
CocoIndex https://github.com/cocoindex-io/cocoindex is a ETL framework that helps you to turn your data ready for AI in realtime.
The essential part for supporting robust and efficient update is because of incremental update. In CocoIndex, users declare the transformation, and don't need to worry about the work to keep index and source in sync. In this blog we would like to share how we handled the incremental update.
If you like our work, it would mean a lot if you could support us ❤️ with a github star! https://github.com/cocoindex-io/cocoindex
CocoIndex creates & maintains an index, and keeps the derived index up to date based on source update, with minimal computation and changes. That makes it suitable for ETL/RAG or any transformation tasks stays low latency between source and index updates, and also minimizes the computation cost.
What is Incremental Updates?
Figuring out what exactly need to be updated, and only update that without having to recompute everything throughout.
How does it work?
You don't really need to do anything special, just focus on define the transformation need.

CocoIndex automatically tracks the lineage of your data and maintains a cache of computation results. When you update your source data, CocoIndex will:
-
Identify which parts of the data have changed
-
Only recompute transformations for the changed data
-
Reuse cached results for unchanged data
-
Update the index with minimal changes
And CocoIndex will handle the incremental updates for you.
CocoIndex provide two modes with pipeline with simple configuration:
- batch mode - for one time update.
- live update mode - long running pipeline, with live update. Both modes runs with incremental updates.
Who needs Incremental Updates?
Many people may think incremental updates is only beneficial for large scale data, thinking carefully, it really depends on the cost and requirement for data freshness.
Google processed large scale data, and google has huge resources for it. Your data scale is much less than Google, but your resource provision is also much less than Google.
Real condition for incremental update needs is:
- high freshness requirement, for example, you client has GDPR compliance, you need to update the index with the latest data.
- transformation cost is significant higher than retrieval itself
Overall, say T is your most acceptable staleness, if you don't want to recompute the whole thing repeatedly every T, then you need incremental more or less.
What exactly is incremental updates, with examples
Well, we could take a look at a few examples to understand how it works.
Example 1: Update a document
Consider this scenario:
- I have a document. Initially, it's split into 5 chunks, resulting in 5 rows with their embeddings in the index.
- After it's updated. 3 of them are exactly same as previous; others have changed
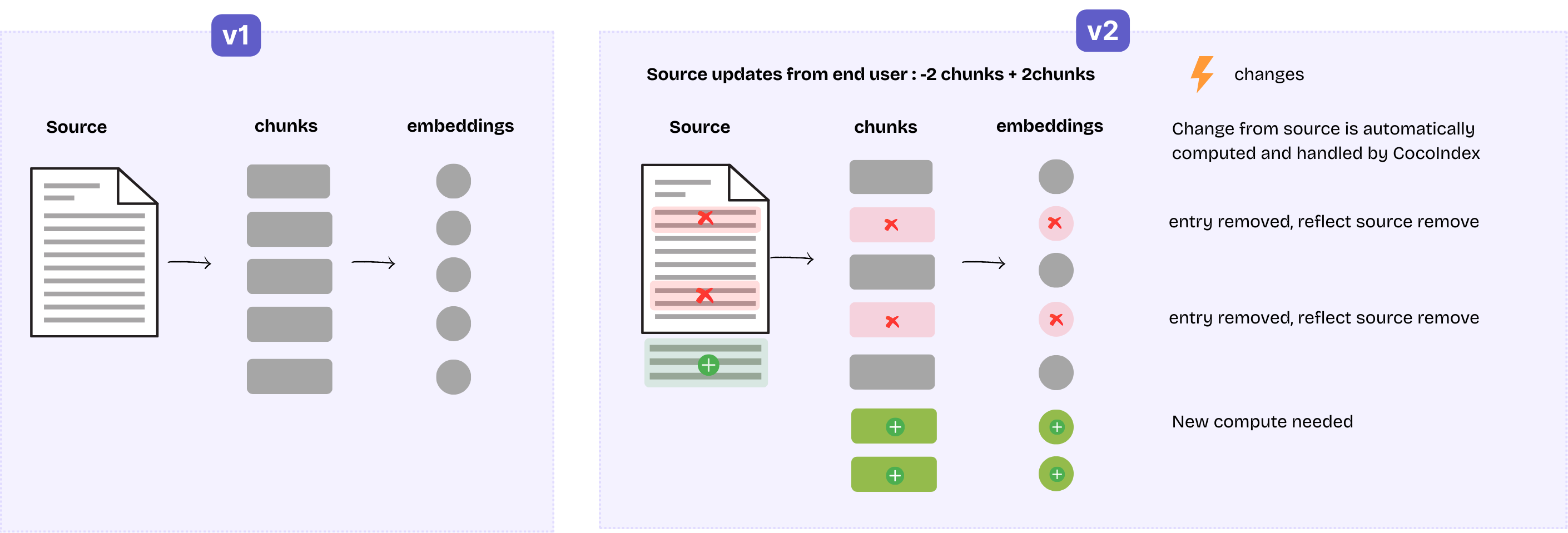
So we need to keep 3 rows, remove 2 previously existing rows, and add 2 new rows. These need to happen behind the scene:
- Ideally, we only recompute embeddings for the 4 new rows, and reuse it for 3 unchanged chunks. This can save computation cost especially when the embedding API charge by usage. CocoIndex achieves this by maintaining a cache for heavy steps like embedding, and on the input for a transformation step isn't changed, the output will be reused.
- Besides, we also maintain a lineage tracking in the internal storage. It keeps track of which rows in the index are derived from the previous version of this document, to make sure stale versions are properly removed.
CocoIndex takes care of this.
Example 2: Delete a document
Contining with the same example. If we delete the document later, we need to delete all 7 rows derived from the document. Again, this needs to be based on the lineage tracking maintained by CocoIndex.
Example 3: Change of the transformation flow
The transformation flow may also be changed, for example, the chunking logic is upgraded, or a parameter passed to the chunker is adjusted. This may result in the following scenario:
- Before the change, the document is split into 5 chunks, resulting in 5 rows with their embeddings in the index.
- After the change, they become 6 chunks: 4 of previous chunks remain unchanged, the remaining 1 is split into 2 smaller chunks.
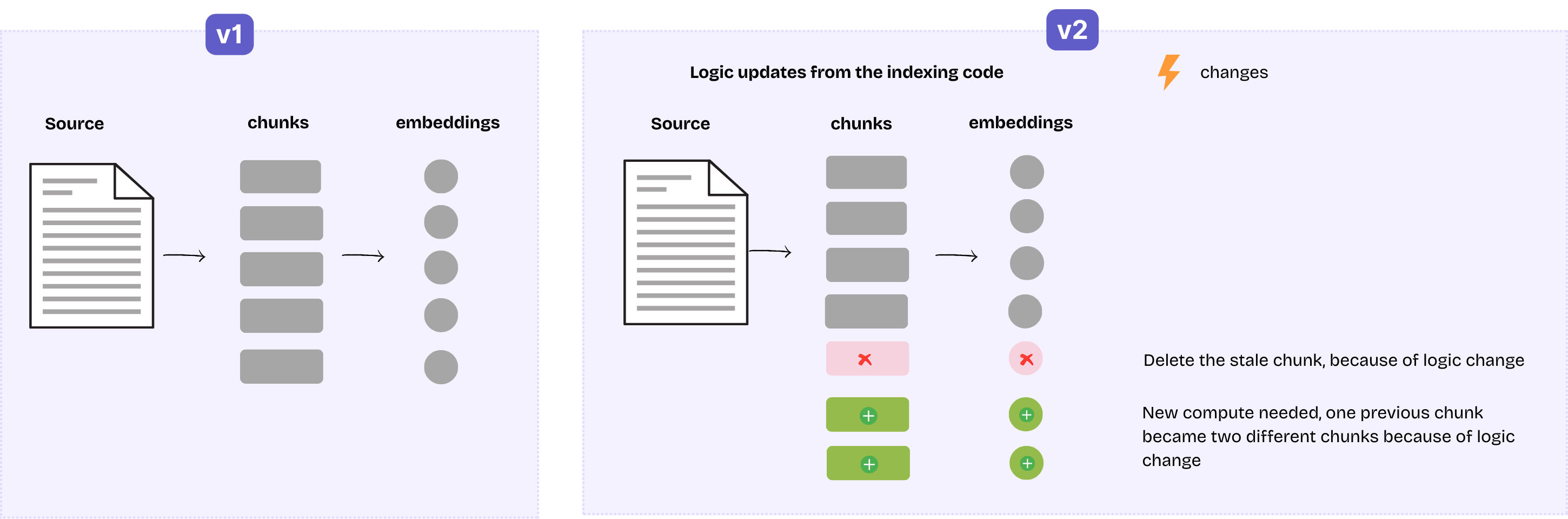
This falls into a similar situation as document update (example 1), and CocoIndex will take care of it. The approach is similar, while this involves some additional considerations:
- We can still safely reuse embeddings for 4 unchanged chunks by the caching mechanism: this needs an prequisite that the logic and spec for embedding is unchanged. If the changed part is the embedding logic or spec, we will recompute the embeddings for everything. CocoIndex is able to see if the logic or spec for a operation step is changed from the cached version, by putting these additional information in the cache key.
- To remove stale rows in the target index, the lineage tracking works well again. Note that some other systems handle stale output deletions on source update/deletion by replaying the transformation logic on the previous version of input: this only works well when transformation is fully deterministic and never upgraded. CocoIndex's lineage tracking based approach doesn't have this limitation: it's robust to transformation logic non-determinism and changes.
Example 4: Multiple inputs involved: Merge / Lookup / Clustering
All examples above are simple cases: each single input row (e.g. a document) is involved independently during each specific transformation.
CocoIndex is a highly customizable framework, not only limited to simple chunking and embedding. It allows users for more complex advanced transformations, such as:
- Merge. For example, you're bulding an index for "all AI products", and you want to combine information from multiple sources, some product exists in one source and some in multiple. For each product, you want to combine information from different sources.
- Lookup. For example, you also have a data source about company information. During you transformation for each product, you want to enrich it with information of the company building the product, so a lookup for the company information is needed.
- Clustering. For example, you want to cluster different products into scenarios, and create cluster-level summaries based on information of products in the cluster.
The common theme is that during transformation, multiple input rows (coming from single or multiple sources) need to be involved at the same time. Once a single input row is updated or deleted, CocoIndex will need to fetch other related rows from the the same or other sources. Here which other rows are needed is based on which are involved in the transformations. CocoIndex keeps track of such relationships, and will fetch related rows and trigger necessary reprocessings incrementally.
Change Data Capture (CDC)
1. When source supports push change
Some source connectors support push change. For example, Google Drive supports drive-level changelog and send change notifications to your public URL, which is applicable for team drive and personal drive (only by OAuth, service account not supported). When a file is created, updated, or deleted, CocoIndex could compute based on the diff.
2. Metadata-based, last modified only
Some source connectors don't support push change, but provide metadata and file system operations that list most recent changed files. For example, Google Drive with service account.
CocoIndex could monitor the change based on last modified vs last poll time, periodic trigger to check modified. However this cannot capture full change, for example a file has been deleted.
3. Metadata-based, Fullscan
Some source connectors have limited capabilities with listing files, but provide metadata that list all files. For example, with local files, we'd need to traverse all files in all directories and subdirectories recursively to get the full list.
When the number of files is large, it's expensive to traverse all files.
Cache
In CocoIndex, every piece of the lego block in the pipeline can be cached. Custom functions can take a paramter cache. When True, the executor will cache the result of the function for reuse during reprocessing. We recommend to set this to True for any function that is computationally intensive.
Output will be reused if all these unchanged: spec (if exists), input data, behavior of the function. For this purpose, a behavior_version needs to be provided, and should increase on behavior changes.
For example, this enables cache for a standalone function, see full code example here:
@cocoindex.op.executor_class(gpu=True, cache=True, behavior_version=1)
class PdfToMarkdownExecutor:
"""Executor for PdfToMarkdown."""
...
[story continues]
tags