Table of Links
-
Method
-
Experiments
Supplementary Material
A. More implementation details
B. Compatibility with existing hardwares
C. Latency on practical devices
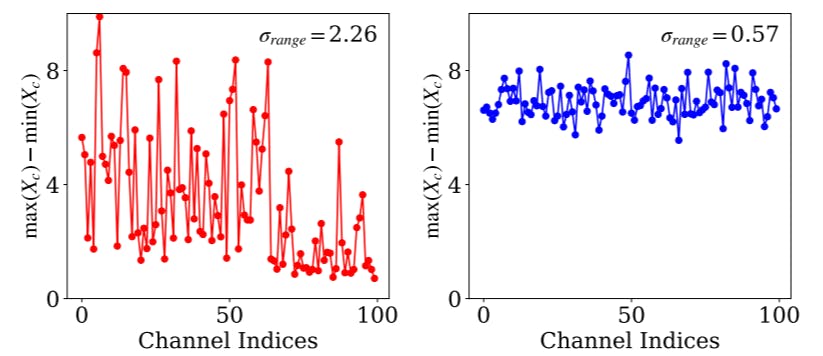
4.3. Discussion
Comparison with different quantizers. We compare in Table 4 the results of the variants of our method adopting different types of quantizers on input activations of FC layers and softmax attentions. From the first four rows, we can see that our approach outperforms layer-wise quantization by a large margin, both for linear operations and softmax attentions. This indicates that adopting a single quantization parameter for all channels and rows without considering
their individual distributions can severely limit the quantization performance. The last three rows compare the results of our approach with channel/row-wise quantization. We observe that the difference in performance between our approach and channel/row-wise quantization is less than 1.8% for three different models. With a small group size, our framework can achieve comparable performance to the upper bound, while maintaining efficiency.
Table 5 shows the results of quantizing ViT architectures using various group quantization techniques, including [4, 7, 32], and ours. While the works of [7, 32] divide consecutive channels uniformly into a number of groups, the method of [4] first sorts channels w.r.t. the dynamic ranges before partitioning them into groups. In contrast, we dynamically assign channels to groups according to the statistical properties of the channels. We find that our approach outperforms other methods by a large margin, indicating that fixing the channels assigned to each group can degrade the quantization performance significantly. We also observe that sorting the channels w.r.t. their dynamic ranges during calibration does not boost the quantization performance for DeiT-B [34] and Swin-T [25], suggesting that the dynamic range of each channel vary drastically across different input instances.
Analysis on group size. We show in Fig. 5 the results of IGQ-ViT according to the group size for linear operations (left) and softmax attentions (right). We can see that the quantization performance improves as the group size increases, for both linear operations and softmax attentions, demonstrating that using more groups better addresses the scale variation problem for channels and tokens. We also observe that the performance of our approach reaches near the upper bound with a small group size. This suggests that IGQ-ViT can effectively address the variations with a small amount of additional computations.
Convergence analysis. We compare in Fig. 6(top) distances between channels of activation and quantizers in Eq. (4) (rows of softmax attention and quantizers in Eq. (8)) over optimization steps. It shows that our algorithm converges quickly within a small number of optimization steps. We show in Fig. 6(bottom) the dynamic ranges of activations and attentions in a particular layer, along with their assigned groups after convergence. We can see that activations/attentions in each group share similar statistical properties, demonstrating that they can be effectively quantized with a single quantization parameter.
Group size allocation. We compare in Table 6 the results of our approach with/without the group size allocation technique. We can see that the group size allocation improves the quantization performance consistently, suggesting that assigning the same group size for all layers is suboptimal.
5. Conclusion
We have observed that activations and softmax attentions in ViTs have significant scale variations for individual channels and tokens, respectively, across different input instances. Based on this, we have introduced a instance-aware group quantization framework for ViTs, IGQ-ViT, that alleviates the scale variation problem across channels and tokens. Specifically, our approach splits the activations and softmax attentions dynamically into multiple groups along the channels and tokens, such that each group shares similar statistical properties. It then applies separate quantizers for individual groups. Additionally, we have presented a simple yet effective method to assign a group size for each layer adaptively. We have shown that IGQ-ViT outperforms the state of the art, using a small number of groups, with various ViT-based architectures. We have also demonstrated the effectiveness of IGQ-ViT compared with its variants, including layer-wise quantizers, channel/row-wise quantizers, and state-of-the-art group quantizers, with a detailed analysis.
Acknowledgements. This work was supported in part by the NRF and IITP grants funded by the Korea government (MSIT) (No.2023R1A2C2004306, No.RS-2022-00143524, Development of Fundamental Technology and Integrated Solution for Next-Generation Automatic Artificial Intelligence System, and No.2021-0-02068, Artificial Intelligence Innovation Hub).
References
[1] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv, 2016. 3
[2] Ron Banner, Yury Nahshan, and Daniel Soudry. Post training 4-bit quantization of convolutional networks for rapiddeployment. In NeurIPS, 2019. 2, 3
[3] Yoshua Bengio, Nicholas Leonard, and Aaron Courville. Es- ´ timating or propagating gradients through stochastic neurons for conditional computation. arXiv, 2013. 2
[4] Yelysei Bondarenko, Markus Nagel, and Tijmen Blankevoort. Understanding and overcoming the challenges of efficient transformer quantization. EMNLP, 2021. 3, 4, 7, 12
[5] Zhaowei Cai and Nuno Vasconcelos. Cascade r-cnn: Delving into high quality object detection. In CVPR, 2018. 6, 7, 11
[6] Zhaowei Cai and Nuno Vasconcelos. Rethinking differentiable search for mixed-precision neural networks. In CVPR, 2020. 3
[7] Steve Dai, Rangha Venkatesan, Mark Ren, Brian Zimmer, William Dally, and Brucek Khailany. Vs-quant: Per-vector scaled quantization for accurate low-precision neural network inference. Proceedings of Machine Learning and Systems, 2021. 1, 2, 3, 4, 7, 11, 12
[8] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, 2009. 2, 3, 6, 8
[9] Yifu Ding, Haotong Qin, Qinghua Yan, Zhenhua Chai, Junjie Liu, Xiaolin Wei, and Xianglong Liu. Towards accurate posttraining quantization for vision transformer. In ACMMM, 2022. 2, 6, 7
[10] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021. 1, 2, 5, 6, 8
[11] Steven K Esser, Jeffrey L McKinstry, Deepika Bablani, Rathinakumar Appuswamy, and Dharmendra S Modha. Learned step size quantization. In ICLR, 2020. 1, 2
[12] Jun Fang, Ali Shafiee, Hamzah Abdel-Aziz, David Thorsley, Georgios Georgiadis, and Joseph H Hassoun. Post-training piecewise linear quantization for deep neural networks. In ECCV, 2020. 2
[13] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016. 2, 3, 4, 12
[14] Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross Gir- ´ shick. Mask r-cnn. In ICCV, 2017. 6, 7, 11
[15] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015. 4
[16] Sangil Jung, Changyong Son, Seohyung Lee, Jinwoo Son, Jae-Joon Han, Youngjun Kwak, Sung Ju Hwang, and Changkyu Choi. Learning to quantize deep networks by optimizing quantization intervals with task loss. In CVPR, 2019. 2
[17] Dohyung Kim, Junghyup Lee, and Bumsub Ham. Distanceaware quantization. In ICCV, 2021. 2
[18] Junghyup Lee, Dohyung Kim, and Bumsub Ham. Network quantization with element-wise gradient scaling. In CVPR, 2021. 2
[19] Yuhang Li, Ruihao Gong, Xu Tan, Yang Yang, Peng Hu, Qi Zhang, Fengwei Yu, Wei Wang, and Shi Gu. Brecq: Pushing the limit of post-training quantization by block reconstruction. In ICLR, 2021. 1, 2, 3
[20] Yuhang Li, Mingzhu Shen, Jian Ma, Yan Ren, Mingxin Zhao, Qi Zhang, Ruihao Gong, Fengwei Yu, and Junjie Yan. Mqbench: Towards reproducible and deployable model quantization benchmark. NeurIPS, 2021. 12
[21] Zhikai Li, Junrui Xiao, Lianwei Yang, and Qingyi Gu. Repqvit: Scale reparameterization for post-training quantization of vision transformers. ICCV, 2023. 2, 3, 6, 7, 11
[22] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014. 2, 6, 7, 12
[23] Yang Lin, Tianyu Zhang, Peiqin Sun, Zheng Li, and Shuchang Zhou. Fq-vit: Fully quantized vision transformer without retraining. In IJCAI, 2022. 2, 3
[24] Hanxiao Liu, Karen Simonyan, and Yiming Yang. Darts: Differentiable architecture search. In ICLR, 2018. 3
[25] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In ICCV, 2021. 1, 2, 6, 7, 8, 11
[26] Zhenhua Liu, Yunhe Wang, Kai Han, Wei Zhang, Siwei Ma, and Wen Gao. Post-training quantization for vision transformer. In NeurIPS, 2021. 2, 3, 12
[27] Markus Nagel, Rana Ali Amjad, Mart Van Baalen, Christos Louizos, and Tijmen Blankevoort. Up or down? adaptive rounding for post-training quantization. In ICML, 2020. 1, 2, 3
[28] Yury Nahshan, Brian Chmiel, Chaim Baskin, Evgenii Zheltonozhskii, Ron Banner, Alex M Bronstein, and Avi Mendelson. Loss aware post-training quantization. Machine Learning, 2021. 2
[29] Eunhyeok Park and Sungjoo Yoo. Profit: A novel training method for sub-4-bit mobilenet models. In ECCV, 2020. 2
[30] JS Roy and SA Mitchell. Pulp is an lp modeler written in python. 2020. 6
[31] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In CVPR, 2018. 2, 4
[32] Sheng Shen, Zhen Dong, Jiayu Ye, Linjian Ma, Zhewei Yao, Amir Gholami, Michael W Mahoney, and Kurt Keutzer. Qbert: Hessian based ultra low precision quantization of bert. In AAAI, 2020. 1, 2, 3, 4, 7, 12
[33] Robin Strudel, Ricardo Garcia, Ivan Laptev, and Cordelia Schmid. Segmenter: Transformer for semantic segmentation. In ICCV, 2021. 1
[34] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herve J ´ egou. Training ´ data-efficient image transformers & distillation through attention. In ICML, 2021. 1, 2, 3, 4, 6, 7, 8
[35] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, 2017. 1
[36] Ziwei Wang, Changyuan Wang, Xiuwei Xu, Jie Zhou, and Jiwen Lu. Quantformer: Learning extremely low-precision vision transformers. TPAMI, 2022. 3, 4
[37] Xiuying Wei, Ruihao Gong, Yuhang Li, Xianglong Liu, and Fengwei Yu. Qdrop: randomly dropping quantization for extremely low-bit post-training quantization. In ICLR, 2022. 1
[38] CF Jeff Wu. On the convergence properties of the em algorithm. The Annals of statistics, 1983. 4
[39] Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transformers. In NeurIPS, 2021. 1
[40] Zhihang Yuan, Chenhao Xue, Yiqi Chen, Qiang Wu, and Guangyu Sun. Ptq4vit: Post-training quantization framework for vision transformers. In ECCV, 2022. 2, 3, 6, 7
[41] Jinshan Yue, Xiaoyu Feng, Yifan He, Yuxuan Huang, Yipeng Wang, Zhe Yuan, Mingtao Zhan, Jiaxin Liu, Jian-Wei Su, Yen-Lin Chung, et al. 15.2 a 2.75-to-75.9 tops/w computingin-memory nn processor supporting set-associate block-wise zero skipping and ping-pong cim with simultaneous computation and weight updating. In ISSCC, 2021. 11, 12
[42] Zixiao Zhang, Xiaoqiang Lu, Guojin Cao, Yuting Yang, Licheng Jiao, and Fang Liu. Vit-yolo: Transformer-based yolo for object detection. In ICCV, 2021. 1
[43] Aojun Zhou, Anbang Yao, Yiwen Guo, Lin Xu, and Yurong Chen. Incremental network quantization: Towards lossless cnns with low-precision weights. In ICLR, 2017. 1, 2
[44] Bohan Zhuang, Chunhua Shen, Mingkui Tan, Lingqiao Liu, and Ian Reid. Towards effective low-bitwidth convolutional neural networks. In CVPR, 2018. 1, 2
Authors:
(1) Jaehyeon Moon, Yonsei University and Articron;
(2) Dohyung Kim, Yonsei University;
(3) Junyong Cheon, Yonsei University;
(4) Bumsub Ham, a Corresponding Author from Yonsei University.
This paper is