Devs working with LLMs run into document parsing constantly. And every few months, there’s a new wave of hype (or frustration) around the PDF problem. During those moments, it’s not unusual to see software folks venting about how one file format became such a massive headache. But the struggle isn’t new.
Long before LLMs entered the picture, entire SaaS businesses were built around managing the messiness of PDFs. And for good reason, it’s a format that was never designed for the kind of structured, machine-readable access we now expect.
When software becomes as widespread as Adobe Acrobat and the PDF format, it starts to feel like a permanent part of the landscape. It’s easy to forget that behind that ubiquity were real design decisions, constraints, and tradeoffs made by real engineers solving real problems. Problems that, over time, evolved and became the roots of today’s pain.
Yes, PDFs are frustrating. But they weren’t born broken. In fact, they were a surprisingly elegant solution for their time.
So, let’s zoom out. This story takes a step back to explore the origins of the PDF format: how it came to be, what problems it set out to solve, and how the decisions made in the early 90s still ripple through today’s stack. The goal: to understand not just the “why is this so hard?”, but also the “how did we get here?”
Back to the ‘80s, from paper to pixels.
The shift had begun. Personal computers were exploding in popularity, and paper documents were no longer the default. Software like VisiCalc, WordStar, WordPerfect, and early Microsoft Word marked the dawn of a new way to write, edit, and share.
By the late ’80s, PC suites had all but killed off the typewriter. Executives could tweak reports minutes before a meeting. Analysts were running “what-if” scenarios in spreadsheets. Teachers were printing tests on the fly. Engineers replaced drafting tables with digital blueprints.
Increasingly, documents became the new workplace. Not just the end product, but where the work actually happened.
The ‘90s and the birth of the PDF.
In the early 1990s, the rise of PC-based word processing and electronic file sharing solved many problems, while introducing new ones. Every computer had its own fonts, printer drivers, and layout quirks. A report that looked perfect on one machine could print as a jumbled mess on another. Sharing files became a gamble.
To fix this, in 1991 Adobe co-founder John Warnock and his team launched a project codenamed “Camelot” to create a truly universal document format. The result was the PDF, a file that embedded fonts, graphics, and page layout all in one place. This “digital paper” guaranteed that documents looked exactly the same everywhere, whether on Windows, Mac, or any printer.
By bundling every font, image, and layout detail into a single file, PDFs let users share documents without surprises, and what you see on screen is printed exactly the same everywhere. Adobe made the free Acrobat Reader available in 1994, and within five years, PDF became the go-to format for everything from product manuals and corporate reports to government forms and academic papers.
By the early 2000s, “export as PDF” was a one-click option in almost every authoring tool, and organizations across industries embraced it for distribution, archiving, and compliance. And it’s still the standard today.
The PDF Design Trap
The very thing that made PDFs so appealing (their promise of pixel-perfect fidelity) also introduced a hidden trade-off: it locked content into a rigid, print-first structure.
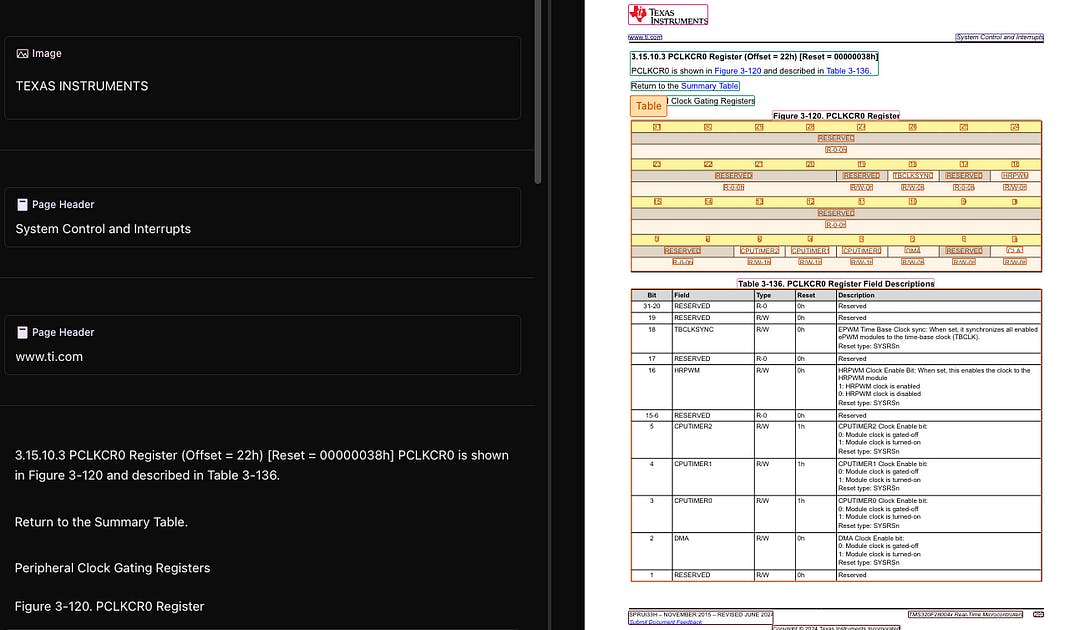
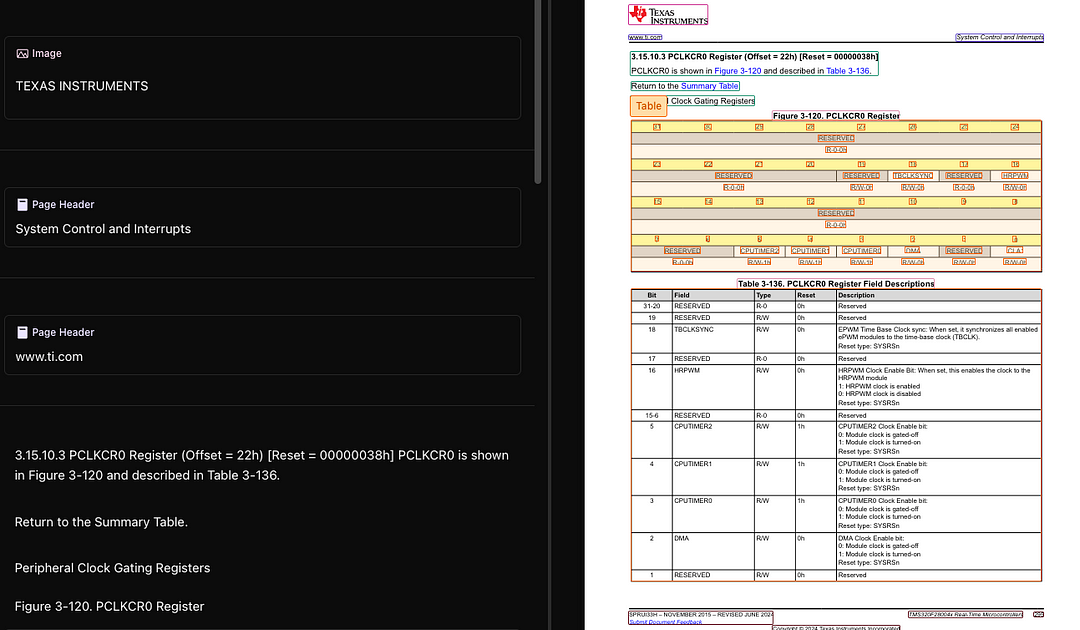
Beneath every flawless page was essentially a digital snapshot, built to mimic what came out of a printer. Headings, tables, paragraphs, none of it had semantic meaning. To a computer, it was just coordinates and text boxes scattered across a canvas.
At first, this didn’t matter. But as documents moved from desktops to web browsers, mobile screens, and automated pipelines, the cracks began to show. Want to extract clean data? Reflow text on a phone? Understand document structure? Suddenly, what looked clean to humans became a mess for machines.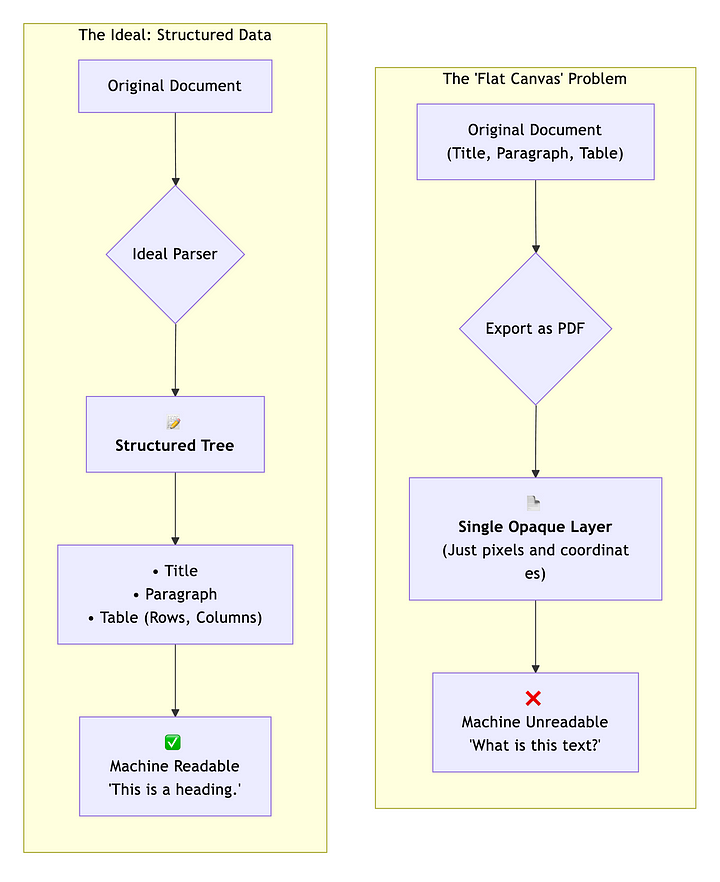
Tagged PDF and Other Modernization Attempts
Adobe wasn’t blind to the problem. Tagged PDF (introduced in 2001 and later formalized in PDF/UA for accessibility) adds an HTML-like logical structure. It never became universal, but it is mandated for accessible government documents and widely used in large-enterprise workflows. Other milestones, such as PDF/A for long-term archiving, XMP metadata support, and the 2008 hand-off of the spec to ISO, show steady efforts to modernize the format. Still, broad adoption lagged; tagging is invisible to most users, tedious for creators, and often stripped out by careless export settings.
A whole ecosystem of SaaS tools popped up to bridge this gap. You see it in heavyweights like DocuSign, in the many web-based PDF editors such as DocHub, and in open-source libraries like Poppler, which developers depend on just to pull text out of PDFs.
That’s also why the big cloud players are all throwing serious AI muscle at this problem: AWS with Textract, Google with Document AI, and Microsoft with Azure AI Document Intelligence. The market emerged, products followed, and plenty of revenue flowed. Adobe, whether we like it or not, changed the game.
The Rise of AI-Native PDF Handling
When ChatGPT hit, the “PDF problem” exploded. Companies scrambled to feed their data into LLMs, only to hit a wall: most of that valuable info was locked away inside PDFs.
At first, the goal was simple: just extract clean text for Retrieval-Augmented Generation (RAG). But that quickly proved too basic. Without layout awareness, text from columns got scrambled, tables turned into nonsense, images got ignored, and important context disappeared.
Modern Document AI now trains models to understand a document’s visual and logical layout: identifying titles, paragraphs, tables, and images. So, AI can reference information, skip repeated headers/footers, and grasp the overall structure.
This AI stack reveals the full extent of the mess we’re dealing with. What should be straightforward data extraction now requires multiple specialized layers:
- Layout analysis to understand document structure,
- OCR to extract text from images and scanned documents,
- VLM orchestration to coordinate these different AI components.
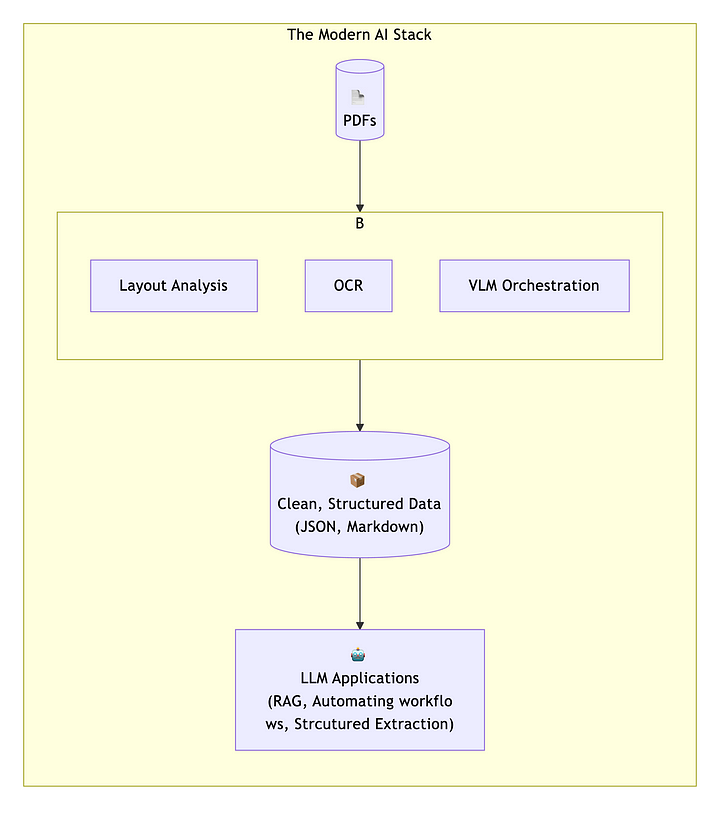
Each layer adds latency, potential errors, and compute cost. The irony is staggering: we’re using some of the most advanced AI models ever built to solve a problem that stems from a 30-year-old decision to treat documents like photographs.
While PDFs have gradually evolved, their print-first DNA keeps piling costs onto every modern workflow. Structured formats, scanned or photographed, do introduce some of the same hurdles, but PDF’s design amplifies the pain.
A Path Forward
We can’t scrap decades of PDFs overnight, but we can avoid repeating history. For new content, choose born-digital formats that preserve semantics by default:
- HTML5 for the web,
- Markdown-derived standards for technical docs,
- or DOCX/OOXML when Office compatibility is a must.
When a fixed-layout file is unavoidable, export with full tags and metadata intact; some authoring tools now automate this. Government procurement rules that require PDF/UA compliance are a positive precedent. Similar pressure from enterprises on vendors and regulators can push tagging from “nice-to-have” to “table stakes.”
Long term, open standards like W3C’s Portable Web Publication or EPUB 3, along with upcoming containerized JSON-based formats, promise fidelity without sacrificing structure. Supporting these in mainstream authoring tools (and educating users to adopt them) will spare the next generation from writing vision models just to pull text out of a contract.
The story of PDFs proves that early design choices echo for decades. The lesson isn’t to vilify the engineers who solved 1991’s problem; it’s to recognize that today’s “good enough” shortcuts become tomorrow’s costly handcuffs. Let’s embed semantics at the source, back open, machine-readable standards, and ensure the next wave of document tech is built for humans and machines alike.
For teams already dealing with legacy formats, tools like Chunkr offer an Open-Source API-based pipeline to convert complex documents into structured, chunked formats tailored for LLM and RAG workflows, available both as hosted endpoints or self-managed infrastructure.
Struggling to Grow Your Audience as a Tech Professional?
The Tech Audience Accelerator is the go-to newsletter for tech creators serious about growing their audience. You’ll get the proven frameworks, templates, and tactics behind my 30M+ impressions (and counting).
https://techaudienceaccelerator.substack.com/?embedable=true
[story continues]
tags