
Table of Links
2 Related Work
2.1 Neural Codec Language Models and 2.2 Non-autoregressive Models
2.3 Diffusion Models and 2.4 Zero-shot Voice Cloning
3 Hierspeech++ and 3.1 Speech Representations
3.2 Hierarchical Speech Synthesizer
4 Speech Synthesis Tasks
4.1 Voice Conversion and 4.2 Text-to-Speech
5 Experiment and Result, and Dataset
5.2 Preprocessing and 5.3 Training
5.6 Zero-shot Voice Conversion
5.7 High-diversity but High-fidelity Speech Synthesis
5.9 Zero-shot Text-to-Speech with 1s Prompt
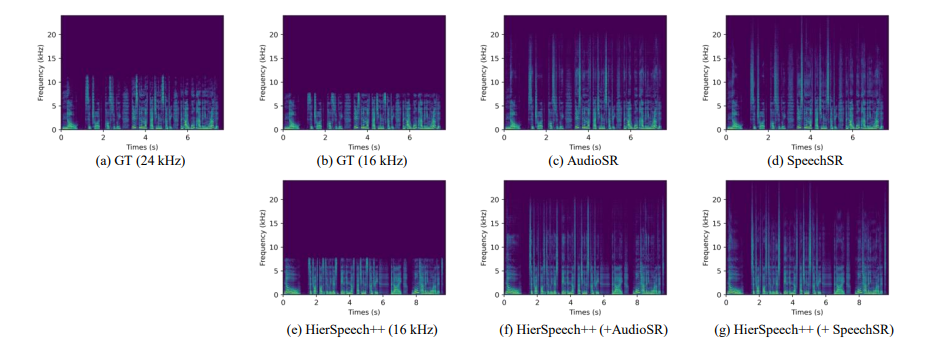
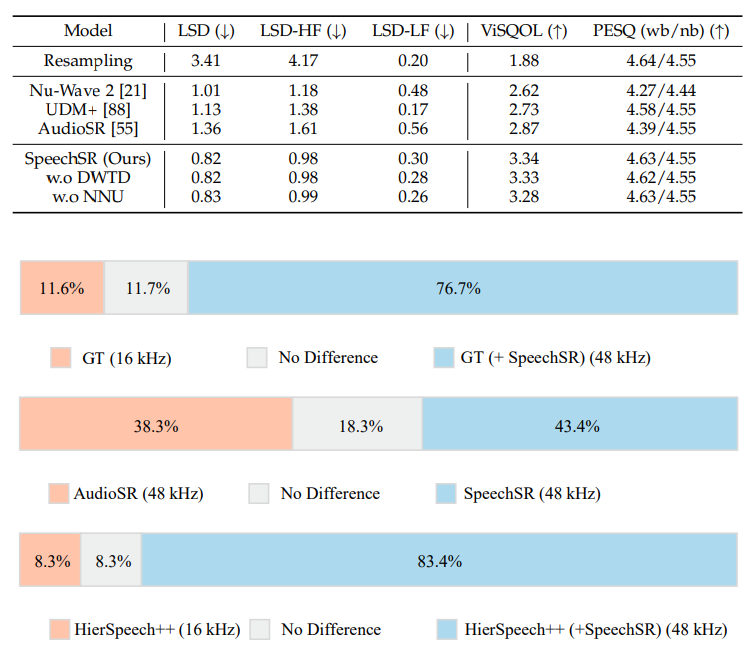
5.11 Additional Experiments with Other Baselines
7 Conclusion, Acknowledgement and References
5.9 Zero-shot Text-to-Speech with 1s Prompt
We compare the performance of zero-shot TTS according to different prompt lengths of 1s, 3s 5s, and 10s. For evaluation, we use all samples over 10s from the test-clean subset of LibriTTS (1,002 samples), and we randomly slice a speech for each prompt length. TABLE 9 shows that our model has a robust style transfer performance using 3s, 5s, and 10s prompts. However, using 1s prompt could not synthesize a speech well. We can discuss two problems: 1) we do not consider an unvoice part during slicing the speech so some prompts contain only a small portion of speech in their prompt, and we also found that there is no voice part in prompts. 2) we utilize a full-length of prompt during training so synthesizing long sentences may require a long speech prompt for robust speech synthesis, specifically in the prosody encoder. To reduce this problem, we propose a style prompt replication as in section 4.3, and this style prompt replication significantly improves the robustness of TTS. By replicating the prompt like DNA replication, we simply extend a style prompt by n× and the replicated prompt is fed to the style encoder. This simple trick for style transfer significantly improves the robustness and similarity. With HierSpeech++ using SPR, we could synthesize a speech with only 1s speech prompt even in a zero-shot TTS scenario.
This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.
Authors:
(1) Sang-Hoon Lee, Fellow, IEEE with the Department of Artificial Intelligence, Korea University, Seoul 02841, South Korea;
(2) Ha-Yeong Choi, Fellow, IEEE with the Department of Artificial Intelligence, Korea University, Seoul 02841, South Korea;
(3) Seung-Bin Kim, Fellow, IEEE with the Department of Artificial Intelligence, Korea University, Seoul 02841, South Korea;
(4) Seong-Whan Lee, Fellow, IEEE with the Department of Artificial Intelligence, Korea University, Seoul 02841, South Korea and a Corresponding author.
[story continues]
tags