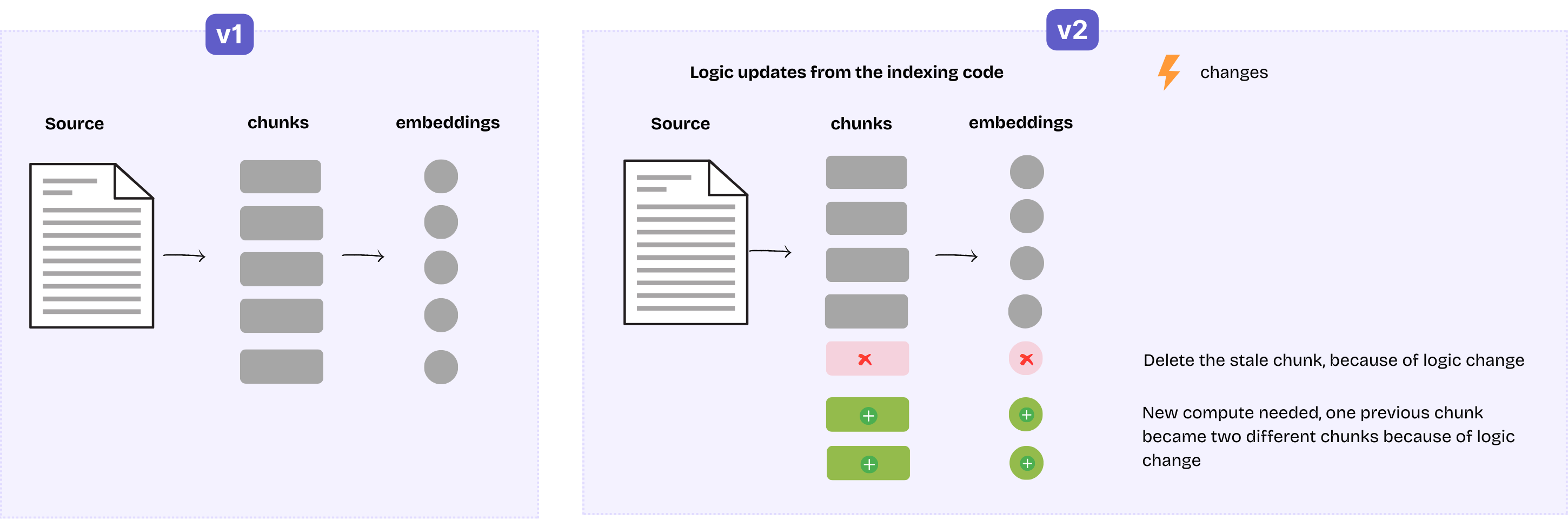
This is similar to the document-update case (example 1), and CocoIndex handles it the same way, with a few extra considerations:
We can still safely reuse embeddings for the 4 unchanged chunks through caching—assuming the embedding logic and spec have not changed. If either the logic or spec is modified, all embeddings will be recomputed. CocoIndex can detect changes to the logic or spec of an operation step by including that information in the cache key.
For removing stale rows in the target index, lineage tracking continues to work effectively. Some other systems delete stale outputs by replaying transformation logic on the previous input, which only works if the transformation is strictly deterministic and never updated. CocoIndex’s lineage-based approach avoids this limitation: it remains robust even when transformation logic is non-deterministic or changes over time.
Why this matters for autonomous "driving" agents.
Think of "autonomous driving agents" not just as physical cars, but as any agent "driving" a complex system: infrastructure, customer support, growth experiments, financial operations, internal tools. These agents:
- Observe a constantly changing environment.
- Retrieve relevant history and facts.
- Plan and execute actions over long horizons.
All three steps depend on a reliable memory substrate that evolves with the system. If your index lags by hours, your agent is effectively driving while looking in the rear-view mirror.
CocoIndex aims to be that substrate: a Rust engine that keeps your long-term memory aligned with reality through incremental updates, transparent lineage, and AI-native transformations. Rust Trending is a fun milestone — but the real goal is to make "fresh, trustworthy memory" a default property of every agent stack.
If This Resonates
If you've ever shipped an agent that broke because "the data wasn't updated yet," this is probably your life too. Check out the project on
[story continues]
tags