
I spent weeks debugging an agent that kept “forgetting” contexts mid-task. The agent had access to 1M context window, which should have been enough. But it wasn’t. It would repeat steps it had already completed, refetch data it had already seen, and occasionally ignore tool outputs that were technically still in the context. The logs looked fine. The context was huge. Nothing obvious was broken.
The problem was not context window capacity. The problem was me treating the context window as a memory.
Modern AI agents do not “have memory” in a single place. They manage multiple interacting memory layers, including a limited context window, a session history store, a condensation/compaction subsystem, a durable store across sessions, and retrieval tools to pull content into the model's attention. These multiple memory layers exist because agents' loops can produce far more context than what they can reliably hold across turns, and when the context is bloated, the model performs worse and is less accurate. Most agent systems don’t fail because the models are weak. They fail because memory is poorly designed, and the most common mistake is treating context as memory.
When an LLM becomes an agent, memory is no longer optional
When an LLM is placed in an action observation loop, two pressures increase sharply:
-
Context growth: Each tool call produces observations that are often very large in size and are appended as the input for the next decision. This unbounded growth affects the model's productivity and the quality of the output.
-
Cost skews toward input: Manus, one of the current top agents, reports an average input to output token ratio of 100:1. So a large input is often provided for a small response, sometimes just a tool call.
This is where things start to break. The agent is not generating text anymore; it is accumulating state.
Very commonly, the agent's tasks are quite different from regular chat. They often do web browsing and tool use, which provides very diverse and often unstructured responses. These extremely long contexts make it necessary for agents to use a more intelligent store + condensation + retrieval-based memory system.
Context Windows Are Not Memory
Today, most models support large context windows such as 1M tokens. But even with that, it is clear that the context window is a working area and should not be treated as memory.
Some practical reasons include:
- Observations can be huge (web pages/PDFs)
- Model
performance can degrade beyond some context length - Long inputs are expensive, even with caching.
A useful mental model is this: context is a CPU cache, not a database. It is finite, expensive, and performance sensitive and optimized for immediate computation, not long-term retention.
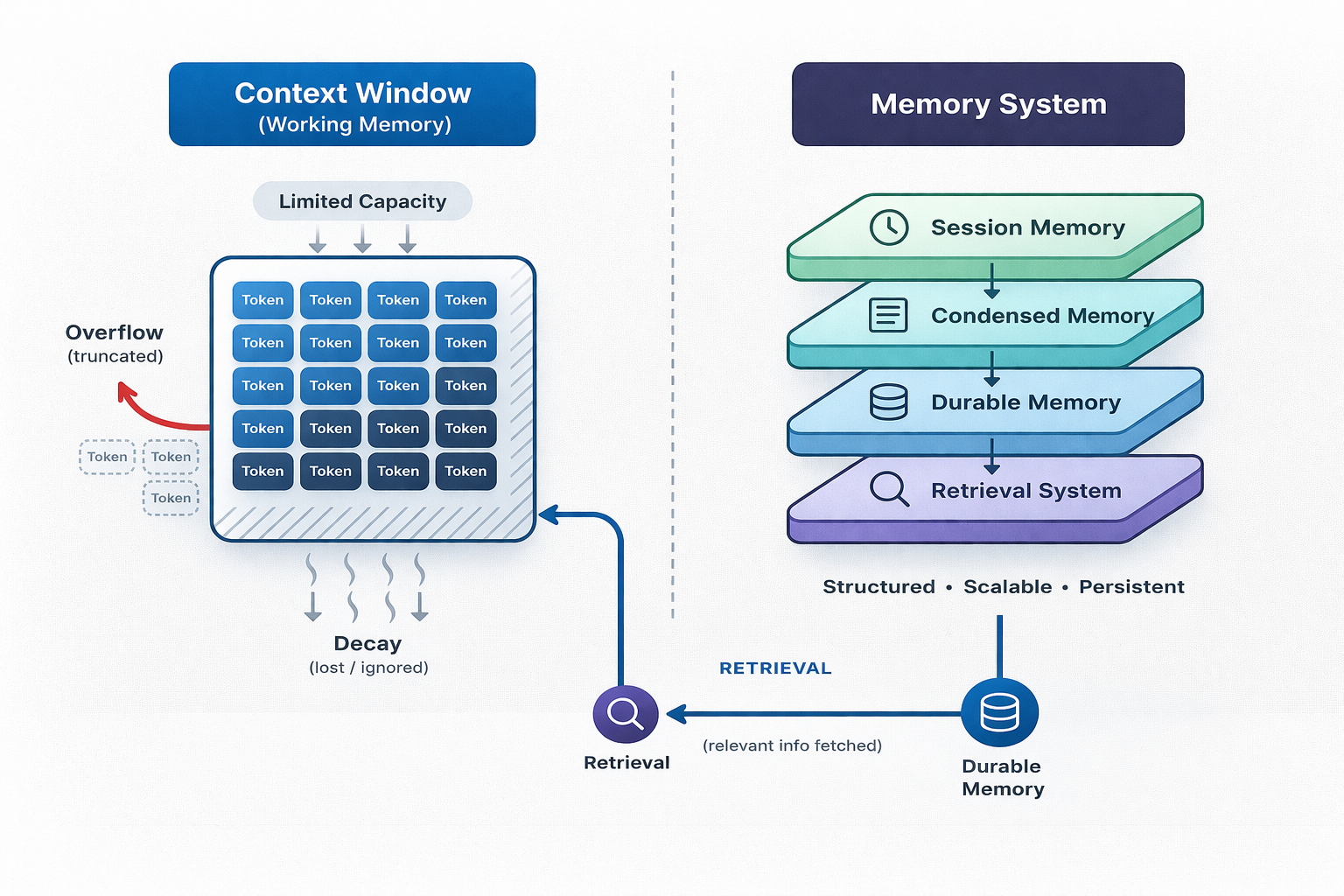
The Five Memory Layers Common in Modern Agents
After building several agent systems and studying practical implementations like OpenClaw, I have come to see agent memory as five distinct layers. I did not start with this model; it emerged after repeatedly seeing failures happen at different boundaries in the system. That is when I realized memory was not one thing. It was multiple systems interacting, each with different constraints.
This breakdown is not academic - but it is a practical layout that helps your agent from breaking down at scale. It separates storage from selection and persistence from attention, which is where most real failures occur.
Working Memory
Working memory is simply the tokens the model sees at each step. It includes instructions, recent dialogues, and any in-window structures. These are not durable and are reassembled every step. All agent ecosystems have improved the size of their working memory, but the associated “context rot” is real, and contexts are finite attention budgets with diminishing returns.
Session Memory
Session memory maintains a conversational continuity across turns. It stores user/assistant messages and tool results across turns so that they don’t have to be manually stitched together for each turn. These are usually implemented as client-side memory that maintains conversation history across multiple runs, eliminating the need to manually append prior outputs. Session memory is scoped per session but can still grow unbounded if unmanaged and can potentially need compaction.
Condensed Memory
This is where things get interesting. When you reach context limit, you need compaction. Condensed memory is a lossy representation of prior history, produced to keep the working context limits and reduce latency/cost. The common pattern for condensed memory is that when the context reaches a limit for a session, compaction is triggered. Compaction summarizes everything before the boundary (the last N conversations are kept verbatim). The summary is injected as summary events or a synthetic conversation pair. The condensation can be done one time and overwrite the context, but irreversible compression can be tricky since it is impossible to recover a conversation that might matter later. Condensation is where correctness is traded for efficiency.
Durable Memory
Durable memory is what persists across sessions. There are instructions, preferences, and long-lived facts. Durable memory is usually curated and not simple transcripts and conversations. A few different approaches are used for this, such as plain markdown files with instructions for the agents. Common examples are
Retrieval Memory
Retrieval memory is the indexing + tooling layer that takes the durable store into usable attention at the moment of need. These included
How OpenClaw And Others Manage Memory
OpenClaw is a particularly inspectable reference implementation as it makes a specific choice: memory is just files and indexing is derived. Memory is plain Markdown files in the agent workspace, and files are the source of truth. The agent only remembers what is written on the file.
OpenClaw has two different layouts:
-
memory/YYYY-MM-DD as an appended daily log, read for today + yesterday during the session start.
-
MEMORY.md is the curated long-term memory for the instruction preferences and cross-session context.
This design clearly separates the running context from the durable preferences/decision memory, reducing the chance of context rot while making everything human auditable.
To prevent compaction from memory flush, OpenClaw implements a pre-compaction memory flush. When the context is nearly complete, it triggers a silent turn with NO_REPLY, asking the model to write out the durable context to disk. This housekeeping task is invisible to the users, but handles the important goal of pre-compaction flush.
Retrieval in OpenClaw is equally explicit. It exposes memory_search and memory_get tools on top of a SQLite index. It combines a
This design of OpenClaw was notable because of a shift from a “black-box” embedding only memory systems to human-readable daily markdown logs and vector databases, alongside as an index, not as the canonical store.
Where agent memory starts to break
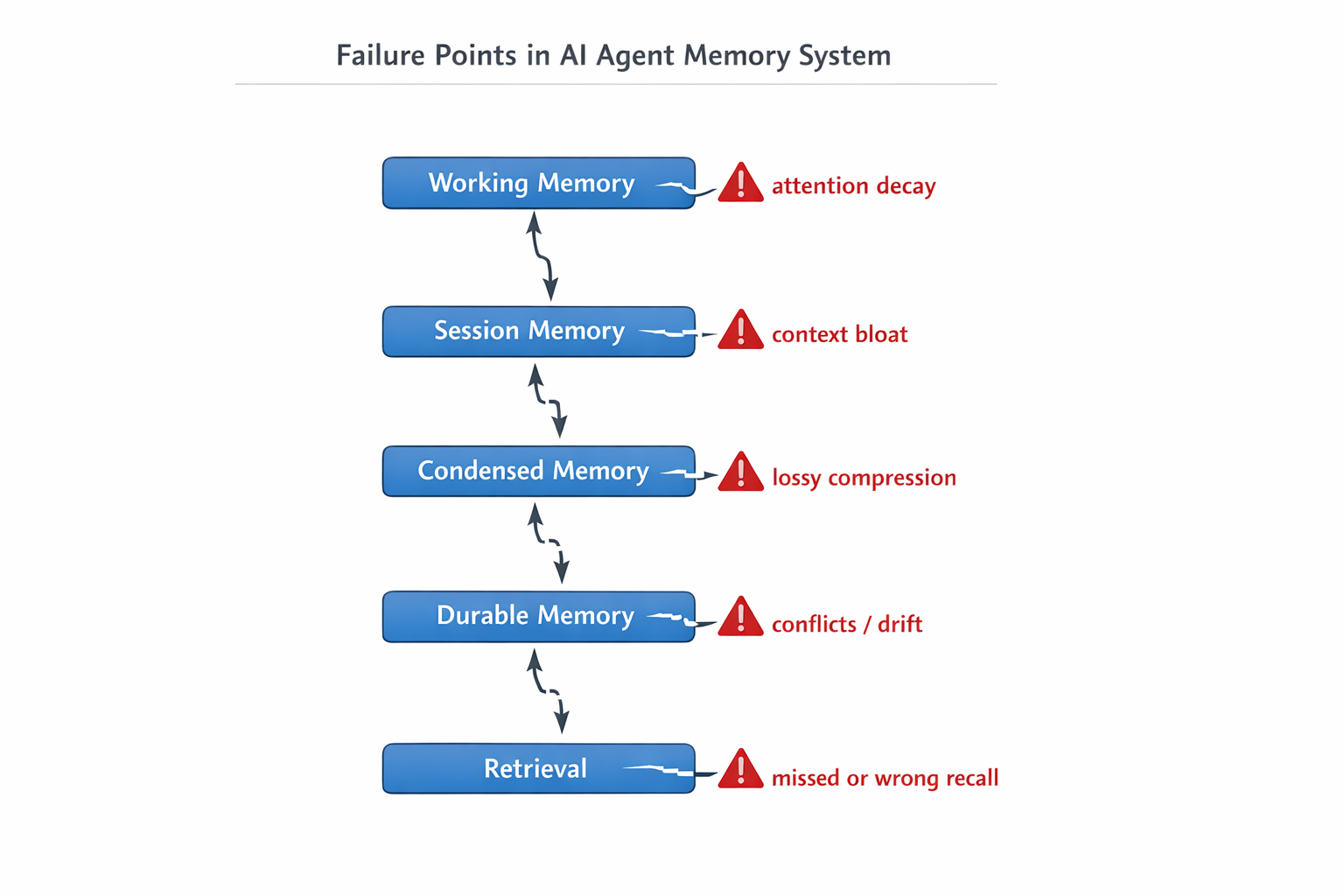
Memory failures in these agents are usually not as simple as agents forgetting. It happens between the boundaries of the layers.
- Working memory overload and attention decay
- The model starts ignoring earlier instructions or starts prioritizing recent, less relevant tokens.
- Session memory bloat and poisoning via tool traces
- Large tool outputs dominate the context, pushing out critical reasoning steps.
- Condensation/Compaction distortion
- Summaries drop key constraints, leading the agents to make key decisions based on incomplete history.
- Durable memory drift, conflict, and injection.
- Older preferences override newer instructions, or conflicting facts coexist without resolution.
- Retrieval failures: stale, redundant, or missed recall.
- The correct memory exists, but is never retrieved at the right time, or irrelevant memories are injected instead.
A Good Memory System Does Not Store More. It Forgets Better
The most “state of the art” aspect of modern memory is not bigger storage, it is better forgetting policies. The need for forgetting is not a bug because even though modern models keep improving their context window sizes, the unbounded growth of context degrades the response quality over time.
Forgetting better does not mean blindly deleting evidence or data based on recency. It means identifying the keeping only the smallest set of high-value tokens that maximizes output quality by deleting anything else that is superfluous and safe to delete. But this is easier said than done. In most cases, it might be better to keep the wrong stuff in than accidentally delete the right stuff. Hence, the policies used should be very nuanced and have clear bias for evidence and decision-making. Also, condensation events can drop old events and insert summaries while preserving the full event log for inspection and potential replay, separating “what the model attends to now” from “what the systems retain.”
What To Look For In Any Agent Memory Design
Based on my experience and patterns for production systems, here’s what to look for:
A canonical source of truth you can inspect and edit: if you cannot look at the agent memory and understand what the agent knows, debugging becomes more of a guesswork. This does not necessarily mean memory should be stored as readable text or markdown files, but they should be auditable. Similarly, there is a need for a clear separation between “journal” and “policy” memory.
Explicit lifecycle governance: Contexts go through the process of distill, consolidate, and inject repeatedly. But the actual process for this needs to be explicit about the dedupe/conflict resolution and the precedence rules and safety guidance for the reinjection of the condensed context. Memory systems can fail if defaults overpower current instructions, for example. An explicit precedence such as “latest user message wins; sessions override global; recency resolves conflicts within a list is not optional.
High retrieval quality and restorable compression: A retrieval system based on simple
If you cannot reliably explain what the agent remembers and why, you cannot reliably debug or improve it.
Conclusion
Modern agent memory management is a layered system that needs continuous budgeted attention. The central shift is from storing “more context” to engineering the smallest, highest-signal working set, using condensation to bound growth and durable artifacts for persistent state. Reliable personalization needs explicit memory lifecycle machinery for distillation, condensation, precedence rules, and right retrieval.
This is why memory is governance, not storage. Systems that treat memory as just a bigger context eventually fail. Systems that build an engineered lifecycle of curatable, compressible, and auditable memory systems perform well over long-running workloads.
If you are building agents, start by mapping your memory architecture to these five layers. Figure out a compaction strategy before you hit your context limit. Make your durable memory auditable. And remember, the goal isn’t perfect recall; it is retrieving the right information at the right time, while safely forgetting whatever is unnecessary.
[story continues]
tags