Table of Links
B. CriticBench: Sources of Queries
C. CriticBench: Data Generation Details
D. CriticBench: Data Selection Details
E. CriticBench: Statistics and Examples
4 PROPERTIES OF CRITIQUE ABILITY
In this section, we conduct our analysis of the critique ability of large language models on CRITICBENCH. We focus primarily on the following three aspects: (1) how critique ability scales with model size (Section 4.1); (2) models’ self-critique ability (Section 4.2); and (3) the correlation between critique ability and models’ certainty in response to a query (Section 4.3).
For each query-response pair in the dataset, we employ few-shot prompting to instruct models to first conduct a chain-of-thought analysis to identify any flaws in the response and explain the reason; and subsequently issue a judgment on the response’s correctness. In evaluation, we focus solely on the accuracy of this final judgment, disregarding the correctness of the intermediate analysis. As empirical evidence has shown a strong correlation between the accuracy of intermediate chain-of-thought and the final answer (Wei et al., 2022b; Lewkowycz et al., 2022; Fu et al., 2023a), we can use the final judgment accuracy as a proxy for the model’s critique analysis capability. Details about the evaluation settings can be found in Appendix F.
4.1 SCALING LAW
Jang (2023) posits that critique ability may be an emergent ability (Wei et al., 2022a) that only emerges at certain scales of model size. We emphasize that it is better to seek an answer to this
hypothesis before directing our efforts toward the applications of critiques. For a critic model to successfully improve the performance of specific tasks, it must possess at least moderate effectiveness. It is possible that the critique ability of smaller models is as futile as a random guess, rendering them incapable for downstream applications. A study of the scaling law of critique ability could provide us insights into the appropriate model size selection and whether fine-tuning should be considered for smaller models.
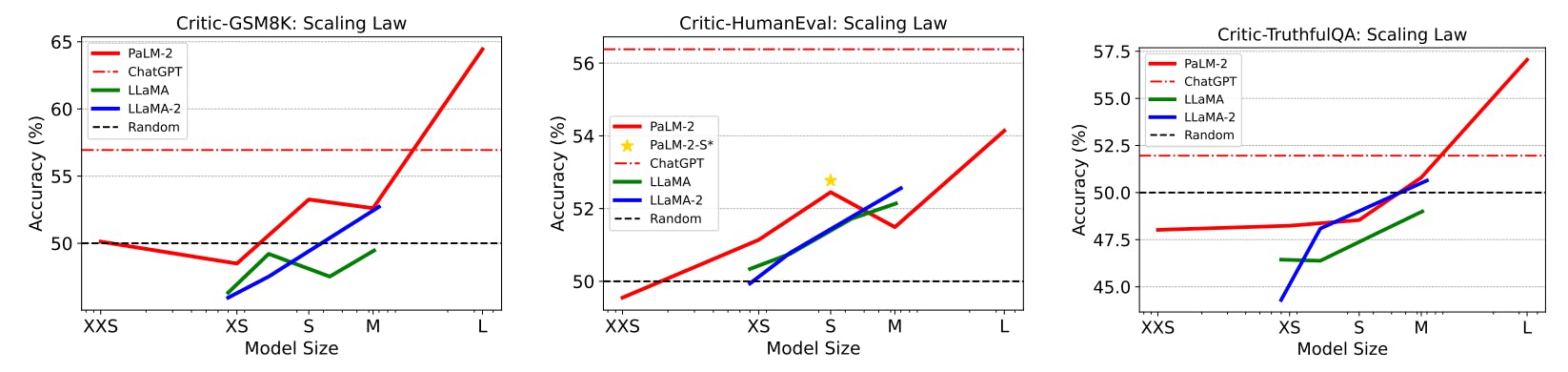
We evaluate multiple widely-used LLM families available in various sizes on CRITICBENCH, including PaLM-2 (Google et al., 2023), LLaMA (Touvron et al., 2023a), LLaMA-2 (Touvron et al., 2023b), and ChatGPT (OpenAI, 2023). Figure 3 illustrates the scaling behavior of their critique abilities. The results for ChatGPT are not directly comparable to those of other models because its size is not disclosed and it undergoes instruction-tuning, whereas the others are all pretrained models. We include it here solely for reference purpose. On Critic-GSM8K and Critic-TruthfulQA, all models of medium size or smaller exhibit poor performance, akin to random guessing. Only PaLM-2-L demonstrates non-trivial better results. On Critic-HumanEval, all models perform poorly; even the strongest pretrained model, PaLM-2-L, only achieves an accuracy score of merely 54.14%, which is just marginally better than a random guess. This is somewhat anticipated, as evaluating the correctness of a code snippet without execution is often challenging even for expert software engineers. It is likely to gain a notable improvement when augmented by a code interpreter tool. Thus, the benchmark also serves as an ideal testbed to assess LLMs’ tool-use capability.
The observed scaling law supports the emergent ability hypothesis by Jang (2023). It suggests that the ability of critique is yet another key indicator of a strong large language model.
Authors:
(1) Liangchen Luo, Google Research ([email protected]);
(2) Zi Lin, UC San Diego;
(3) Yinxiao Liu, Google Research;
(4) Yun Zhu, Google Research;
(5) Jingbo Shang, UC San Diego;
(6) Lei Meng, Google Research ([email protected]).
This paper is