
Across early-stage startups, I keep seeing the same pattern: engineers set up master and develop branches, formal release cycles, and staging environments. Not because the business needs them, but because that's what they did at their last job.
This is the third article in my series on mental models for startups (please check it out, there's a lot of interesting material there). This time, we're looking at release processes.
It usually happens when the product is just getting started. The real challenge not stability, it is finding revenue and users. Engineering practices come from habit, not necessity and usually from previous jobs at bigger companies where production failures were expensive and heavy process was the right response.
But in a startup, bringing in those processes too early pulls focus away from learning and toward ceremony. It adds friction exactly when speed matters most.
This mismatch between what the business actually needs and how the team releases code is where the mental models below come in. Each one offers a different way to think about release decisions, along with practical advice on what actually works when you're pre-revenue and still searching for fit.
Who is this for? This is for founders and engineers who sense their process is slowing them down but aren't sure why.
Mental Model 1 or Your Release Process Is a Projection of Fear
A release process isn't neutral infrastructure, but it is a mirror of what the team is most afraid of breaking.
If the deepest fear is breaking production (regressions, outages, lost trust) you build fortresses: staging environments, approval gates, lengthy reviews, release trains.
If the deepest fear is building the wrong thing (wasting time on features nobody wants, missing product-market fit) you build sensors: fast deploys, rapid feedback loops, constant experimentation.
Most teams never make this choice consciously. They inherit workflows from past jobs, copy "best practices" from Big Tech blogs, or default to whatever feels professional. The result is a process shaped by someone else's reality and almost always the reality of a mature company with paying customers, compliance needs, and serious consequences for downtime.
Release fear has to match your current stage. Every software company lives with two fears that never fully disappear:
- Execution risk: Shipping bugs, breaking what works, damaging production.
- Discovery risk: Building the wrong thing, missing fit, running out of runway.
These fears pull in opposite directions, and your release process is the mechanism that chooses between them. Heavy processes like staging gates, approvals, and release trains insure against execution risk. Lightweight processes like trunk-based development, continuous deploy, and feature flags insure against discovery risk.
The tradeoff is real, but it's not symmetric. A bug in production is a problem you can fix in an hour. Building the wrong product for six months is a problem you might not recover from.
You can't fully hedge both. The right choice almost always follows the company's stage:
- Pre-revenue, pre-PMF: You're still proving the core hypothesis, so almost nobody outside the team uses the product. The house barely exists yet — insuring it against fire is premature. Fear irrelevance, not instability. Ship often, learn faster than your competitors. Bugs are embarrassing but survivable. Building something nobody wants is fatal.
- Post-PMF, with revenue: Real customers depend on you, so downtime means lost revenue, churn, reputational damage. Now execution risk becomes existential. It's time to invest in stability: gates, testing, rollbacks, observability.
The fear should evolve as the business does. A process that's perfect at one stage becomes actively harmful at another.
Before debating branches, pipelines, or review rules, pause and answer three questions:
- What am I actually most afraid of right now: breaking something that works, or building something that doesn't matter?
- Do I have paying customers who depend on reliability, or am I still searching for the first ones?
- Is this process shaped by my current reality, or am I carrying forward someone else's old fears?
Mental Model 2 — Borrowed Maturity
Importing release structures from mature companies creates the illusion of progress while silently reducing learning velocity.
Process is comfort. When product-market fit is uncertain and the next pivot could be tomorrow, a familiar workflow feels like solid ground. But your release process doesn't just reflect how you ship code. It reflects what your business actually is.
Conway's Law tells us software architecture mirrors organizational structure. There should be a corollary: release process mirrors business certainty. A company that knows what it's building releases differently than one still figuring it out.
I've watched this pattern firsthand. A pre-revenue startup with zero paying users, where the product was still a hypothesis. Instead of testing that hypothesis, the first month went into "proper" infrastructure: develop and main branches, separate staging and prod environments, CI/CD pipelines, Jira and Jira templates. The full enterprise stack, lol.
It looked professional but we had two environments for software that zero humans outside the team had touched. A release process for a product that didn't need releases. It needed experiments.
Release Processes: A Reality Check
|
Process |
How It Works |
Startup Fit (pre-PMF) |
Why |
|---|---|---|---|
|
GitFlow |
Work happens on a separate develop branch while main stays stable. Features and fixes are merged in batches, with dedicated release and hotfix branches used to control when changes reach production. |
Poor ❌ |
Batching delays feedback and hides problems. |
|
GitHub Flow |
New work is done on short-lived feature branches. Each change goes through a pull request, is reviewed, merged into main, and then deployed continuously. |
Good ✅ |
Reviews add latency to learning. |
|
Trunk Based |
Developers commit small changes directly to main or merge very short-lived branches. Unfinished features are hidden with flags and deployments happen frequently. |
Good ✅ |
Fast feedback, break it all faster. |
|
Release Trains |
Releases happen on a fixed schedule. Features that are ready ship with the next train, while unfinished work waits for the following one. |
Poor ❌ |
Calendars slow discovery. |
Startups and mature companies live in different worlds — and each world dictates its own survival rules.
Mature companies optimize for coordination risk. Large teams, parallel workstreams, high cost of production failure makes GitFlow and similar processes as a reasonable choice, minimize merge hell and chaos.
Startups need to optimize for learning latency. The dominant risk isn't breaking production (you barely have users). It's building something nobody wants so feedback speed determines everything.
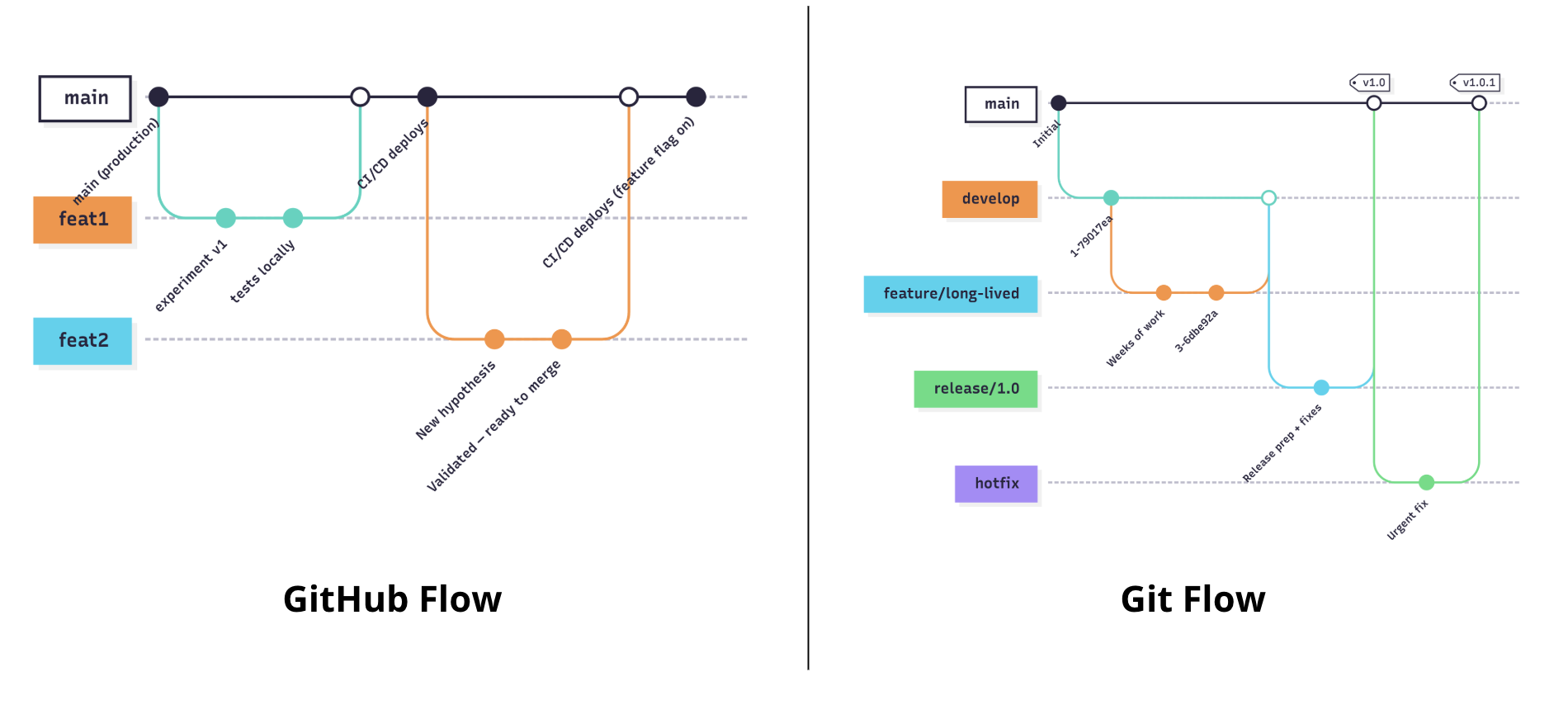
Copying GitFlow (or any heavy process) shifts your bottleneck from discovery to ceremony. You're not reducing risk — you're hiding it behind process.
Your competitor with a messy Git history shipped three experiments last week. You're still waiting for the release branch to stabilize.
Borrowed maturity creates a false sense of safety.
- Long cycles make pivots expensive
- Big feature branches hide integration problems until late
- Review overhead burns cognitive energy better spent on users
The process looks serious on the outside. Inside, it delays the very learning that determines whether the company lives or dies.
Practicals
1. GitHub Flow is enough. One protected main branch with short-lived feature branches that last hours or days, not weeks. Deploy directly from main to production. No develop branch, no release branches, no hotfix branches. If three engineers need a branching strategy diagram, something is already wrong.
2. Test in production. This sounds reckless but it's not. With feature flags and solid observability, production is the only environment that tells the truth, and staging environments are expensive lies you maintain to feel safe.
3. Feature flags are non-negotiable. They let you separate shipping from releasing, which means you can deploy code daily and toggle features on when they're ready. Flags let you ship incomplete work invisibly, A/B test with real users, segment paid versus experimental features, and kill failures instantly.
4. Preview deployments for every change. Tools like Vercel, Netlify, Render, and Railway generate unique preview URLs for every PR, so stakeholders see real changes instantly without a shared staging environment to maintain and without "works on my machine" excuses. Just a link.
5. AI-assisted code reviews over waiting for humans. At this stage, unit test coverage is overrated because you don't need 80% coverage, you need fast catches. Tools like GitHub Copilot, Cursor, or dedicated PR review bots flag obvious issues instantly, which is faster and cheaper than blocking on a teammate.
6. Observability over exhaustive testing. Use Sentry for errors and PostHog or Mixpanel for user behavior, with everything alerting directly to Slack so you know when something breaks in seconds rather than when a frustrated user emails.
7. Slack as mission control. Route error alerts, deployment notifications, analytics events, and in-app feedback to dedicated channels, and add a simple feedback widget to your product so users become your real-time QA team.
**8. Optimize for fast recovery, not perfect prevention.**A 5-minute rollback beats a 2-day QA cycle, so ship often, observe closely, and revert instantly if something breaks.
Bottom Line
Your release process is a bet on what will kill you first. Before product-market fit, the danger is building the wrong thing while runway shrinks.
- Process reflects fear. Know which fear matches your stage.
- Borrowed maturity is expensive. That GitFlow setup made sense at your last company. It probably doesn't now.
- Reversibility beats stability. Optimize for how fast you can change direction, not how solid the foundation feels.
Ship fast. Learn faster.
[story continues]
tags