
Table of Links
-
Related Works
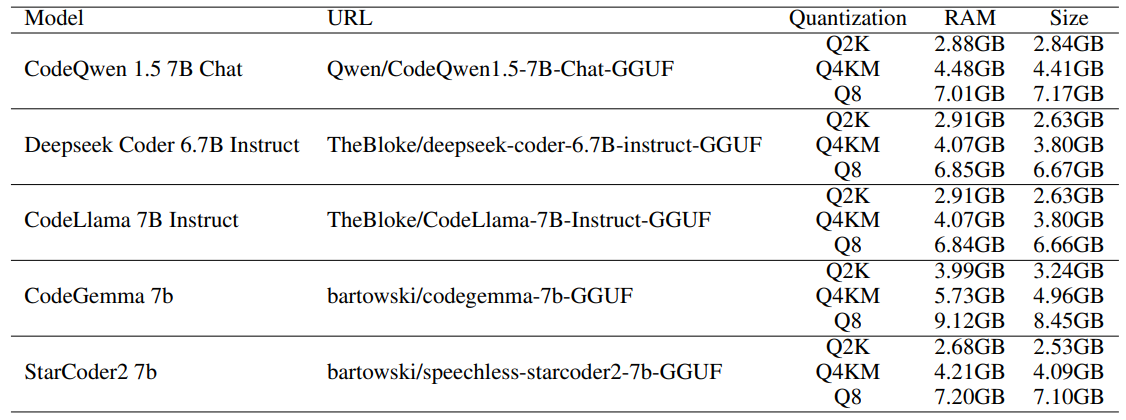
2.3 Evaluation benchmarks for code LLMs and 2.4 Evaluation metrics
-
Methodology
-
Evaluation
3.3 Choice of benchmarks
Lua is a scripting language primarily for embedded use such as scripting in game engines and embedded devices [37]. Due to its niche application, Lua is considered a low-resource language [14] compared to other languages such as Python, Java, and JavaScript. Low-resource languages are defined by the relatively smaller size of training data available for code LLMs. As a result, code LLMs are not as good at generating code in low-resource languages as in high-resource languages [33; 14]. Therefore, quantized models are more likely to demonstrate performance degradation when generating code in low-resource languages such as Lua. Moreover, Lua employs unconventional programming paradigms, such as metatables, that are hard to directly generalize from other programming languages. Finally, using a low-resource language mitigates the effects of instruction fine-tuning that can be biased toward specific languages. For these reasons, Lua makes a good test case for quantized models and for answering the research question RQ2.
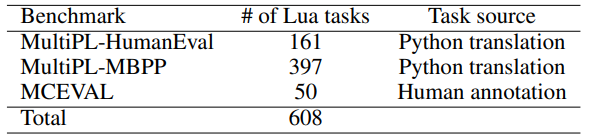
Because Lua is a low-resource language, most of the Lua-based benchmarks were derived from Python-based benchmarks listed in Table 2. MultiPL-E [33] is a multilingual benchmark that combines two Python-based benchmarks HumanEval [28] and MBPP [29] and translates them into 18 other programming languages including Lua. The Lua version of HumanEval and MBPP contain 161 and 397 programming tasks respectively. These programming tasks were used to test the quantized models.
MCEVAL [22] is another multilingual benchmark that covers 40 languages including Lua. MCEVAL has humangenerated tasks. This is in contrast to HumanEval and MBPP tasks, which were created for Python and may not fully reflect the uniqueness of the languages to which these tasks were translated. MCEVAL contains 50 code generation tasks for the Lua language. We used the 50 code generation tasks to test the quantized models.
Each code generation task in the above benchmarks involves generating a standalone function given a prompt. An example of a prompt is shown in Listing 1. The prompt includes a brief description of what the function should do, example calls to the function, and the expected returns from these calls. These are presented as Lua comments. The
final line in the prompt contains Luo code with a function signature. A model is expected to generate the rest of the function.

Author:
(1) Enkhbold Nyamsuren, School of Computer Science and IT University College Cork Cork, Ireland, T12 XF62 (enyamsuren@ucc.ie).
This paper is available on arxiv under CC BY-SA 4.0 license.
[story continues]
tags