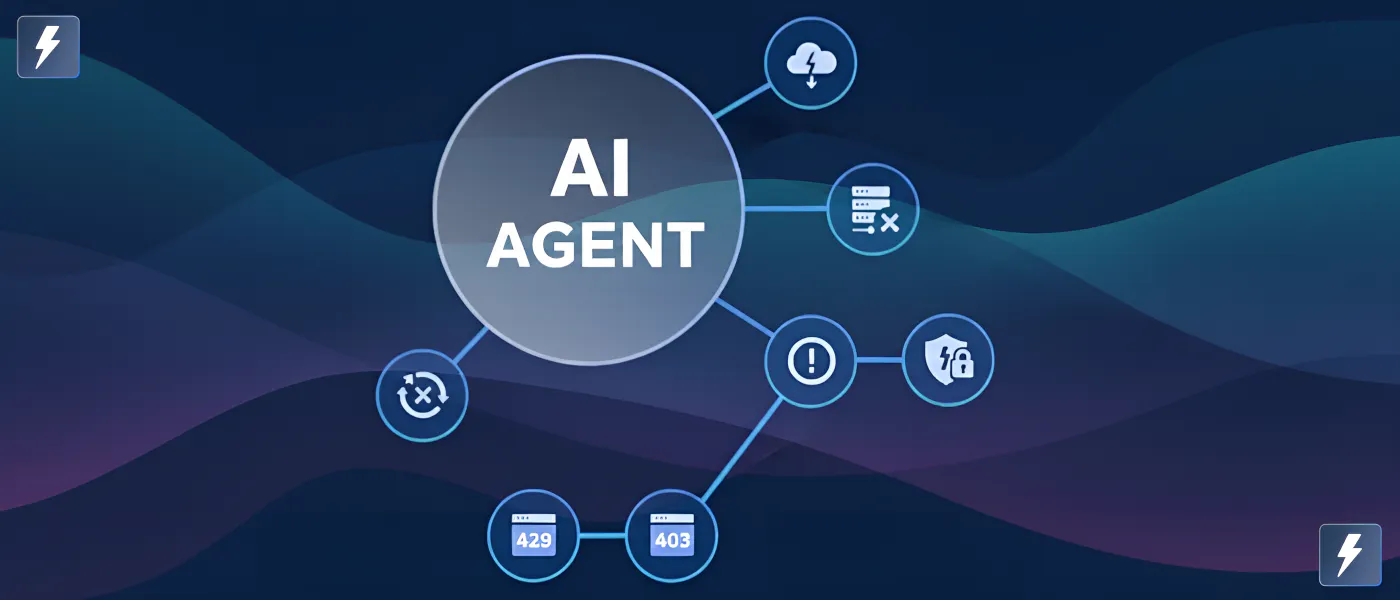
AI agents look impressive in demos until they hit the real world. The moment your agent retrieval pipeline scales up, failures start appearing, especially the dreaded “429 Too Many Requests” error.
Suddenly, your thought-to-be “production-ready” agent can’t fetch evidence fast enough to stay accurate…. The fix isn’t better prompts or agent frameworks. The solution is an infrastructure built for robust, verifiable, instant evidence acquisition!
In this article, you’ll learn why agents stall in production, what causes errors in production, and how to tackle them. Let’s dive in!
The Missing Piece AI Agents Need to Succeed
At a very high level, no matter the use case or scenario an AI agent is built for, they all share the same core engine: LLMs! 🤖
Yes, the same element that makes AI agents feel autonomous and almost magical is also the source of their boundaries and limitations. 😬
And what is the biggest limitation of LLMs? Old, static, obsolete knowledge…
Ask a pure LLM (one without tools for web access or grounding) about a recent event, and one of two things generally happens:
- It correctly tells you it doesn’t know (which is actually a good outcome 👍).
- Or it confidently invents an answer just for the sake of responding (a bad scenario leading to hallucinations 👎).
Instant Knowledge Acquisition: That’s the Missing Piece
But let’s be honest. Neither option (no real answers or just straight-up lies) works if you’re buildingmarket-aware agents that need to stay accurate as the world changes…
Plus, in their vanilla form, LLMs are limited to reasoning and text generation. They don’t have built-in access to the external world. By themselves, they cannot discover new information, retrieve fresh context, verify claims, or monitor changes over time.

They only operate on what they were trained on, which is nothing more than a snapshot of the past. That’s why, if you want LLMs to be actually useful in production, you must equip them with retrieval superpowers: RAG pipelines, web search and grounding, live data sources, external APIs, you name it.
Unfortunately, those capabilities aren’t part of the LLM itself. Instead, they’re implemented at the agent or application layer, utilizing agent frameworks, integrations, or custom infrastructure. 👨💻
As a result, AI agents succeed only when they can retrieve contextual data. And what is the largest, always up-to-date, rich, and trusted source of information on Earth? The web! 🌐
Think about it. When you need information, where do you go?

Successful AI agents need the tools to replicate that same behavior. They must be able to discover information and learn from it via web scraping (
In short, truly effective AI agents need access to instant knowledge acquisition capabilities!
Why AI Agents Crush It in Demos but Collapse in Production
Cool! You build your AI agent and give it some tools to fetch the information you think it’ll need to answer your queries or autonomously achieve its goals.
Next step: You spin up a demo environment and start testing the agent against a few prompts or tasks. The results? It works perfectly! 💯
At this point, you might think it’s time to deploy to production. But hold on… are you really testing it correctly?

Testing an AI agent is not like testing traditional code, as LLMs are probabilistic by nature, so different runs can produce different results. Even more importantly, you can never fully predict how the agent will behave in the wild or how it will adapt its plan based on the data it retrieves in real time.
What often happens is that you assume your demo agent works, but you’ve implicitly built constraints into the environment that don’t exist in production. For example, in your demo:
- Your agent might only have access to a static copy of your company’s knowledge base or a simplified RAG pipeline that doesn’t reflect constantly evolving data.
- The prompts are always the same and produce reasonably predictable results.
- The agent sources information from sandboxed websites or known demo pages.
All of that makes testing manageable. After all, if you tried to test the agent against real-time retrieval, you’d spend a huge amount of tokens, cloud resources, and time interacting with live data sources. So, simplifying makes sense. ✅
But keep in mind: once deployed, the real world is completely different… 🤯 (Spoiler: Be prepared to face “429 Too Many Requests” errors!)
It’s like learning to drive in an empty parking lot and then going straight to navigating one of the busiest cities in the world. The environments are nothing alike, and the final outcome will reflect that!
Unforeseen Challenges When AI Agents Hit Production
Now that you know what AI agents need to work in production, the real question is: why do they actually stall after performing perfectly in a demo environment? ⚠️
Time to dig into the challenges they’ll face when the sandbox ends and the issues begin!
429 Too Many Requests Error
Imagine your AI agent is tasked with fetching dozens of product pages from an e-commerce site to answer pricing questions in real time. Everything works perfectly in your demo with 1/2 queries. Scale up, and some requests will start failing with the
This happens because most web servers (or even official API servers) have mechanisms in place to prevent abuse from automated users/systems (like AI agents). Your agent is hitting those limits without realizing it, and the target source temporarily blocks further requests.
➡️ Why it’s hard to detect in demo: In a sandbox environment, the prompts are simple. Thus, the AI agent only sends a handful of queries, generally to known, trusted sites. But in production, your agent will start discovering and interacting with websites you hadn’t considered. It’ll fire off dozens of requests, and suddenly the server hits its limit, throwing “429 Too Many Requests” errors.
403 Forbidden Errors
Picture your AI agent discovering interesting news articles about a trending topic and trying to fetch market updates by following their URLs and scraping their content (e.g., by
Some sites, however, can detect automated behavior when your agent interacts with them. This triggers the infamous

That error occurs because many websites are protected by systems like WAFs (Web Application Firewalls) or general anti-bot solutions engineered to block automated access. 🛡️
➡️ Why it’s hard to detect in demo: In a controlled sandbox, your agent usually crawls known or whitelisted sites. In production, it discovers new domains on the fly and tries to access them. The problem is that many sites have anti-bot protections that never appear in a demo environment…
Concurrency Limitations
Assume your AI agent discovers some interesting URLs and decides to fetch all their pages simultaneously for instant knowledge acquisition. Everything looks fine in the limited, capped demo environment. But in production, the agent suddenly slows down dramatically or even stalls completely… 🐢
The culprit is your underlying infrastructure (i.e., your VM, cloud system, or proxy pool), which can’t handle the sheer volume of concurrent requests, creating a bottleneck. That’s a huge problem because most AI agents are designed to
➡️ Why it’s hard to detect in demo: Demo systems are rarely stressed with hundreds of simultaneous requests. Concurrency issues only surface under real enterprise-level load.
Rate Limiting Issues
Consider a scenario where your agent queries multiple APIs for live market data. In the demo, responses are instant. In production, some APIs start rejecting requests,
➡️ Why it’s hard to detect in demo: Small-scale demo testing doesn’t hit API or website rate limits, so these throttling mechanisms remain hidden until production.
General Web Scraping Blocks
Lastly, think of your AI agent trying to fetch evidence from blogs, documentation pages, stock market exchanges, competitor websites, or other web sources. When targeting demo pages, there are no real issues, and the agent can easily gather information from them.
Then production happens. Suddenly, the scraping requests made by your AI agent start getting blocked, CAPTCHAs appear (which
That occurs because live sites deploy anti-scraping defenses such as JavaScript challenges, bot detection systems, and IP reputation checks. Without
For more information, refer to
https://www.youtube.com/watch?v=vxk6YPRVg_o&embedable=true
➡️ Why it’s hard to detect in demo: Sandbox or test sites rarely have anti-bot defenses. In production, the live Web is hostile, and your agent encounters barriers you didn’t anticipate.
The Solution: An Architecture Built for Scalable, Accurate, and Instant Knowledge Acquisition
If you think about it, all the problems that make AI agents stall in production have something in common: they all originate from the underlying infrastructure of web discovery tools!

After all, an AI-ready knowledge discovery tool can:
Avoid “429 Too Many Requests” errors when the underlying infrastructure is built on a large proxy network that enables proper IP rotation.- Bypass “403 Forbidden” errors when the system includes advanced fingerprinting and session simulation that makes the web traffic generated by your AI agent look like real user traffic.
- Keep away from concurrency limitations when the infrastructure is built to scale and handle large volumes of parallel requests.
- Reduce rate limiting issues when requests are distributed across multiple IPs so your AI agent appears as a different user each time.
- Overcome general web scraping blocks when the platform includes CAPTCHA solving, fingerprinting, JavaScript rendering capabilities, and so on.
Sure, bringing AI agents to production certainly reveals a wide range of challenges. But with the right infrastructure partner, those challenges become manageable!
If you’re looking for the most trusted, scalable, and reliable AI infrastructures for web data,
Final Thoughts
In this post, you understood what makes AI agents successful in production and why an agent that works perfectly in a demo environment doesn’t typically work that well after deployment. You explored the obstacles your AI agent must face on the live web and saw how to deal with them!
As you’ve seen, the challenges can be significant. Still, all of them stem from the web discovery and data acquisition capabilities your agents need access to. Thus, success largely depends on choosing tools built on scalable, production-ready infrastructure.
[story continues]
tags