
We had this problem where we needed to update our Elasticsearch mappings without breaking search during deployments. Our setup is pretty standard: Spring Boot app with Hibernate Search indexing product data to Elasticsearch, running on Kubernetes with rolling deployments. Works great until you need to change your search schema.
The main issue is that during rolling deployments, you've got old and new pods running simultaneously, and they expect different index structures and mappings. Updating schemas require a downtime while the new index is built and documents are indexed.
The Problem We Faced
Our specific pain points were:
- Adding new fields without breaking existing functionality
- Changing analysers or field mappings without having a search outage
- Keeping search functional while pods cycle through versions
- Managing the coexistence period where half your pods run the old version and half run the new version
That last one really got us. Kubernetes rolling deployments are great, but they assume your app versions can coexist peacefully. When your database schema changes, that assumption breaks down pretty quickly. We didn't actually solve this problem, we ensured that mixed versions don't break anything during the transition phase.
Why We Avoided Complex Solutions
When we started planning this, we went down some rabbit holes. Spent weeks looking at complex approaches that seemed good on paper.
Alias-based index management with background reindexing sounded clever. I was really into this idea of all these fancy aliases switching around in the background. But when I actually thought about debugging it during an incident, it seemed too complicated.
Blue-green deployments would definitely work. But running two complete Elasticsearch clusters just for search deployments seemed like overkill for our setup.
External orchestration tools - We looked at a few. But we already had enough moving pieces. Adding another service that could fail during deployments felt risky and required more maintenance.
At some point we realised we were making this way too complicated. That's when we stepped back and thought about it differently.
How It Actually Works
So here's what we ended up doing. Each schema version gets its own index, pretty simple when you think about it. When you deploy v2 of your app, it creates a products_v2 index while the v1 pods keep tagging along with products_v1.
During the rolling deployment, requests can hit either version, but that turned out to be fine. Each pod just searches its own index and returns valid results. Once the deployment wraps up and all pods are running v2, you can clean up the old index.
Here's what actually happens during a deployment:
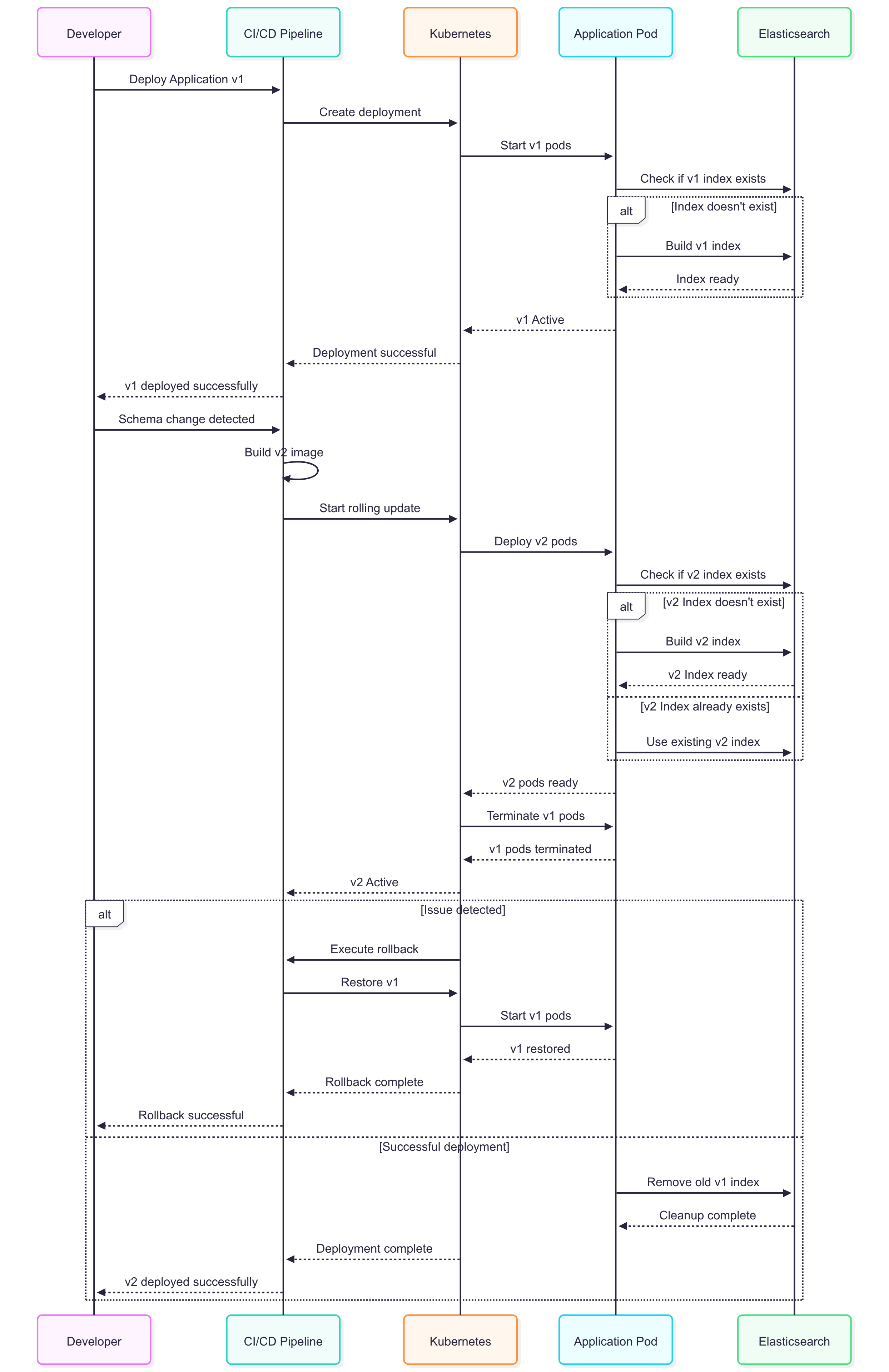
sequenceDiagram
participant Dev as Developer
participant CI as CI/CD Pipeline
participant K8s as Kubernetes
participant App as Application Pod
participant ES as Elasticsearch
Dev->>CI: Deploy Application v1
CI->>K8s: Create deployment
K8s->>App: Start v1 pods
App->>ES: Check if v1 index exists
alt Index doesn't exist
App->>ES: Build v1 index
ES-->>App: Index ready
end
App-->>K8s: v1 Active
K8s-->>CI: Deployment successful
CI-->>Dev: v1 deployed successfully
Dev->>CI: Schema change detected
CI->>CI: Build v2 image
CI->>K8s: Start rolling update
K8s->>App: Deploy v2 pods
App->>ES: Check if v2 index exists
alt v2 Index doesn't exist
App->>ES: Build v2 index
ES-->>App: v2 Index ready
else v2 Index already exists
App->>ES: Use existing v2 index
end
App-->>K8s: v2 pods ready
K8s->>App: Terminate v1 pods
App-->>K8s: v1 pods terminated
K8s-->>CI: v2 Active
alt Issue detected
K8s->>CI: Execute rollback
CI->>K8s: Restore v1
K8s->>App: Start v1 pods
App-->>K8s: v1 restored
K8s-->>CI: Rollback complete
CI-->>Dev: Rollback successful
else Successful deployment
App->>ES: Remove old v1 index
ES-->>App: Cleanup complete
K8s-->>CI: Deployment complete
CI-->>Dev: v2 deployed successfully
end
Implementation Details
Version Configuration
First thing, add a version setting to your config:
app:
search:
index-version: v1
hibernate:
search:
backend:
hosts: elasticsearch:9200
protocol: https
When you need schema changes, bump it to v2. We started with v1 but you could use whatever naming scheme works for you.
Custom Index Layout Strategy
The real trick here is getting Hibernate Search to automatically tack on the version to your index names. We had to write a custom IndexLayoutStrategy for this:
@Component
public class VersionedIndexLayoutStrategy implements IndexLayoutStrategy {
@Value("${app.search.index-version}")
private String indexVersion;
@Override
public String createInitialElasticsearchIndexName(String hibernateSearchIndexName) {
return hibernateSearchIndexName + "_" + indexVersion;
}
@Override
public String createWriteAlias(String hibernateSearchIndexName) {
return hibernateSearchIndexName + "_write_" + indexVersion;
}
@Override
public String createReadAlias(String hibernateSearchIndexName) {
return hibernateSearchIndexName + "_read";
}
@Override
public String extractUniqueKeyFromHibernateSearchIndexName(String hibernateSearchIndexName) {
return hibernateSearchIndexName + "_" + indexVersion;
}
@Override
public String extractUniqueKeyFromElasticsearchIndexName(String elasticsearchIndexName) {
return elasticsearchIndexName;
}
}
Hibernate Search Configuration
Hook this into your Hibernate Search config:
@Configuration
public class ElasticsearchConfig {
@Autowired
private VersionedIndexLayoutStrategy versionedIndexLayoutStrategy;
@Bean
public HibernateSearchElasticsearchConfigurer hibernateSearchConfigurer() {
return context -> {
ElasticsearchBackendConfiguration backendConfig = context.backend();
backendConfig.layout().strategy(versionedIndexLayoutStrategy);
};
}
}
Handling Pod Coordination
Here's where it gets interesting. During rolling deployments, you might have multiple new pods spinning up. You really don't want each one trying to build the same index. That's just wasteful and can cause weird race conditions.
We figured out a way to use Elasticsearch's _meta field as a coordination mechanism. Basically the first pod to start building marks the index as "already built" and the others skip it.
@Service
public class IndexBuildService {
@Autowired
private SearchSession searchSession;
@Autowired
private ElasticsearchClient elasticsearchClient;
@Value("${app.search.index-version}")
private String indexVersion;
private static final Logger log = LoggerFactory.getLogger(IndexBuildService.class);
@EventListener
public void onContextRefresh(ContextRefreshedEvent event) {
buildIndexIfNeeded();
}
private void buildIndexIfNeeded() {
String indexName = "products_" + indexVersion;
try {
if (isIndexAlreadyBuilt(indexName)) {
log.info("Index {} already built, skipping", indexName);
return;
}
log.info("Building index {} - this takes a few minutes", indexName);
searchSession.massIndexer(Product.class)
.purgeAllOnStart(true)
.typesToIndexInParallel(1)
.batchSizeToLoadObjects(100)
.threadsToLoadObjects(4)
.idFetchSize(1000)
.startAndWait();
markIndexAsBuilt(indexName);
log.info("Done building index {}", indexName);
} catch (Exception e) {
log.error("Index build failed for {}: {}", indexName, e.getMessage());
throw new RuntimeException("Index build failed", e);
}
}
private boolean isIndexAlreadyBuilt(String indexName) {
try {
boolean exists = elasticsearchClient.indices().exists(
ExistsRequest.of(e -> e.index(indexName))
).value();
if (!exists) {
return false;
}
var mappingResponse = elasticsearchClient.indices().getMapping(
GetMappingRequest.of(g -> g.index(indexName))
);
var mapping = mappingResponse.result().get(indexName);
if (mapping != null && mapping.mappings() != null) {
var meta = mapping.mappings().meta();
if (meta != null && meta.containsKey("index_built")) {
return "true".equals(meta.get("index_built").toString());
}
}
return false;
} catch (Exception e) {
log.warn("Couldn't check build status for {}: {}", indexName, e.getMessage());
// When in doubt, assume it's not built and let this pod try
return false;
}
}
private void markIndexAsBuilt(String indexName) {
try {
Map<String, JsonData> metaData = Map.of(
"index_built", JsonData.of("true"),
"built_at", JsonData.of(Instant.now().toString())
);
elasticsearchClient.indices().putMapping(PutMappingRequest.of(p -> p
.index(indexName)
.meta(metaData)
));
log.info("Marked {} as built", indexName);
} catch (Exception e) {
log.error("Failed to mark index as built: {}", e.getMessage());
}
}
}
Entity Classes Remain Unchanged
Your entity classes stay exactly the same:
@Entity
@Indexed(index = "products")
public class Product {
@Id
@DocumentId
private Long id;
@FullTextField(analyzer = "standard")
private String name;
@FullTextField(analyzer = "keyword") // Added this field in v2
private String category;
@KeywordField
private String status;
// getters/setters...
}
Search Service Also Stays Simple
Your search logic doesn't need to know about versioning:
@Service
public class ProductSearchService {
@Autowired
private SearchSession searchSession;
public List<Product> searchProducts(String query) {
return searchSession.search(Product.class)
.where(f -> f.bool()
.should(f.match().field("name").matching(query))
.should(f.match().field("category").matching(query)))
.fetchHits(20);
}
}
The IndexLayoutStrategy handles routing to the right versioned index automatically.
Lessons Learned
Index Building Takes Time
For our ~200k documents index, indexing usually takes 5-6 minutes.
Memory Is Important
Mass indexing uses a lot of memory. Ensure you have enough.
Cleanup Is Still Manual
Old indices just sit there until you decide to delete them, assuming you're confident there's no need for a rollback.
Rollbacks Work Well
If you need to rollback a deployment, the old pods come back up and use their original index. Works smoothly.
Our Deployment Process
Our process isn't anything fancy:
- Bump the version number in the config file and make schema changes
- Test on dev and pre-prod environments
- Watch startup logs to ensure the index builds properly
- Run test queries to verify search functionality
- Clean up old indices
Why This Approach Works for Us
The biggest win is not having to think about it much. Once it's set up, deployments just work. No coordination between services, no background processes to monitor, no complex rollback procedures when something goes sideways.
Storage costs a bit more since you have duplicate indices sitting around temporarily, but dealing with a complex deployment system would cost us way more in engineering time. Plus our Elasticsearch cluster has plenty of space anyway.
Alternatives We Considered
Blue-green deployments came up in our research, but running duplicate environments just for search deployments seemed excessive.
The reindex API seemed promising at first, but when we tested it with our full dataset it was taking forever. Maybe it would work for smaller indices, but not practical for our use case.
Alias switching with background reindexing looked clever in theory, but the error handling got complicated fast. What happens if the reindex fails halfway through? What if the new mapping is incompatible? Too many edge cases.
Final Thoughts
This approach has been working for us for about 8 months now. It's not the most elegant solution. You end up with temporary duplicate indices and manual cleanup, but it's reliable and easy to understand.
The key insight for us was realising that simple solutions are often better than clever ones. Instead of fighting against how Kubernetes rolling deployments work, we designed something that works with them naturally.
Your situation might be different. If you have massive indices or really tight storage constraints, this approach might not work. But for most apps, the simplicity is worth the extra storage cost.
If you're dealing with similar problems, give this a try. The code isn't too complex, and once it's working, you can mostly forget about it.
[story continues]
tags